偏差方差的解法(一文了解什么方差偏差均衡)
“偏差-方差”是解释学习算法泛化性能的重要方式,我们时常通过方差、偏差的角度去理解一个模型,那么,到底什么是方差偏差均衡(bias variance trade off)?
一、定义偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声则表达了学习问题本省的难度。偏差-方差分解说明,泛化能力是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的,给定学习任务,为了取得好的泛化性能,需使偏差较小,即能够充分拟合数据,并使方差较小,使数据扰动产生的影响最小。
比如,要预测一个给定点的值,用n份有差异的数据集训练,训练了n个模型,结果这n个模型对该点的预测值的差异浮动很大,此时该模型的variance就偏高了。对应了下图中右2和右4。

我们训练模型的摸底是降低模型的泛化误差,variance强调了模型的泛化能力,bias强调了模型的误差能力。如果一个模型variance和bias都很低,它就能获得较低的泛化误差。
许多模型在设计的时候,都强调避免过拟合,像普遍存在的正则项。在ensemble类模型中,随机森林基于bagging方法,通过样本采样和特征采样,使得每颗树都各有特色。gbdt基于boosting方法,在每一轮训练,通过拟合残差,也训练出了各有特色的树。这些方式在保证bias的基础上,使得模型具有良好的泛化能力。
在一个实际系统中,Bias与Variance往往是不能兼得的。如果要降低模型的Bias,就一定程度上会提高模型的variance,反之亦然。造成这种现象的根本原因是,我们总是希望试图用有限训练样本去估计无限的真实数据。当我们更加相信这些数据的真实性,而忽视对模型的先验知识,就会尽量保证模型在训练样本上的准确度,这样可以减少模型的Bias。但是,这样学习到的模型,很可能会失去一定的泛化能力,从而造成过拟合,降低模型在真实数据上的表现,增加模型的不确定性。相反,如果更加相信我们对于模型的先验知识,在学习模型的过程中对模型增加更多的限制,就可以降低模型的variance,提高模型的稳定性,但也会使模型的Bias增大。Bias与Variance两者之间的trade-off是机器学习的基本主题之一,机会可以在各种机器模型中发现它的影子。
我们定义需要预测的真实结果Y,与其对应的自变量X(训练样本),之间有这样的关系:
Y = f(X) ϵ (ϵ满足正态分布ϵ∼N(0,σϵ) )
令yD为x在测试样本中的值,y为真实的值。有可能出现噪音使得yD != y
为了方便讨论,这里假定E[ yD - y ] = 0。
假设,fD(x)为训练集X上学得模型f在x上的预测输出,学习算法的期望预测为:
fExpectedD(x) = E[ fD(x) ]
统计学习中有一个重要概念叫做residual sum-of-squares:

RSS看起来是一个非常合理的统计模型优化目标。但是考虑K-NN的例子,在最近邻的情况下(K=1),RSS=0,是不是KNN就是一个完美的模型了呢,显然不是,KNN有很多明显的问题,比如对训练数据量的要求很大,很容易陷入维度灾难中。KNN的例子说明仅仅优化RSS是不充分的,因为针对特定训练集合拟合很好的model,并不能说明这个model的泛化能力好,而泛化能力恰恰又是机器学习模型的最重要的要求。真正能说明问题的不是RSS,因为它只是一个特定训练集合,而是在多个训练结合统计得出的RSS的期望,MSE(mean squared error),即期望泛化误差。
基于假设,我们可以得到关于测试集x的MSE(mean squared error):
MSE(x) = E[( fD(x) - yD)2]
MSE(x) = E[( fD(x) - fExpectedD(x) fExpectedD(x) - yD)2]
MSE(x) = E[(fD(x)- fExpectedD(x))2] E[(fExpectedD(x)-yD)2] E[2×(fD(x)-fExpectedD(x) )×(fExpectedD(x) - yD)]
第三项需要注意:由于训练集已知,所以这里的fExpectedD(x) - E[(fExpectedD(x) - yD)2]实际上是一个常数,可以拿到外部。
fD(x) - fExpectedD(x) 根据上面学习算法的期望预测的式子,可以知道其差值为0
即是:
MSE(x) = E[(fD(x) - fExpectedD(x))2] E[(fExpectedD(x) - yD)2]
MSE(x) = E[(fD(x) - fExpectedD(x) )2] E[(fExpectedD(x) - y y - yD)2]
MSE(x) = E[(fD(x) - fExpectedD(x))2] E[(fExpectedD(x) - y)2] E[(y - yD)]2 2×E[(fExpectedD(x) - y)×(y - yD)]
噪声期望为0,因此最后一项为0
MSE(x) = E[(fD(x) - fExpectedD(x))2] (fExpectedD(x) - y)2 E[(y - yD)]2
使用样本数相同的不同训练集产生的方差为:
var(x) = E[(fD(x) - fExpectedD(x))2]
期望输出与真实值的差别称之为偏差,即:
bias2(x) = (fExpectedD(x) - y)2
噪声为:
ϵ2 = E[(y - yD)]2
即是:
MSE(x) = var(x) bias2(x) ϵ2
从上面的推导我们可以看出,期望泛化误差可以分解为方差,偏差与噪声之和。
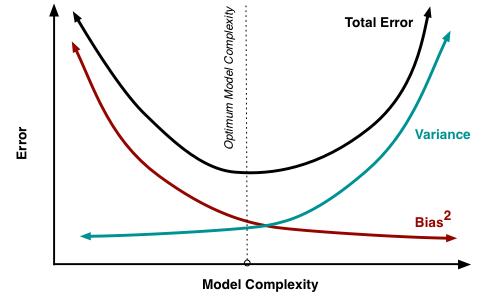
三、总结模型过于简单时,容易发生欠拟合(high bias);模型过于复杂时,又容易发生过拟合(high variance)。为了达到一个合理的 bias-variance 的平衡,此时需要对模型进行认真地评估。这就是所谓的偏差方差均衡。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






