efficient dynamic怎么设置(EfficientNet通过AutoML模型缩放提高准确效率)
卷积神经网络(CNN)通常是在固定资源成本下开发的,然后进行扩展以在提供更多资源时实现更高的准确性,从而使Google AI卷积神经网络(CNN)得以发布。 。例如,通过增加层数,可以将ResNet从ResNet-18扩展到ResNet-200,最近,GPipe获得了84.3%的ImageNet通过将基准CNN放大四倍来实现top-1精度。模型缩放的常规做法是任意增加CNN的深度或宽度,或使用较大的输入图像分辨率进行训练和评估。尽管这些方法确实提高了准确性,但它们通常需要繁琐的手动调整,并且仍然经常会产生次优的性能。相反,如果Google可以找到一种更原则化的方法来放大CNN以获得更好的准确性和效率呢?
在Google的ICML 2019论文“ EfficientNet:重新思考卷积神经网络的模型缩放”中,Google提出了一种新颖的模型缩放方法,该方法使用了简单而高效的复合系数以更结构化的方式扩展CNN。与传统方法任意缩放网络尺寸(例如宽度,深度和分辨率)不同,Google的方法使用一组固定的缩放系数来统一缩放每个尺寸。在这种新颖的缩放方法和AutoML的最新进展的支持下,Google开发了一系列模型,称为EfficientNets,该模型以超过10倍的更好效率(更小和更快)超越了最先进的精度。
复合模型缩放:放大CNN的更好方法为了了解扩展网络的影响,Google系统地研究了扩展模型的不同维度的影响。虽然缩放单个维度可以提高模型性能,但Google发现平衡网络的所有维度(宽度,深度和图像分辨率)与可用资源相比,可以最好地改善整体性能。
复合缩放方法的第一步是执行网格搜索,以找到在固定资源约束(例如,两倍多的FLOPS)下基准网络的不同缩放维度之间的关系。)。这将确定上述每个尺寸的适当缩放系数。然后,Google应用这些系数将基准网络扩大到所需的目标模型大小或计算预算。
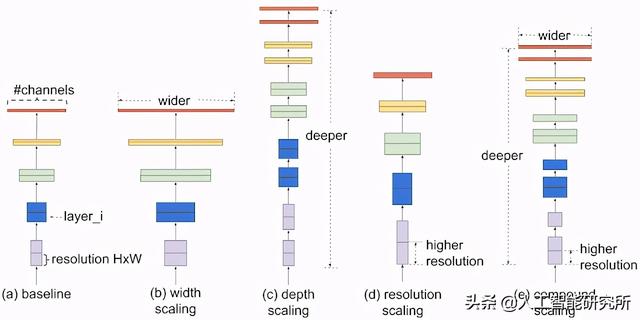
比较不同缩放方法。与常规缩放方法(b)-(d)任意缩放网络的单个维度不同,Google的复合缩放方法以一种有原则的方式均匀地缩放所有维度。
与传统的缩放方法相比,此复合缩放方法始终如一地提高了模型的准确性和效率,可用于扩展现有模型,例如MobileNet( 1.4%图像网络精度)和ResNet( 0.7%)。
高效网络架构模型缩放的有效性也严重依赖于基线网络。因此,为了进一步提高性能,Google还通过使用AutoML MNAS框架执行神经体系结构搜索来开发了新的基准网络,该框架优化了准确性和效率(FLOPS)。生成的体系结构使用了移动反向瓶颈卷积(MBConv),类似于MobileNetV2和MnasNet,但是由于增加了FLOP预算而略大。然后,Google扩大基准网络,以获得称为EfficientNets的一系列模型。

Google的基准网络EfficientNet-B0的体系结构简洁明了,因此更易于扩展和推广。
EfficientNet性能Google已经将EfficientNets与ImageNet上的其他现有CNN进行了比较。通常,与现有的CNN相比,EfficientNet模型可实现更高的准确性和更高的效率,从而将参数大小和FLOPS减小了一个数量级。例如,在高精度系统中,Google的EfficientNet-B7在ImageNet上达到了最先进的84.4%top-1 / 97.1%top-5精度,而与CPU推理相比,它的体积要小8.4倍,速度要快6.1倍以前的Gpipe。与广泛使用的ResNet-50相比,Google的EfficientNet-B4使用类似的FLOPS,同时将top-1的准确性从ResNet-50的76.3%提高到82.6%( 6.3%)。

型号尺寸与精度比较。EfficientNet-B0是AutoML MNAS开发的基准网络,而Efficient-B1至B7是通过扩大基准网络而获得的。特别是,Google的EfficientNet-B7达到了新的最先进的84.4%top-1 / 97.1%top-5精度,同时比现有的最佳CNN缩小了8.4倍。
尽管EfficientNets在ImageNet上表现良好,但要发挥最大作用,它们还应该转移到其他数据集。为了对此进行评估,Google在八个广泛使用的转移学习数据集上测试了EfficientNets。EfficientNets在8个数据集中的5个数据集中,例如CIFAR-100(91.7%)和Flowers(98.8%)中的5个达到了最先进的精度,参数减少了一个数量级(最多减少了21倍的参数减少),这表明Google的EfficientNets也可以很好地转移。
通过对模型效率进行重大改进,Google期望EfficientNets可以作为将来计算机视觉任务的新基础。因此,Google开放了所有EfficientNet模型的源代码,希望对大型机器学习社区有利。您可以在此处找到EfficientNet源代码和TPU培训脚本。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






