超低端显卡排行榜(超能课堂88)
NVIDIA这几年垄断了高端显卡市场,从他们的Q1季度财报中虽然也能看到Tegra、数据中心等业务有了明显增长,不过营收的主力还是游戏PC市场,Q1季度游戏PC市场营收就增长了50%,高端玩家现在买游戏显卡往往是从GTX 1080 Ti/1080/1070中选一款了。如今Pascal还未显出颓势,今天凌晨的GTC 2017主题演讲上,NVIDIA CEO黄仁勋发布了Volta架构显卡,新一轮升级又要来了。

NVIDIA能够获得现在的表现很大程度是因为他们的产品路线图比较连贯,从Kepler到Maxwell,再到现在的Pascal架构,NVIDIA每一代GPU升级都很稳定,短时间内就能完成高端到低端的布局。以Pascal这一代为例,首发的是GTX 1080、GTX 1070,接着是Titan X,陆陆续续又有GTX 1060 6GB及GTX 1060 3GB,还有GTX 1050 Ti、GTX 1050,今年3月份又有GTX 1080 Ti、Titan Xp,马上还会有GT 1030主打入门级市场——不算不知道,NVIDIA在Pascal这一代的GPU产品组合还真是挺多的。
Pascal显卡发布一年整了,产品线布局还在完善,不过大家的兴趣点现在已经开始向新一代GPU转移了,特别是今天发布了Volta架构显卡——Telsa V100,这跟去年Pascal架构首发GP100核心的Telsa P100一样,也在去年这个时候,,今天我们也会针对GV100核心及Tesla V100显卡做更深入的探讨。
早上已经有Tesla P100的新闻发布了,大家也了解过基本情况了,我们先来看看Tesla V100加速卡的真身,这次同时展示的是两个版本的。
Tesla V100显卡真身:NVLink与PCI-E版大不同

NVLink 2接口的Tesla V100显卡(点击放大,图片来源于Heise)
老黄手里曝光最多的就是这个短小强悍的Tesla V100,它实际上NVLink版的,跟去年的Tesla P100看着很像,毕竟这二者都使用了HBM 2显存,功耗也没有明显增加,应该是直接沿用相同的PCB电路。

PCI-E接口的Tesla V100显卡(点击放大,图片来源于Golem)
PCI-E版的Tesla V100显卡不太引人注意,找到了上面这张照片,如果跟去年PCI-E版的Tesla P100显卡对比,可以看出PCI-E版Tesla V100显卡跟PCI-E版P100有很多不同,散热器明显小多了,体积跟NVLink版差不多。

这是去年的PCI-E版Tesla P100加速卡
Telsa V100加速卡规格:Volta架构终于来了
Tesla V100是针对HPC市场设计的,跟普通消费者没啥关系(属于吃瓜群众买不到买不起系列),之所以引人关注是因为它使用的是新一代Volta架构,首发的依然是GV100这种大核心。早上的新闻中大家也看到了它各方面规格都很惊人——815mm2核心面积、211亿晶体管、5120个CUDA核心、15TFLOPS浮点性能等等,放在当前的显卡中简直是鹤立鸡群,拿来跑游戏不知道多爽,可惜老黄不卖给消费级玩家。

NVIDIA Volta/Pascal与AMD Vega显卡的规格对比
为此我做了一个详细的规格表,对比的产品除了目前的Tesla P100和Titan Xp之外,还加入了AMD的Vega 10核心的Radeon Instinct MI25显卡,尽管还没上市,但AMD早前公布过这款显卡的一些信息,比如带宽、浮点性能,不过Vega核心的晶体管、核心面积等关键参数还是个谜。
对比GP100核心与GV100核心,可以看出后者规模进一步扩大,SM单元数量从之前的56组提升到了80组,CUDA核心数从3584个提升到5120个,计算单元数量增幅为43%。显存位宽及容量都没变化,还是16GB HBM2显存,不过频率有所提升,带宽从前代的720GB/s提升到了900GB/s,非常接近HBM 2显存理论上1024GB/s的带宽了(搭配4颗HBM显存的情况下)。
计算单元的增加也使GV100核心的规模进一步扩大——晶体管数量从目前的153亿增加到了211亿,核心面积从610mm2提升到815mm2,一举创造了NVIDIA GPU同时也是现代GPU的核心面积新纪录。NVIDIA这几代大核心虽然核心面积有涨有降,不过之前最多是在600mm2级别徘徊,这一次直接做了815mm2的大核心。
与Pascal架构GP100核心相比,Volta的GV100核心在架构上更多地是量变而非质变,不过它在架构也不是说没升级,这次GV100核心主要的变化就是针对AI人工智能、DL深度学习等新兴领域专门做了运算单元,我们下面再说这个。
Volta架构改进:Pascal翻新,新增Tensor单元
在之前解析GTX 1080与Tesla P100时,我们说过主流的GP104核心跟GP100核心是不同的,前者跟Maxwell架构没多大变化,每组SM单元是128个CUDA核心,GP100上每组SM单元是64个CUDA核心,而后面的GP102核心跟GP100也不同,更像是GP104核心的扩大版,也是每组SM单元128个CUDA核心。

GP100核心架构示意图
回到GP100与GV100大核心上,他们的架构也是渐进式变化,也是6组GPC计算单元,不过GP100核心每个GPC单元中是10组SM单元,每个SM单元有64个CUDA核心,而GV100大核心中每组GPC单元是14个SM单元,总数应该是84组SM单元,但是现在Tesla V100跟Tesla P100一样都不是完全体,前者启用了56组SM单元,后者启用了80组SM单元,总计80x64=5120个CUDA核心。

GV100核心架构示意图
以上算的是典型的FP32单精度运算单元,除此之外还有FP64单元,GV100依然延续了GP100中FP32:FP64=2:1的比例,每个SM单元中有32个FP64单元,理论上有2688个FP64单元,实际启用的是2560个。
NVIDIA这两年在深度计算、人工智能等领域投入很多精力,GPU架构也在传统HPC应用之外开始适应这些新兴领域,他们对运算精度要求没这么高,但对性能要求很高,Pascal显卡中就开始支持FP16、FP8精度运算,执行这些运算的性能也是翻倍增长。

GV100与GP100核心SM单元的变化
因此在GV100大核心,NVIDIA还加入了专门的Tensor(张量)运算单元,大部分人估计不熟悉这个词,不过还记得前不久Google搞的那个TPU在AI性能上吊打GPU的新闻吗?Google的TPU处理器中的T也是Tensor这个词,大家可以把它当作专用的AI运算单元来看。

GV100核心中增加了专门的Tensor运算单元(图片来源于Golem网站)
在GV100大核心中,每组SM单元中还有8个Tensor单元,这样整个SM单元中就是FP32:FP64:Tensor=64:32:8的比例存在,GV100也因此有了Tensor计算能力这个指标,Tesla P100的Tensor计算能力高达120TFLOPS,NVIDIA宣称它的Tensor性能是Pascal架构的12倍。
Volta支持第二代NVLink技术:300GB/s带宽
除了针对AI等新兴领域改进了Tensor单元之外,GV100核心在总线技术上也有升级,这次使用的是NVLink 2,如果你注意看了上面的架构示意图,应该可以发现GV100核心是6组NVLink通道,双向总带宽可达300GB/s。
相比之下,GP100核心上是4组NVLink通道,每个通道带宽是40GB/s,总带宽是160GB/s。
不论NVLink还是NVLink 2总线,相比PCI-E 3.0x16双向32GB/s的带宽都有明显提升,不过NVLkink并不是通用技术,主要用于IBM和NVIDIA开发的超算平台,这次GV100核心就会用在双方合作的Summit超算上,预计今年下半年正式启用。
Volta工艺升级:这个12nm有点特别
NVIDIA在主题演讲中还提到了Volta显卡的制造工艺,使用的是TSMC的12nm FFN工艺,听上去要比目前TSMC 16nm工艺更先进,那这种新工艺对Volta显卡到底有什么改善吗?我们依照上次的计算简单评估下不同工艺下的晶体管密度及效能。
由于AMD Vega显卡的核心面积、晶体管数量都是未知数,所以这里只对比了NVIDIA几代显卡的。
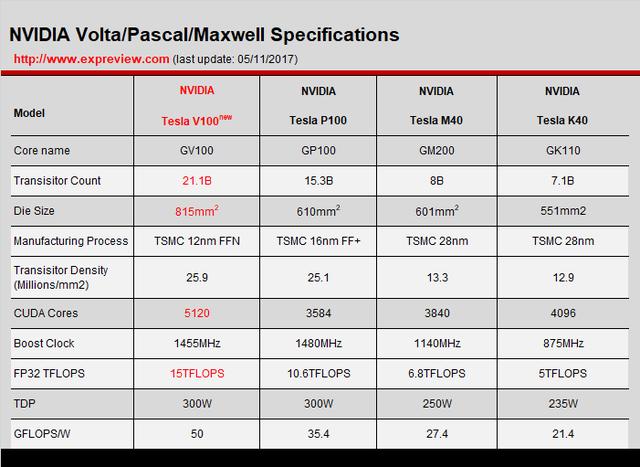
GV100核心是12nm工艺,211亿晶体管,核心面积815mm2,算下来晶体管密度是每平方毫米25.9百万晶体管,与16nm工艺的晶体管密度差不多。实际上,TSMC的12nm工艺也是16nm工艺的改良版。根据TSMC此前公布的资料,它实际是基于16nm FFC工艺改进的,性能是后者的1.1倍,功耗只有后者的70%,核心面积则可以缩小20%。
按照TSMC的说法,16nm FinFET Plus依然是他们性能最好的16nm工艺,现在GV100用的12nm工艺在性能上还真不一定能超过16nm FinFET Plus工艺,Tesla V100的加速频率就比P100要低一些,但从核心面积来看,计算单元规模增加了43%,核心面积只增加了33%,说明这个12nm工艺对缩小面积还是挺管用的。
至于未来的消费级显卡,GV102、GV104核心上12nm工艺也没跑了,但显卡的核心频率不会再像Pascal对比Maxwell时代那样大幅提升了,性能提升只能靠计算单元数量增加了。
Volta架构性能:比Pascal提升50%
说到性能,我们再简单看下NVIDIA官方资料中介绍的GV100性能提升情况:

DL深度计算性能三倍快,这个因为有Tensor单元加持,性能暴涨很正常
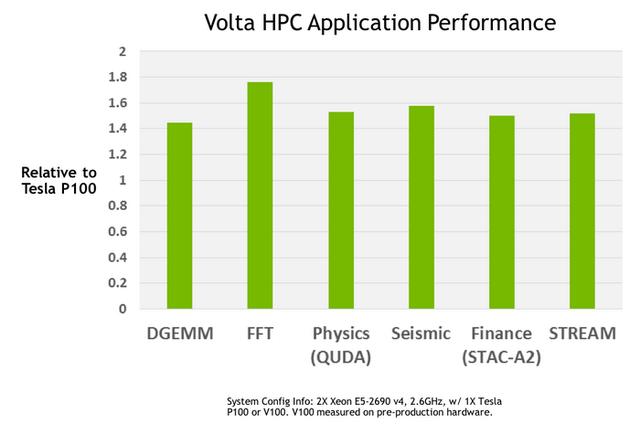
HPC性能提升情况
与Tesla P100加速卡相比,Tesla V100在不同HPC应用中性能提升有所不同,多的能超过70%,少的也有40%以上,官方给出的平均性能提升大约是50%——考虑到计算单元增幅也有43%,性能提升基本上与计算单元数量增幅呈正比,这跟Tesla P100时代频率大幅提升带来性能大提升的情况也有所不同。
总结:
GV100核心是为HPC运算市场而生的,跟Tesla P100的GP100核心一样也不会用于消费级市场,所以这篇文章对我们的意义更多地是分析未来的GV102、GV104核心的GeForce 20系列显卡的性能及表现。
与GV100一样,GV102/104核心的CUDA核心数量也会进一步提升,NVIDIA还可以通过阉割对消费级市场没什么用的FP64、Tensor单元来降低核心面积及成本,一如GP100到GP102那样。
Volta架构使用的12nm工艺在降低核心面积上很有用,但是从GV100上的频率来看,12nm下消费级Volta显卡的核心频率恐怕也很难有明显提升了,现在的GTX 10系中高端非公版显卡核心频率都能达到2GHz左右,未来的12nm Volta显卡估计也就是这个水平,甚至还有可能更低一些。
如果是这种情况,NVIDIA要想提高新一代显卡的性能,那么就只能从CUDA核心数量上着手了,Pascal这一代在频率上占了很多红利,Volta又要回到GPU运算单元提升的道路上了。
目前消费级的Volta显卡还没有明确的发布时间,今年底有希望推出部分高端产品,不过更有可能的还是2018年Q1季度,所以现在的Pascal显卡并不会受到什么冲击,大家现在该买什么卡就买什么卡,不着急的也可以等等AMD发了Vega显卡之后再看。不过NVIDIA看起来并不担心AMD的竞争,黄仁勋在之前的财报会议上表态2017年的市场竞争态势不会有什么变化,换言之就是AMD发布的Polaris 20及Vega 10显卡对他对不会有什么影响。
总之,Volta显卡现在露出了曙光,GV100上带给大家的有希望也有担心,想要了解更多Volta显卡信息的玩家可以加小超哥(ID:9501417)微信,他会爆料更多Volta显卡发布、性能及售价方面的消息。

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






