python pandas 数据校验(Python数据分析五Pandas数据预处理)
合并数据
在实际工作中,我们的数据源往往是来自多个地方(比如分散在不同的表里),
具体分析的时候需要把相关联的数据信息整合在一张表里,可能会有如下操作:
横向或纵向堆叠合并数据
主键合并数据
重叠合并数据
我们可以使用 concat、append、merge、join、conbine_first 来实现上述需求
• 横向表堆叠
横向堆叠,即将两个表在 x 轴向拼接在一起,可以使用 concat 函数完成,基本语法如下:
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True)

• 横向表堆叠
当 axis=1 的时候,concat 做行对齐,然后将不同列名称的两张或多张表合并。当两个表索引不完
全一样时,可以使用 join 参数选择是内连接还是外连接。在内连接的情况下,仅仅返回索引重叠部
分。在外连接的情况下,则显示索引的并集部分数据,不足的地方则使用空值填补。
当两张表完全一样时,不论 join 参数取值是 inner 或者 outer,结果都是将两个表完全按照 X 轴拼
接起来。
• 纵向堆叠——concat函数
使用 concat 函数时,在默认情况下,即 axis=0 时,concat 做列对齐,将不同行索引的两张或多张表纵向合并。在两张表的列名并不完全相同的情况下,当 join 参数取值为 inner 时,返回的仅仅是列名交集所代表的列,取值为 outer 时,返回的是两者列名的并集所代表的列
不论 join 参数取值是 inner 或者 outer,结果都是将两个表完全按照 Y 轴拼接起来

• 纵向堆叠——append方法
DataFrame 的 append 方法也可以用于纵向合并两张表。但是 append 方法实现纵向表堆叠有一
个前提条件,那就是两张表的列名需要完全一致。基本语法如下:
df.append(self, other, ignore_index=False, verify_integrity=False)
常用参数:

• 主键合并
通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN。针对同一个主键存在两张包
含不同字段的表,将其根据某几个字段一一对应拼接起来,结果集列数为两个表的列数和再减去连接
键的数量。

• 主键合并——merge函数
和数据库的 join 一样,merge 函数也有左连接(left)、右连接(right)、内连接(inner)和外
连接(outer),但比起数据库 SQL 语言中的 join ,merge函数还有其自身独到之处,例如可以在
合并过程中对数据集中的数据进行排序,用法如下:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False,
right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False)

• 主键合并——join方法
DataFrame对象的 join 方法也可以实现主键合并的功能,但是 join 方法使用时,两个主键的名字
必须相同,用法如下:
df.join(self, other, on=None, how='left', lsuffix='', rsuffix='', sort=False)

• 重叠合并
数据分析和处理过程中偶尔会出现两份数据的内容几乎一致的情况,但是某些特征在其中一张表上是
完整的,而在另外一张表上的数据则是缺失的,可以用 DataFrame 对象的 combine_first 方法进行
重叠数据合并,其用法如下:

• 案例
堆叠不同时间的订单详情表
• 订单详情表 meal_order_detail1、meal_order_detail2、meal_order_detail3 具有相同的特征,但数据时
间不同,订单编号也不同,在数据分析过程中需要使用全量数据,需要将几张表做纵向堆叠操作
主键合并订单详情表、订单信息表和客户信息表
• 订单详情表、订单信息表和客户信息表两两之间存在相同意义的字段,因此需通过主键合并的方式将三张
表合并为一张宽表。
清洗数据
在实际工作中,我们拿到的数据基本不会是直接就能用的,里面包含了大量的重复数据、缺
失数据和异常数据。数据重复会导致数据的方差变小,数据分布发生较大变化。缺失会导致样本
信息减少,不仅增加了数据分析的难度,而且会导致数据分析的结果产生偏差。异常值则会产生
“伪回归”。
因此需要对数据进行检测,查询是否有重复值、缺失值和异常值,并且要对这些数据进行适
当的处理,即数据清洗。
• 检测与处理重复值
处理重复数据是数据分析经常面对的问题之一。对重复数据进行处理前,需要分析重复数据
产生的原因以及去除这部分数据后可能造成的不良影响。常见的数据重复分为两种:
记录重复,即一个或者多个特征的某几条记录的值完全相同
特征重复,即存在一个或者多个特征名称不同,但数据完全相同的情况
• 检测与处理重复值
记录重复
① 方法一是利用列表(list)去重,自定义去重函数:

② 方法二是利用集合(set)的元素是唯一的特性去重,如 dish_set = set(dishes)
比较上述两种方法可以发现,方法一代码冗长。方法二代码简单了许多,但会导致数据的排列发生改变。
检测与处理重复值
记录重复
Pandas 提供了一个名为 drop_duplicates 的去重方法。该方法只对 DataFrame 或
Series 类型有效。这种方法不会改变数据原始排列,并且兼具代码简洁和运行稳定的特点。
该方法不仅支持单一特征的数据去重,还能够依据 DataFrame 的其中一个或者几个特征
进行去重操作: df.drop_duplicates(self, subset=None, keep='first', inplace=False)

• 检测与处理重复值
特征重复
结合相关的数学和统计学知识,去除连续型特征重复可以利用特征间的相似度将两个相似度为1的
特征去除一个。在 Pandas 中相似度的计算方法为 corr ,使用该方法计算相似度时,默认为
“pearson”法 ,可以通过“method”参数调节,目前还支持“spearman”法和“kendall”法。
注:通过相似度矩阵去重存在一个弊端,该方法只能对数值型重复特征去重,类别型特征之间无法通过计算相似系
数来衡量相似度。
除了使用相似度矩阵进行特征去重之外,可以通过 DataFrame.equals 方法进行特征去重。
• 检测与处理缺失值
发现缺失值
数据中的某个或某些特征的值是不完整的,这些值称为缺失值。
pandas 提供了识别缺失值的方法 isnull 以及识别非缺失值的方法 notnull,这两种方法在使用时返
回的都是布尔值,即 True和False。
结合 sum 函数和 isnull、notnull 函isnull和notnull之间结果正好相反,因此使用其中任意一个都可
以判断出数据中缺失值的位置数,可以检测数据中缺失值的分布以及数据中一共含有多少缺失值
isnull 和 notnull 之间结果正好相反,因此使用其中任意一个都可以判断出数据中缺失值的位置
• 检测与处理缺失值
处理缺失值——删除法
删除法分为删除记录和删除特征两种,它属于利用减少样本量来换取信息完整度的一种方法,是一
种最简单的缺失值处理方法。
pandas中提供了简便的删除缺失值的方法 dropna ,该方法既可以删除记录,亦可以删除特征:
df.dropna(self, axis=0, how='any', thresh=None, subset=None, inplace=False)
• 检测与处理缺失值
处理缺失值——替换法
替换法是指用一个特定的值替换缺失值。
特征可分为数值型和类别型,两者出现缺失值时的处理方法也是不同的:
缺失值所在特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来代替缺失值
缺失值所在特征为类别型时,则选择使用众数来替换缺失值
• 检测与处理缺失值
处理缺失值——替换法
pandas 库中提供了缺失值替换的方法名为 fillna,其基本语法如下:
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
• 检测与处理缺失值
处理缺失值——插值法
删除法简单易行,但是会引起数据结构变动,样本减少;替换法使用难度较低,但是会影响数据的标
准差,导致信息量变动。在面对数据缺失问题时,除了这两种方法之外,还有一种常用的方法—插值
法。
常用的插值法有线性插值、多项式插值和样条插值等:
线性插值是一种较为简单的插值方法,它针对已知的值求出线性方程,通过求解线性方程得到缺失值。
多项式插值是利用已知的值拟合一个多项式,使得现有的数据满足这个多项式,再利用这个多项式求解缺失值,常见的多
项式插值法有拉格朗日插值和牛顿插值等。
样条插值是以可变样条来作出一条经过一系列点的光滑曲线的插值方法,插值样条由一些多项式组成,每一个多项式都是
由相邻两个数据点决定,这样可以保证两个相邻多项式及其导数在连接处连续。
• 检测与处理缺失值
处理缺失值——插值法
Pandas 库提供了 interpolate 方法实现上述插值 :
注意:依赖于 scipy 库,需要先安装:pip install scipy
也可以用 scipy 的方法来实现

• 检测与处理异常值
异常值是指数据中个别值的数值明显偏离其余的数值,有时也称为离群点,检测异常值就是
检验数据中是否有输入错误以及是否含有不合理的数据。如果计算分析过程的数据中有异常
值,那么会对结果产生不良影响,从而导致分析结果产生偏差乃至错误。
常用的异常值检测主要为:
3σ原则
箱线图分析
• 检测与处理异常值
3σ原则
3σ原则又称为拉依达法则。该法则就是先假设一组检测数据只含有
随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率
确定一个区间,认为误差超过这个区间的就属于异常值。
如右图,符合正态分布的数据集的数值分布几乎全部集中在区间
(μ-3σ,μ 3σ)内,其中σ 代表标准差,μ 代表均值,超出这个范围的
数据仅占不到0.3%。故根据小概率原理,可以认为超出3σ的部分数据
为异常数据。
注意:这种方法仅适用于对正态或近似正态分布的样本数据进行处理

• 检测与处理异常值
箱线图分析
箱型图提供了识别异常值的一个标准,即异常值通常
被定义为小于 QL-1.5 IQR 或大于 QU 1.5 IQR 的值
• QL 称为下四分位数,表示全部观察值中有四分之一的
数据取值比它小。
• QU 称为上四分位数,表示全部观察值中有四分之一的
数据取值比它大。
• IQR 称为四分位数间距,是上四分位数 QU 与下四分位
数 QL 之差,其间包含了全部观察值的一半。
标准化数据
我们在进行数据分析与挖掘时,样本的不同特征之间往往具有不同的量纲,由此所造成的数值
间的差异可能很大,在涉及空间距离计算或梯度下降法等情况时,不对其进行处理会影响到数
据分析结果的准确性。为了消除特征之间量纲和取值范围差异可能会造成的影响,需要对数据
进行标准化处理,也可以称作规范化处理。标准化处理有以下三种:
离差标准化
标准差标准化
小数定标标准化
• 离差标准化
离差标准化又叫 min-max 标准化,是对原始数据的一种线性变换(归一化),将原始
数据的数值映射到 [0,1] 区间
转换公式:
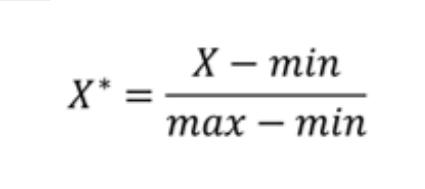
其中,max 为样本数据的最大值,min 为样本数据的最小值,max−min 为极差。离差标
准化保留了原始数据值之间的联系,是消除量纲和数据取值范围影响最简单的方法
• 标准差标准化
标准差标准化又叫零均值标准化,或者 z-score 标准化,是当前使用最广泛的数据标准
化方法。经过该方法处理后的数据均值为 0,标准差为 1。
转化公式:

其中, 为样本数据的均值, 为样本数据的标准差。标准差标准化后的值区间不局限于
[0,1],并且存在负值
• 小数定标标准化
通过移动数据的小数点位置,将数据映射到区间[-1,1],移动的小数位数取决于数据绝对
值的最大值。
转化公式:
例如:属性A的取值范围是 -800 到 70,那么就可以将数据的小数点整体向左移三位,即
[-0.8,0.07]
转化数据
• 类别型数据的处理
数据分析模型中有相当一部分的算法模型都要求输入的特征为数值型,但实际数据中,特征的类型不一定只有数值型,还会存在相当一部分的类别型,这部分的特征需要经过哑变量处理才可以放入模型之中,处理示例如下图:

• 类别型数据的处理
Pandas 库提供了 get_dummies 函数对类别型特征进行哑变量处理:
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None,
sparse=False, drop_first=False)
• 离散化连续型数据
某些模型算法,特别是某些分类算法如 ID3 决策树算法和 Apriori 算法等,要求数据是离散的,此时就需要将连续型特征(数值型)变换成离散型特征(类别型)。
连续特征的离散化就是在数据的取值范围内设定若干个离散的划分点,将取值范围划分为一些离散化的区间,最后用不同的符号或整数值代表落在每个子区间中的数据值。
常用的离散化方法主要有3种:等宽法、等频法和聚
类分析法(一维)

• 离散化连续型数据
等宽法
将数据的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定或者由用
户指定,与制作频率分布表类似。pandas 提供了 cut 函数,可以进行连续型数据的等
宽离散化,其基础语法格式如下:
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3,
include_lowest=False)
• 离散化连续型数据
等宽法
使用等宽法离散化的缺陷为:等宽法离散化对数据分布具有较高要求,若数据分布不
均匀,那么各个类的数目也会变得非常不均匀,有些区间包含许多数据,而另外一些
区间的数据极少,这会严重损坏所建立的模型。
• 离散化连续型数据
等频法
cut 函数虽然不能够直接实现等频离散化,但是可以通过定义将相同数量的记录放进
每个区间。
等频法离散化的方法相比较于等宽法离散化而言,避免了类分布不均匀的问题,但同
时却也有可能将数值非常接近的两个值分到不同的区间以满足每个区间中固定的数据
个数。
• 离散化连续型数据
聚类分析法
一维聚类的方法包括两个步骤:
首先将连续型数据用聚类算法(如K-Means算法等)进行聚类,
然后处理聚类得到的簇,为合并到一个簇的连续型数据做同一种标记。
聚类分析的离散化方法需要用户指定簇的个数,用来决定产生的区间数。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






