目前最强的gpu(国产GPGPU如何赶超国外)

演讲嘉宾 | 梁晓峣,上海交通大学计算机科学与工程系教授、副系主任
整理 | Carol
人工智能经过多年的技术积累,正在以智能算力芯片为载体而全面崛起。在这个赛道上,算法为天、算力为地,要想有所作为,必须要看在芯片核心阵地上的突破。
经过了这几年的发展,我国在智能算力芯片上已经形成了初步的格局,并推出了多款AI芯片产品。对于这些产品,我们可以从通用和专用两个角度去审视:
-
把芯片设计得更加专用一点,因为专用芯片在功耗和性能上有较大优势;
-
也可以选择设计得通用一点,以适应服务对象和场景的快速变化。
那么,智能算力芯片的架构的设计究竟应该是通用还是专用呢?这是一个很关键的问题。
梁晓峣,上海交通大学计算机科学与工程系教授、副系主任
点击查看完整演讲内容

通用or专用,智能算力芯片架构该如何设计?
常用芯片中最通用的就属CPU。以英特尔、AMD为代表,几乎可以做任何事情,但是无法做到极致的性能和功耗。能做到极致能效比的是专用芯片,既所谓的ASIC。但是它的编程性差,应用的范围就比较窄。
而在这两个极端之间还有很多选择,比如GPU,这些年越来越成为行业的热点。GPU是一个相对比较通用的处理器,现在称之为GPGPU,具有良好的编程性,特别适合大规模数据并行类应用。还有一类在硬件灵活度上更大的就是FPGA(现场可编程门阵列),这类器件可以通过硬件描述语言来改变逻辑结构,性能和功耗会更好,只是编程的难度较大。
通过分析过去五年具有代表性的芯片公司的股价走势,就可以对行业的发展趋势窥见一斑:英特尔近五年股价上涨了50%;Xilinx(全球领先的FPGA公司)股价大概上涨了2.6倍;而英伟达(当红的GPGPU垄断企业)过去五年股价上涨了16倍。我们即便不去追究深层次的原因,仅凭股价的成长也可以判断行业已经作出了选择,GPGPU已经成为未来计算的主角和核心。

同时,以史为鉴,从GPU的发展历史看,它是如何一步一步成长为行业王者的?
GPU早在上世纪八十年代就已经出现了,那时对于游戏的需求催生了特殊的专用于图形渲染的硬件,这就是早期的GPU。在1990年-2000年这段时间,涌现了很多GPU厂商,每家公司规模并不大,有很多代表性的专用芯片产品。但是到了2005年左右,大家意识到在图形学这个领域算法变化很快,可能每隔几个月甚至每隔几周就会发生翻天覆地的变化。但芯片需要18个月才能完成一次更迭,如果把硬件完全固定下来就无法跟上行业发展的节奏。
所以,人们开始探索把原来不可变的执行流水线,设计成可以部分编程的架构,这种架构更加灵活,可以更加高效的适应算法的变化。真正的GPGPU行业大发展始于2006年出现的CUDA(Compute Unified Device Architecture,统一计算设备架构),它是一种精心设计的、可对GPGPU直接编程的接口和语言。从此以后,对于大量的数据并行应用就可以方便地使用CUDA编程,从而释放出GPGPU中可观的算力。
所以回看过去几十年GPU的发展之路,是一条从“专用”过渡到“比较通用”,直到现在“非常通用”的发展路径。如果我们用来类比今天的人工智能,是否也有相同的趋势?AI需要极致的算力和能效比,做成专用芯片可能是合适的。但AI算法的变化又非常快,可能以“天”计,这又要求我们不能做成非常固定的硬件,可能最后也会收敛到一个偏通用的架构。这是我们的一个推论。

GPGPU的发展离不开“摩尔定律”
摩尔定律已经被“社死”了很多年,在很多年前就有人说摩尔定律要终结了,但这些年摩尔定律非但没有终结,而且还活得很好。
如今5纳米工艺可以量产,3纳米也没问题,1纳米也能够预见,摩尔定律仍然会持续下去,而且会持续相当长的时间。但确实,计算机不会变得更快。因为频率不会变得更高,所以CPU的性能总体趋于稳定。但计算机能够集成的计算资源和存储资源还是会不断翻倍,因为摩尔定律使得硬件集成度每隔18个月提升一倍。
摩尔定律和GPGPU可谓“佳偶天成”,数据并行是一种可扩展性最强的并行方式,只要有海量的数据并行性,同时芯片又能够按照摩尔定律不断堆砌硬件资源,GPGPU的性能就会不断提升。历史已经证明GPGPU的胜出归根结底是摩尔定律的功劳。

既然针对某个特定应用做到极致能效比的方式是专用芯片,那么专用芯片是否会比GPGPU更加有优势呢?
实际上GPGPU的架构也不是一成不变的,也会加入专用的单元用于处理专业的任务,从而使得GPGPU的发展与时俱进,它可以是专用和通用的结合体。比如Volta这一代的GPGPU,在流处理器里就把计算资源分成几块,既有计算整型数的单元也有强大的浮点数单元。
为了适应人工智能的发展,还特意加入了新的单元,叫Tensor Core,其实就是为AI量身定做的专用计算单元。所以,GPGPU的架构也在不断更新、不断地去适应新型应用所需要的底层算力。
如果说传统GPGPU的算力并行度是以一个数据点为基本的粒度,在这个规模上并行,那么到了Tensor Core就变成了以小矩阵块为基本粒度并行了,它在每一个周期都可以完成一个4×4矩阵相乘的结果,所以并行度和算力都高于传统GPGPU的设计。
这个概念还可以推而广之,比如说华为的昇腾AI处理器中的核心单元3D Cube,实际上就是一个矩阵计算的阵列块,而它的规模比Tensor Core还要大,是以16×16为单位来做矩阵计算的,因此它的粒度更大,并行度更高,并且做同样的矩阵计算平均下来功耗更低。但是基本单元块粒度过大的话,相对于程序来说控制就复杂,通用性和适用性就下降。所以各个公司都是尽量在功耗、性能以及并行的粒度和可编程性之间找到一个平衡点。
为了适应人工智能的发展,现代GPGPU还做了很多革新。比如引入了多样化的数制。人工智能的应用对计算精度的要求可以放宽,没有必要一定按照标准的浮点数规则去运算。英伟达最新的Ampere架构中就引入了新的数制TF32。之所以起名叫TF32,意思是用这个标准来做,最后训练出来的网络精度不会下降,但TF32只有19位,它的计算方式和标准的浮点数不同,也正因为把位宽减少了,所以性能可以显著提升。
此外,Ampere架构还采用结构化的稀疏。我们在神经网络中发现,很多节点的权重都接近于0,而和0计算是白白浪费算力,所以在Ampere架构中也考虑了结构化的稀疏,每进行四次计算就可以规定有两个是结构化的0,实践发现如果可以把网络训练成这样,那么在Ampere架构下运算起来就会得到两倍的性能提升。
所以说,GPGPU里面也会发生各种各样的优化,也在与时俱进。人工智能需要新型的计算芯片支持,大致可分为云端和终端。
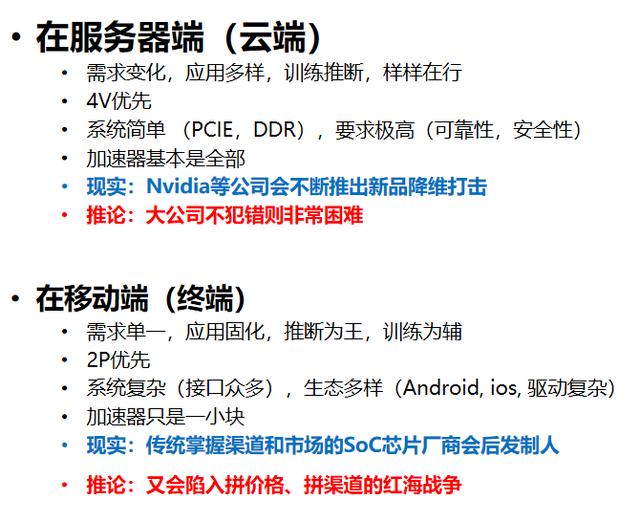
在云端要适应各种需求变化和应用,并且既要能做训练也要能做推理,所以看起来就是GPGPU的天下。英伟达这样的公司也在不断的进化,不断的推陈出新来保证产品的竞争力。
而在终端的需求相对比较单一,应用固定一些,所以理论上设计专用硬件来追求极致的能效比是合理的。但终端的问题是加速器永远只是一小部分,需要其他各种IP的配合协作才能组成一个完整的产品。比如说手机里面有丰富的功能,不是说只要人工智能做的好,手机就能卖得好。所以掌握传统渠道和市场的终端芯片厂商,也会推出自己的解决方案,很有可能会后发制人。
市场需要的不是“好”的芯片,而是“好用”的芯片
我们要感谢这个时代带给行业极大的发展机遇,甚至吸引了互联网巨头和海量的资本加入到这个战场。
此前,中国的互联网企业重视用户体验和商业模式,较少参与底层的硬件和芯片开发,但现在情况完全不同了。世界面临产业的大变革、大重组、大转移。而芯片产业的发展本质靠的是资本推动,当硬科技成为行业风口,就会产生大量的机会和变化。
这是一个非常好的时代,芯片产业总是由先进工艺推动的,我们可以乐观的预期未来推动先进工艺的未必是美国的英特尔或英伟达,或许可能是中国的某家高科技公司呢?但另一方面,我们也必须看到英伟达研发一款新品的投入是以十亿美金计,如果一个芯片公司的销售达不到这个规模,肯定是无法持续的。
当前海量的资本都疯狂的涌入这个赛道,而芯片是一个需要打持久战的行业,一旦收入无法跟上,或无法成长为某个赛道的头部,结局就可能很悲惨,即便是“飞起来的猪”也可能很快掉下来。
我们必须理解市场需要的不是“好”的芯片,而是“好用”的芯片。所谓好的芯片就是绝对算力高、硬件指标高,这个相对容易做到。但是做到好用就很困难,做出来的芯片没办法把潜力发挥出来,这是目前AI芯片公司的通病。
还是以史为鉴,英伟达其实也是一步一步从不好用做到好用,走过了一个漫长的阶段。早期的GPU是很不好用的,没有什么人会用GPU编程,只有那些所谓的“极客”会考虑使用GPU,拼命把其中的算力榨取出来。可以说早期的GPU比现在的AI芯片更不好用。
这时候就需要有一批行业领袖和技术大咖挺身而出,代表性的人物包括UIUC的胡文美教授(Wen-mei Hwu),他们发明了CUDA,从此有了可以直接对GPU进行编程的语言,使得GPU的潜力得以充分发挥,从而真正走上了腾飞之路。又经过十年左右的发展,形成了一个非常强大的生态,可以支持各种各样的应用,丰富了高级语言的属性,能够支持更为复杂的模型和算法,并且逐步在很多行业形成垄断。所以说GPGPU的发展不是一蹴而就的,是经过十多年的不懈奋斗才走到了今天。
Programming Massively Parallel Processors: A Hands-on Approach
由胡文美教授(Wen-mei Hwu)所著
发展国产自主GPGPU的三种可能性
当我们回过头来探索国产自主GPGPU的发展之路,首先就是要沉得住气,耐得下心,切不可急功近利、操之过急。事物的发展要遵循客观规律,资本永远是双刃剑,既可载舟亦可覆舟。
一款芯片的绝对算力有多高,集成了多少个晶体管并不重要,关键是把芯片的潜力充分释放给用户,这需要一个良好的生态和完整的软件栈,才能让用户乐于接受,不用改变太多的习惯就可以迅速移植现有的工作。讲起来容易,实际做起来很难,需要长期的努力,因为这世界上并不存在一个通用的办法或者一个通用架构就可以解决这个问题。
现在流行说“兼容CUDA”,但要真正兼容出效率很难。即便英伟达做GPGPU这么多年,其实也是由无数个专用的优化累积起来才能够看上去如此的通用,这其中凝聚着大量工程师多年的心血。我们从头做起也需要花费同样的代价,没有捷径可走,大家一定要意识到这个问题的复杂性和长期性。
在此,我们尝试探讨发展国产自主GPGPU的三种可能性:
第一条道路叫“农村包围城市”。策略是从专用芯片做起,把某一个小的领域做精做强,占据一个山头,然后再占第二个、第三个,形成一个个的革命根据地,逐渐实现农村包围城市。但也要防止各家企业在小的山头上恶性竞争乃至自相残杀,从而忘记了我们真正的历史使命和远大目标。经常发生的误区是:当一个企业爬上一座山顶的时候,只顾着欣赏眼前的风景而忘记了去征服更高的高山。
第二条道路来自“龟兔赛跑”的启发。在历史上小企业挑落行业巨头的案例也是屡有发生的,比如说,英特尔的指令集在桌面电脑上一家独大,但后来ARM能够成功挑战英特尔,就是抓住了移动互联网带来的历史机遇。英特尔在这个时候打盹了,并没有意识到行业发生的深刻变革(再加上幕后推手苹果公司的推波助澜)。当下人工智能时代带来的变革可能还要超越移动互联网,但令人吃惊的是在这个大变革的时代,实际上是兔子跑得比乌龟快。“兔子”就是英伟达,英伟达没有停下前进的步伐,没有犯当年英特尔的错误,至今还保持着当年初创企业的活力,很多行业突破性的技术是最先出现在英伟达的产品上。
兔子跑得快已经很棘手,而糟糕的是,我们作为后发者,国内的芯片人才本来就极为紧缺,但由于资本的驱动,短期内催生出很多芯片公司,据说今年新成立的芯片公司是去年的3倍,而培养的人才不可能一下子成长这么多。都说要集中优势兵力才能歼灭强敌,但现状是,我们把为数不多的兵力分散到多个战场,从而陷入越打越弱的怪圈。以史为鉴,只有当对手疏忽的时候,抓住战机毕其功于一役才有大的胜算,这往往需要有极大的战略定力,甚至还需要有些运气。在芯片行业,千万要防止一哄而上之后的一哄而散!
第三条道路也是目前我们认为最有机会的道路,就是开源。靠的是众人拾柴和愚公移山,要的是细水长流,拼的是“天荒地老”。通过开源战胜强大的对手,在软件生态方面已经战果累累,在硬件上也已经开始显示威力。我们有理由相信,开源硬件即便不能一统江湖,至少也可以分庭抗礼。
我们认为,现阶段国内完全有机会做一个开源开放的、免费公益的GPGPU项目,目的是打造一个全栈式的平台,提供开源硬件,编译器、算子库等,并且在指令集的设计上尽可能接近或者兼容CUDA生态圈。我们的研究团队最近攥写了一本关于GPGPU体系结构的专用教材,书名是《通用图形处理器设计—GPGPU编程模型和架构原理》,预计明年初正式出版发行。同时希望号召国内最大的程序员社区,大家携起手来,摒弃门户之见,都来支持国产自主GPGPU,尽快把这个生态做大做强。
通过这些方式,经过十年以上的努力,我们坚信在这一块的劣势会逐步得到弥补,逐渐缩小和国外巨头之间的差距。
,






免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






