python爬虫进程和线程(python爬虫多进程python单线程实现协程)
最近golang写得多,但是采集数据还是习惯性地切换到了python。
业务需求- 采集gif图片和文字(非商业使用)
- 图片去除老水印,打上新水印
- 生成链接入库
1.采集
刚开始调试、测试使用的单线程,经过2个小时,终于跑通了。觉得数据量不大,跑跑一两个小时也采集完了,实际并没有。超时中断了很多次,又不得不做补偿措施。前后又折腾了俩小时才跑了一小半的数据,没跑下来的都是异常的。脑子木了。
因为要处理水印,忍住没切换到go。
接下来一个小时不到,采用python multiprocessing
爬虫技术:
import urllib3 as urllib
from bs4 import BeautifulSoup
from urllib.parse import urlencode, urlparse
import multiprocessing
本机:Mac m1, conda env python3.10
采集效率比对:
单线程 444s - 丢失数据,做补偿措施也只跑了不到2/3
多进程 172s - 100%
def scrawl():
t1 = time.time()
pools = multiprocessing.Pool(8)
missingWords = pools.imap(parsingWord, wordsLeft)
pools.close()
pools.join()
t2 = time.time()
print("耗时:", t2 - t1)
技术细节忽略,自我总结:容易被问题套住,跳不出思维怪圈。
2.图片清洗
接上一篇文章:python pillow-GIF 去除水印并压缩
因为gif处理流程相对复杂一点,准备在单线程基础上增加协程并行处理能力。
记录:
单线程:处理一张gif 耗时26s,优化业务处理流程后16s多。
协程:80张gif图片-20多分钟
19:29因为是单线程发生了IO阻塞,如果时间上不着急,按队列去理解,是可以接受的
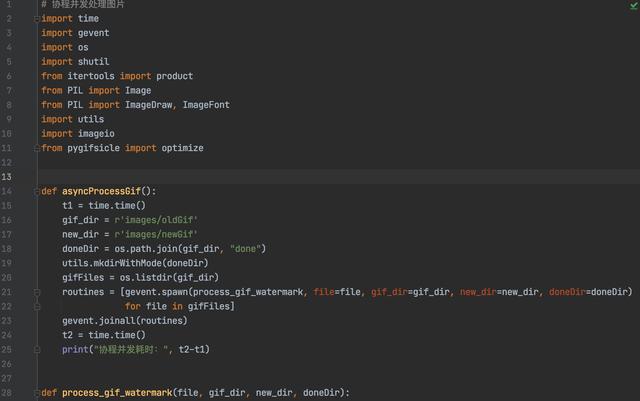

8CPU也没快多少,内存消耗减少了,cpu呼呼转跟风扇似的

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






