python关于验证码识别的库(PaddleOCR库识别防疫健康码文本信息)
最近看到复旦大学信息科学与工程学院博士生利用Python OCR和正则表达式开发一段代码可以快速的核查几百人的核酸结果。OCR光学字符识别软件开发时基本都是调用的别人的OCR文字识别服务。根据经验OCR的识别有一定的难度最少对图片的清晰度是有要求。心想Python的OCR文本识别库已经发展的这么高精准了么?耳听为虚动手为实开始写代码。今天就为大家介绍下利用Python OCR库识别防疫健康码截图的文本信息。
1、安装OCR库
#这次装了不少的库主要是库之间有依赖
pip3 install common dual tight data prox shapely paddle paddleocr paddlepaddle
2、文本识别
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
ocr = PaddleOCR(use_angle_cls=True, lang='ch')
img_path = '/Users/linux/Downloads/WechatIMG1.jpeg'
result = ocr.ocr(img_path, cls=True)
city_exist = False
for text in result:
exist = False
#print(text[1][0])
if text[1][0].find("动态行程卡") > -1:
exist = True
elif text[1][0].find('更新于') > -1:
exist = True
elif text[1][0].find('14天内到达') > -1:
city_exist = True
elif text[1][0].find("结果包含") > -1:
city_exist = False
if exist == True or city_exist == True:
print(text[1][0])
if text[1][0].find("绿色行程卡") > -1:
print("绿色")
elif text[1][0].find("红色行程卡") > -1:
print("红色")
3、健康码识别结果

(图一)
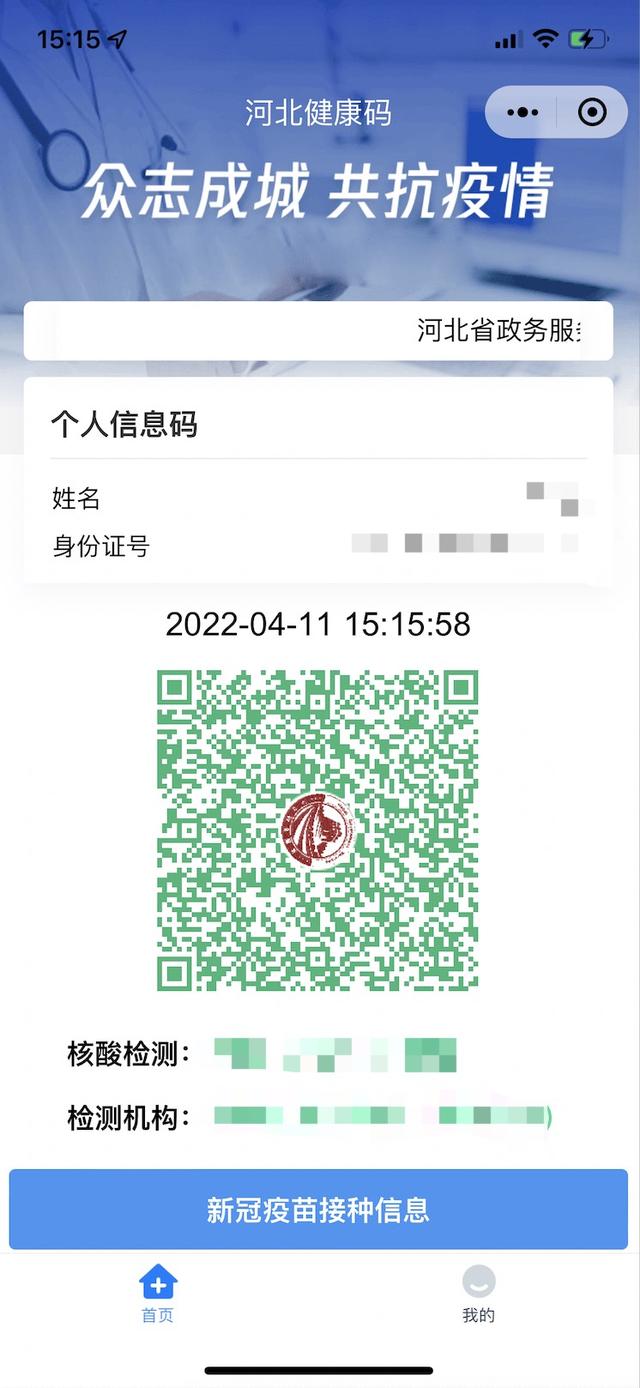
(图二)

(图三)
|
小程序 |
健康码截图 |
识别结果 |
|
通信行程卡 |
(如上图一) |
绿色
xxx****xxxx的动态行程卡 更新于:2022.04.1115:15:42 您于前14天内到达或途经:河北省xxxx市 |
|
北京健康宝 |
(如上图三) |
2022年04月11日 15:17:54 未见异常① 名: 姓 x* 身份证号: 查询时间: 04-1115:17 失效时间: 04-1124:00 |
|
河北健康码 |
(如上图二) |
河北健康码 姓名 x*x 身份证号 xxxx**********xxxx 2022-04-1115:15:58 核酸检测:阴性(2021-11-26 检测机构:北京xxxx医院(西城院区) |
4、颜色识别
代码中我们是根据识别的文本来判断是绿码还是红码,难免根据小程序的升级判断结果有误。希望可以根据截图的图片的主要颜色来判断绿码还是红码保险准确些。
import colorsys
import PIL.Image as Image
def get_dominant_color(image):
max_score = 0.0001
dominant_color = None
for count,(r,g,b) in image.getcolors(image.size[0]*image.size[1]):
# 转为HSV标准
saturation = colorsys.rgb_to_hsv(r/255.0, g/255.0, b/255.0)[1]
y = min(abs(r*2104 g*4130 b*802 4096 131072)>>13,235)
y = (y-16.0)/(235-16)
#忽略高亮色
if y > 0.9:
continue
score = (saturation 0.1)*count
if score > max_score:
max_score = score
dominant_color = (r,g,b)
return dominant_color
if __name__ == '__main__':
image = Image.open('/Users/linux/Downloads/WechatIMG1.jpeg')
image = image.convert('RGB')
print(get_dominant_color(image))
执行结果:
(83, 164, 108)[RGB绿色]
5、结论
根据我们识别通信行程卡、北京健康宝、河北健康码的截图。整体OCR的识别还是很准确的。基本上重要的我们想要的数据都可以识别出来,以后可以多用PaddleOCR库识别图片。大家有什么不同的观点可以提出来沟通讨论。
感谢大家的评论、点赞、分享、关注。。。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






