大数据分析人工智能预测模型:使用序列模型对一句话中的每个词进行次性预测
在语言中,一个单词是有词性的,比如动词、形容词、名词等等,我们可以使用LSTM来做词性的判断。做词性判断可以有两种方式:
第一种是把一句话当作是一个序列数据,然后这句话中的每个词都是一个词向量,对应RNN的一个时间步,我们将其输入到神经网络中,然后每一个时间步都会有一个输出,每个输出表示输入到该时间步的单词的词性。
还有一种方式就是将词拆分成一个一个的字母,每个时间步输入到RNN中一个字母向量,然后在最后一个时间步输出这个单词的词性是什么
我们可以将这两种方式来结合起来,完成整个词性的判断
数据处理

以上就是我们的训练数据,DET、NN表示每个单词的词性,我们可以认为是对应词的标签
现在我们来生成字典,第一个字典是词的字典word_to_idx,第二个字典是标签的字典tag_to_idx

然后还要生成一个包含26个字母的字典
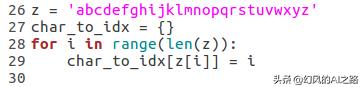
下面我们建立一个方法,这个方法就是当我们传入这个方法中字母或者单词的时候,就可以产生对应字典中的编号,就相当于对字符进行编码了。我们要将这个编码好的输入到神经网络中。

现在我们建立神经网络,第一个神经网络是每一个时间步输入为一个单词的字母,我们最后要最后一个时间步的输出

x.shape为[4,1,10],其中4表示序列是4,1表示batch为1,10表示词向量为10,out[-1]表示获取最后一个时间步的输出

其中参数n_word表示字典中词的数量,n_char表示字母字典中词的数量,char_dim表示字母向量的维度,word_dim表示词向量的维度,char_hidden表示char的LSTM的输出维度,word_hidden表示word的LSTM的输出维度,n_tag表示词性的类别。
这个神经网络的运行过程就是先进行字母预测,也就是将一句话中的每个单词进行字母预测,然后进行单词级别的预测,然后将这两者的预测输出cat组合,然后输入到全连接神经网络中,然后做最终的预测
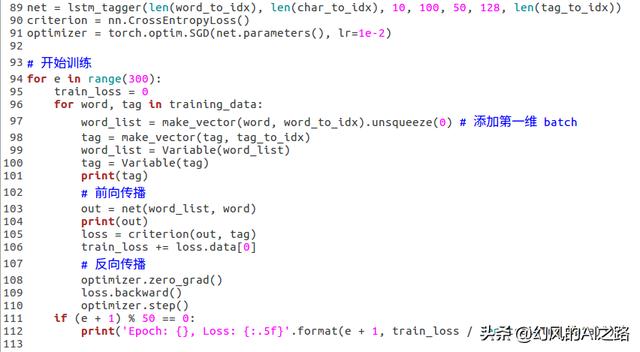
然后进行测试

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com