orc 不限制次数(别在CDH5中使用ORC好吗)
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
Fayson的github:
https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1
问题重现
当我们在使用ORC文件格式创建hive表,并且对Hive表的schema进行更改后,然后进行如insert into…select或insert overwrite … select会报错,以下具体看看报错。
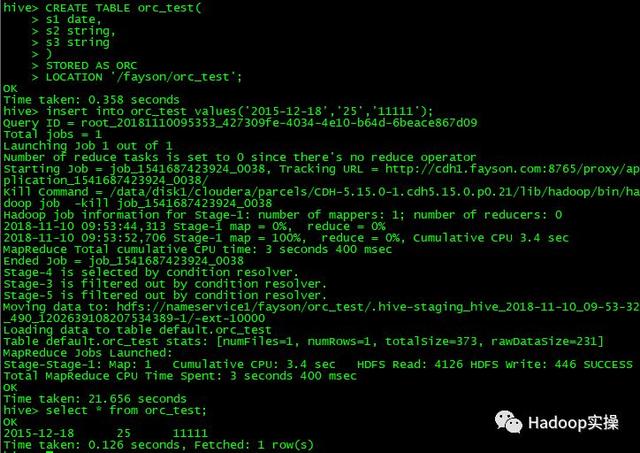
1.首先我们创建一张ORC格式的Hive表,从插入一行数据。
CREATE TABLE orc_test( s1 date, s2 string, s3 string ) STORED AS ORC LOCATION '/fayson/orc_test'; insert into orc_test values('2015-12-18','25','11111'); select * from orc_test;
(可左右滑动)
2.我们先使用alter命令增加一列到该表,然后对该表进行insert操作。
ALTER TABLE orc_test ADD COLUMNS (testing string); INSERT overwrite table orc_test SELECT * FROM orc_test; INSERT into table orc_test SELECT * FROM orc_test;
(可左右滑动)
3.发现无论是insert还是insert overwrite都会报错,如下。
----- Diagnostic Messages for this Task: Error: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:179) at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54) at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.process(VectorMapOperator.java:52) at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:170) ... 8 more Caused by: java.lang.NullPointerException at java.lang.System.arraycopy(Native Method) at org.apache.hadoop.io.Text.set(Text.java:225) at org.apache.hadoop.hive.ql.exec.vector.expressions.VectorExpressionWriterFactory$6.writeValue(VectorExpressionWriterFactory.java:686) at org.apache.hadoop.hive.ql.exec.vector.expressions.VectorExpressionWriterFactory$VectorExpressionWriterBytes.writeValue(VectorExpressionWriterFactory.java:272) at org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator.getRowObject(VectorFileSinkOperator.java:89) at org.apache.hadoop.hive.ql.exec.vector.VectorFileSinkOperator.processOp(VectorFileSinkOperator.java:76) at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815) at org.apache.hadoop.hive.ql.exec.vector.VectorSelectOperator.processOp(VectorSelectOperator.java:138) at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815) at org.apache.hadoop.hive.ql.exec.TableScanOperator.processOp(TableScanOperator.java:98) at org.apache.hadoop.hive.ql.exec.MapOperator$MapOpCtx.forward(MapOperator.java:157) at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.process(VectorMapOperator.java:45) ... 9 more FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask MapReduce Jobs Launched: Stage-Stage-1: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL Total MapReduce CPU Time Spent: 0 msec
(可左右滑动)
其实这个异常主要是因为使用ORC格式的文件与Hive的矢量化特性不兼容导致的,本文Fayson会介绍会如何解决这个故障。
- 测试环境
1.CM和CDH版本为5.15.0
2.采用root用户操作
3.Hive1.1.0
2
问题解决
2.1方法1:禁用矢量化
1.禁用矢量化后,再次执行同样的insert语句。
set hive.vectorized.execution.enabled=false; INSERT overwrite table orc_test SELECT * FROM orc_test; INSERT into table orc_test SELECT * FROM orc_test;
(可左右滑动)
执行成功,没有报错。
2.2方法2:使用Parquet
1.我们drop掉这张表,同样的操作使用Parquet文件格式再次操作一遍。
CREATE TABLE orc_test( s1 string, s2 string, s3 string ) STORED AS parquet LOCATION '/fayson/orc_test'; insert into orc_test values('2015-12-18','25','11111'); ALTER TABLE orc_test ADD COLUMNS (testing string); INSERT overwrite table orc_test SELECT * FROM orc_test; INSERT into table orc_test SELECT * FROM orc_test;
(可左右滑动)
执行成功,没有报错。
3
总结
1.hive.vectorized.execution.enabled参数在CDH5的Hive中默认是开启的,矢量查询(Vectorized query) 每次处理数据时会将1024行数据组成一个batch进行处理,而不是一行一行进行处理,这样能够显著提高执行速度。
2.但当该参数开启后,会与ORC格式文件的Hive表冲突,也会导致本文第一章所描述的报错,该jira是在Hive2才修复的,所以要在CDH6中才会修复,具体参考一个非常大的jira包:
https://issues.apache.org/jira/browse/HIVE-11981
https://issues.apache.org/jira/browse/HIVE-16314
3.要解决该bug导致的问题,可以禁用矢量化查询的功能,即:set hive.vectorized.execution.enabled=false或者不要对于Hive表使用ORC格式,而是统一改为Parquet格式。
4.ORC文件格式的事务支持尚不完善,具体参考《
Hive事务管理避坑指南
》,所以在CDH中的Hive中使用ORC格式是不建议的,另外Cloudera Impala也不支持ORC格式,如果你在Hive中创建ORC格式的表,也没办法达到一份数据,多个计算引擎同时访问的目的。最后其实ORC格式是Hortonworks家的,Parquet才是Cloudera的,从两家产品竞争关系上讲,也不会互相支持。所以只要你还在玩CDH5,就别再折腾ORC了。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:如果使用电脑查看图片不清晰,可以使用手机打开文章单击文中的图片放大查看高清原图。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操
,






免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com