机器学习最实用的算法(盘点机器学习优化的那些算法)
点击上方关注,All in AI中国
作者:Ravindra Parmar
机器学习的梯度下降
优化是机器学习算法最重要的组成部分。它首先定义某种损失函数/成本函数,然后使用一个或另一个优化例程使其最小化。优化算法的选择可以在几小时或几天内获得的良好精度之间产生差异。其优化的应用是无限的,是工业界和学术界广泛研究的课题。在本文中,我们将介绍在深度学习领域中使用的几种优化算法。(你可以通过本文了解损失函数的基础知识)
https://towardsdatascience.com/common-loss-functions-in-machine-learning-46af0ffc4d23
随机梯度下降法
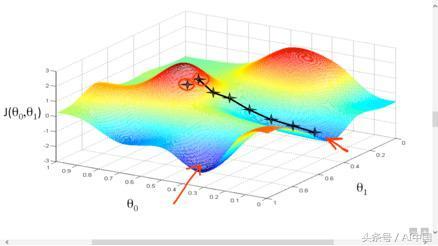
随机梯度下降(SGD)是用于查找最小化给定成本函数的参数的最简单优化算法。显然,为了使梯度下降收敛到最佳的最小值,其成本函数应该是凸出的。在此演示一下成本函数的图形表示。
梯度下降的例证
我们首先定义参数的一些随机初始值。优化算法的目标是找到对应于成本函数的最小值的参数值。具体而言,梯度下降开始于计算每个参数w.r.t成本函数的梯度(导数)。这些梯度使我们需要对每个参数进行数值调整,以便最小化成本函数。这个过程一直持续到我们达到局部/全局最小值(成本函数最小化w.r.t的周围值)。在数学上,
学习率对梯度下降的影响
学习率定义了每次迭代中应该更改的参数量。换句话说,它控制我们应该收敛到最低或最快的速度。一方面,小的学习率可以使迭代收敛,大的学习率可以超过最小值,如上图所示。
尽管在实践中很容易应用,但它在深度神经网络中有很多缺点,因为这些网络需要适应大量参数。为了说明梯度下降的问题,我们假设只有两个参数的成本函数。假设成本函数对参数之一(例如垂直方向)的变化非常敏感,而对其他参数(即水平方向)的变化也非常敏感(这意味着成本函数具有高条件数)。
曲折运动与梯度下降
如果我们在这个函数上运行随机梯度下降,我们会得到一种曲折线条。从本质上讲,随机梯度下降(SGD)在向敏感度较低的方向发展缓慢,而对高敏感方向则发展更快一些,因此在最小化方向并不一致。在实践中,深度神经网络可能具有数百万个参数,因此具有数百万个方向来适应梯度调整,从而使问题复杂化。
随机梯度下降(SGD)的另一个问题是局部最小值或鞍点问题。鞍点是在所有方向上梯度为零的点。因此,我们的随机梯度下降(SGD)将只停留在那里。另一方面,局部最小值是最小值w.r.t周围的点,但并非最小值。由于梯度在局部最小值为零,当全局最小值在其他位置时,梯度下降会将其报告为最小值。
为了解决批次梯度下降的问题,近年来开发了几种先进的优化算法。以下将逐一介绍。
随机梯度下降与动量
为了理解高级优化背后的动力学,我们首先要掌握指数加权平均的概念。假设我们获得了所有特定城市一年365天的温度数据。绘制这些数据,我们在下图中的左上角得到一个图表。
演示指数加权平均值
现在,如果我们希望计算当地全年的平均温度,按如下方式进行。
在每一天,我们计算前一天温度和当日温度的加权平均值。上面计算的图表显示在右上角。该图是过去10天的平均温度(α= 0.9)。左下角(绿线)显示过去50天的平均数据(alpha = 0.98)。
这里需要注意的一点是,随着我们对更多天数进行平均,曲线对温度变化的敏感度会降低。相反,如果我们在较少的天数内进行平均,则曲线将对温度的变化更敏感,并因此变得更加蠕动。
延迟的增加是由于我们给前一天的温度提供了比当日温度更高的权重。
到目前为止,这很好,但问题是这一切能给我们带来什么。很相似,通过平均过去几个值的梯度,我们倾向于减少更敏感方向的振荡,从而使其收敛更快。
在实践中,基于动量的优化算法几乎总是比批次梯度下降更快。在数学上,
AdaGrad的优化
我们的想法是,对于每个参数,我们存储其所有历史梯度的平方和。这个总和稍后用于缩放学习率。
请注意,与之前的优化相比,这里我们对每个参数都有不同的学习率。
现在的问题是,当我们的损失函数具有非常高的条件数时,这种缩放是如何帮助我们的?
对于具有高梯度值的参数,平方项将很大,因此用较大的平方项划分会使梯度在该方向上缓慢加速。类似地,具有低梯度的参数将产生较小的平方项,因此梯度将在该方向上加速更快。
然而请注意,随着梯度在每一步进行平方,其移动估计将随着时间的推移单调增长,因此我们的算法将收敛到最小值的步长会变得越来越小。
从某种意义上说,这对于凸起问题是有益的,因为在这种情况下我们预计会减慢到最小值。然而,在非凸优化问题的情况下,同样的好处会变成诅咒,因为陷入鞍点的机会增加。
RMSProp的优化
这是AdaGrad的一个细微变化,在实践中效果更好,因为它解决了所留下的问题。与AdaGrad类似,这里我们也将保持平方梯度的估计值,但不是让平方估计值累积在训练上,而是让估计值逐渐衰减。为此,我们将当前的平方梯度估计值与衰减率相乘。
Adam
这包含了RMSProp和Gradient下降的所有优点和动量。
具体而言,该算法计算梯度的指数移动平均值和平方梯度,而参数beta_1和beta_2控制这些移动平均值的衰减率。
请注意,我们已将second_moment初始化为零。因此,在开始时,second_moment将被计算为非常接近零的某个时刻。因此,我们通过除以非常小的数字来更新参数,从而对参数进行大量更新。这意味着最初,算法会做出更大的步骤。为了纠正这一点,我们通过结合当前步骤创建了对first_moment和second_moment的无偏估计。然后我们根据这些无偏估计而不是更新first_moment和second_moment的参数。在数学上,
下图演示了迭代过程中每个优化算法的性能。显然,增加动量可以提高准确性。然而,在实践中,Adam能够很好地处理大型数据集和复杂功能。
优化的性能度量
资源
RMSprop - 优化算法| Coursera
https://www.coursera.org/lecture/deep-neural-network/rmsprop-BhJlm
你可以找到更多的数学背景。请通过评论告诉本文可能适用的任何修改/改进。
https://www.coursera.org/lecture/deep-neural-network/rmsprop-BhJlm
,













免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






