fifa世界杯全部赛程(先用深度学习与强化学习踢场)
本文作者是切尔西足球俱乐部粉丝,他写了一篇英文博客介绍如何使智能体在 FIFA 18 游戏中更加完美地踢任意球,共分为两部分:用神经网络监督式地玩 FIFA 18;用强化学习 Q 学习玩 FIFA 18。
玩 FIFA 游戏的机制
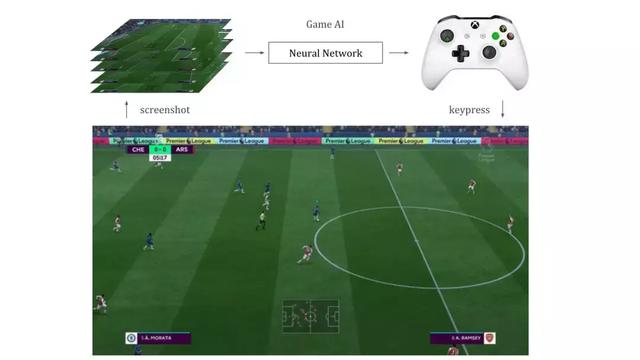
构建能玩 FIFA 游戏的智能体与游戏内置的 Bot 是不一样的,它不能访问任何内部程序信息,只能与人一样获得屏幕的输出信息。游戏窗口截图就是所有需要馈送到智能体游戏引擎的数据,智能体会处理这些视觉信息并输出它希望采取的动作,最后这些动作通过按键模拟器传递到游戏中。
下面我们提供了一个基本的框架为智能体提供输入信息,并使其输出控制游戏。因此,我们要考虑的就是如何学习游戏智能体。本文主要介绍了两种方法,首先是以深度神经网络和有监督的方式构建智能体,包括使用卷积神经网络理解截图信息和长短期记忆网络预测动作序列。其次,我们将通过深度 Q 学习以强化学习的方式训练一个强大的智能体。这两种方式的实现方法都已经开源:
- 基于深度有监督的智能体:https://github.com/ChintanTrivedi/DeepGamingAI_FIFA
- 基于强化学习的智能体:https://github.com/ChintanTrivedi/DeepGamingAI_FIFARL
基于监督学习的智能体
步骤 1:训练卷积神经网络(CNN)
CNN 因其高度准确地对图像进行目标检测的能力而出名。再加上有快速计算的 GPU 和高效的网络架构,我们可以构建能实时运行的 CNN 模型。
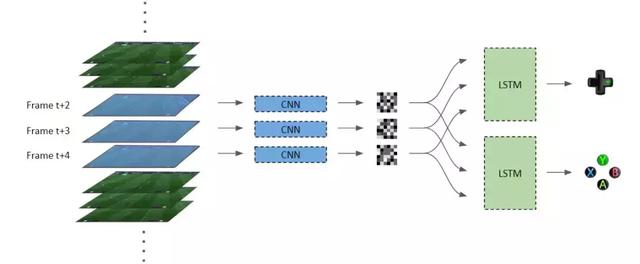
为了令智能体能理解输入图像,我们使用了一个非常紧凑的轻量级卷积网络,即 MobileNet。该网络抽取的特征图表征了智能体对图像的高级语义理解,例如理解球员和其它目标在图像中的位置。特征图随后会与单次多目标检测器一起检测球场上的球员、球与球门。
步骤 2:训练长短期记忆网络(LSTM)
现在理解了图像之后,我们继续来决定下一步的行动。然而,我们并不想仅看完一个帧的图像就采取动作。我们首先需要观察这些图像的短序列。这正是 LSTM 发挥作用的地方,LSTM 就是因其对时序数据的优越建模能力而出名的。连续的图像帧在序列中作为时间步,每个帧使用 CNN 模型来提取特征图。然后这些特征图被同时馈送到两个 LSTM 网络。
第一个 LSTM 执行的是决定玩家移动方式的学习任务。因此,这是一个多类别分类模型。第二个 LSTM 得到相同的输入,并决定采取交叉、过人、传球还是射门的动作,是另一个多类别分类模型。然后这两个分类问题的输出被转换为按键动作,来控制游戏中的动作。
这些网络已经在手动玩游戏并记录输入图像和目标按键动作而收集的数据上训练过了。这是少数几个收集标记数据不会那么枯燥的任务类型之一。
基于强化学习的智能体
在前一部分中,我介绍了一个经过训练的人工智能机器人,它使用监督学习技术来玩 FIFA 游戏。通过这种方式,机器人很快就学会了传球和射门等基本动作。然而,收集进一步改进所需的训练数据变得很麻烦,改进之路举步维艰,费时费力。出于这个原因,我决定改用强化学习。
这部分我将简要介绍什么是强化学习,以及如何将它应用到这个游戏中。实现这一点的一大挑战是,我们无法访问游戏的代码,所以只能利用我们在游戏屏幕上所看到的内容。因此,我无法在整个游戏中对智能体进行训练,但可以在练习模式下找到一种应对方案来让智能体玩转技能游戏。在本教程中,我将尝试教机器人在 30 码处踢任意球,你也可以通过修改让它玩其他的技能游戏。让我们先了解强化学习技术,以及如何制定适合这项技术的任意球问题解决方案。
强化学习(以及深度 Q 学习)是什么?
与监督学习相反,强化学习不需要手动标注训练数据。而是与环境互动,观察互动的结果。多次重复这个过程,获得积极和消极经验作为训练数据。因此,我们通过实验而不是模仿来学习。
假设我们的环境处于一个特定的状态 s,当采取动作 a 时,它会变为状态 s'。对于这个特定的动作,你在环境中观察到的即时奖励是 r。这个动作之后的任何一组动作都有自己的即时奖励,直到你因为积极或消极经验而停止互动。这些叫做未来奖励。因此,对于当前状态 s,我们将尝试从所有可能的动作中估计哪一个动作将带来最大的即时 未来奖励,表示为 Q(s,a),即 Q 函数。由此得到 Q(s,a) = r γ * Q(s', a'),表示在 s 状态下采取动作 a 的预期最终奖励。由于预测未来具有不确定性,因此此处引入折扣因子 γ,我们更倾向于相信现在而不是未来。
图源:http://people.csail.mit.edu/hongzi/content/publications/DeepRM-HotNets16.pdf
深度 Q 学习是一种特殊的强化学习技术,Q 函数是通过深度神经网络学习的。给定环境的状态作为这个网络的图像输入,它试图预测所有可能动作的预期最终奖励,像回归问题一样。选择具有最大预测 Q 值的动作作为我们在环境中要采取的动作。该技术因此得名「深度 Q 学习」。
将 FIFA 任意球定位为 Q 学习问题
- 状态:通过 MobileNet CNN 处理的游戏截图,给出了 128 维的扁平特征图。
- 动作:四种可能的动作,分别是 shoot_low、shoot_high、move_left、move_right.
- 奖励:如果按下射门,比赛成绩增加 200 分以上,我们就进了一个球,r= 1。如果球没进,比分保持不变,r=-1。最后,对于与向左或向右移动相关的动作,r=0。
- 策略:两层密集网络,以特征图为输入,预测所有 4 个动作的最终奖励。
智能体与游戏环境交互的强化学习过程。Q 学习模型是这一过程的核心,负责预测智能体可能采取的所有动作的未来奖励。该模型在整个过程中不断得到训练和更新。
注意:如果我们在 FIFA 的开球模式中有一个和练习模式中一样的性能表(performance meter),那么我们可能就可以将整个游戏作为 Q 学习问题,而不仅仅局限于任意球。或者我们需要访问我们没有的游戏内部代码。不管怎样,我们应该充分利用现有的资源。
代码实现
我们将使用 Tensorflow (Keras) 等深度学习工具在 Python 中完成实现过程。
GitHub 地址:https://github.com/ChintanTrivedi/DeepGamingAI_FIFARL
,





免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






