django 如何操作一张表 Django之ORM表高级操作增删改查

目录
- 一、如何开启自己的测试脚本?
- 二、对表数据的添加、更新、删除1.create()变态操作之批量插入数据2.update()3.delete()4.如何查看QuerySet对象执行的sql语句?5.如何配置文件自动查看sql语句?
- 三、 单表查询13个操作返回QuerySet对象的方法有:1.all() 查询所有结果2.filter() 条件匹配3.exclude() 取反4.order_by() 排序5.reverse() 反转6.distinct() 去重特殊的QuerySet:7.values() 获取指定字段对 列表套字典8.values_list() 获取指定字段对** 列表套字典 列表套元组返回具体对象的:9.get 直接获取对象,不存在就报错10.first() 取第一个元素对象11.last() 取最后一个元素对象返回布尔值的方法有:12.exists()返回数字的方法有:13.Count() 统计数据条数
- 四、神奇的双下线跨表查询
- 五、外键字段的增删改查1.一对多2.多对多1.绑定关系 add2.移除绑定关系 remove3.修改绑定关系 set4.清空关系
- 六、跨表查询1.基于对象的跨表查询(子查询):2.基于双下划线跨表查询(链表查询)3.聚合查询4.分组查询5.F查询6.Q查询7.Q的高阶用法
如何只单独测试django中的某一个py文件
如何书写测试脚本
在任意一个py文件中书写以下代码
应用下的tests
或者自己新建一个
import os
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day53.settings")
import django
django.setup()
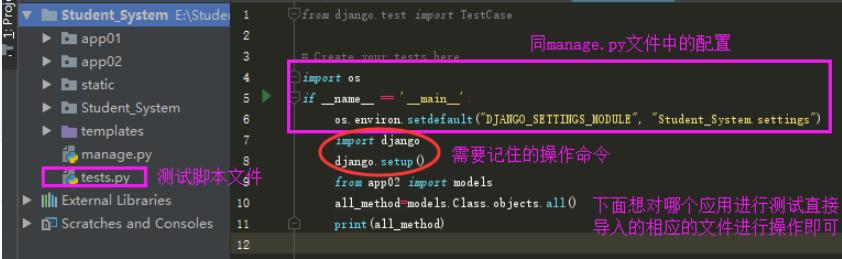
这样就可以直接运行你的test.py文件来运行测试

1.create() # 添加
2.update() # 更新
3.delete() # 删除
# 对电影表添加一条数据
# create() 返回值就是当前被创建数据的对象本身
models.Movie.objects.create(title='西游记',price=999.23,publish_time='2016-1-1')
# 还可以直接传日期对象
from datetime import date
ctime = date.today()
models.Movie.objects.create(title='西游记', price=666.23, publish_time=ctime)
方式一:
走1000从数据库,非常的慢
def ab_bc(request):
# 插入1000条件数据
for i in range(1,1001):
models.Book.objects.create(title='第%s本书'%i)
方式二:调用bulk_create()方法
插入10000条数据,走一次数据库
def ab_bc(request):
book_list = []
for i in range(1,10001):
book_list.append(models.Book(title='新的%s书'%i))
models.Book.objects.bulk_create(book_list) # 批量插入数据的方式
# update() 更新数据 返回值是受影响的行数
res = models.Movie.objects.filter(pk=1).update(title='玉女心经')
print(res) # 1 受影响的条数
# delete() 删除数据 返回值(1, {'app01.Movie': 1}) 受影响的表及行数
res = models.Movie.objects.filter(pk=3).delete()
print(res) # (1, {'app01.Movie': 1})
res = models.Movie.objects.filter(pk=3).delete()
print(res.query) # 获取res的sql执行语句
如果你想知道你对数据库进行操作时,Django内部到底是怎么执行它的sql语句时可以加下面的配置来查看
在Django项目的settings.py文件中,在最后复制粘贴如下代码:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
配置好之后,再执行任何对数据库进行操作的语句时,会自动将Django执行的sql语句打印到pycharm终端上

返回QuerySet对象的方法有:
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet:
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元组序列
返回具体对象的:
get()
first()
last()
返回布尔值的方法有:
exists()
返回数字的方法有:
count()
res = models.Movie.objects.all()
print(res)

# 获取电影表中id为1的数据
# 不存在就返回空,而不是报错。get(id=1)不存在就直接报错
res = models.Movie.objects.filter(id=1)
print(res)

# 获取id为1之外的数据
res = models.Movie.objects.exclude(pk=1)
print(res)

res = models.Movie.objects.order_by('price') # 默认是升序
res = models.Movie.objects.order_by('-price') # 减号就是降序
res = models.Movie.objects.order_by('price').reverse() # 将次序反转
# 去重:去重的前提 必须是由完全一样的数据的才可以
res = models.Movie.objects.values('title','price').distinct()
返回一个可迭代的字典序列
values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
# values() QuerySet对象 [{},{},{}] 获取指定字段对的数据
# 返回一个可迭代的字典序列
res = models.Movie.objects.values('title','publish_time')

返回一个可迭代的元组序列
values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
res = models.Movie.objects.values_list('title','price')
print(res)

# get() 直接获取对象本身 不推荐使用 当查询条件不存在的时候直接报错
res = models.Movie.objects.get(pk=1)
print(res)
# first() 数据对象 取第一个元素对象
res = models.Movie.objects.filter().first()
print(res)
# last() 数据对象 取最后一个元素对象
res = models.Movie.objects.last()
print(res)
# exists() 返回的是布尔值 判断前面的对象是否有数据
res = models.Movie.objects.filter(pk=1000).exists() # 不存在,Fslse
print(res)
res = models.Movie.objects.filter(pk=1).exists() # 存在,True
# 统计筛选之后数据的条数
res = models.Movie.objects.count()
print(res)
在python中我们进行逻辑判断会用到>、<、=、or之类的符号,那么在Django进行models数据操作的时候,我们表示:双下划线
__gt : 大于
__lt : 小于
__gte : 大于等于
__lte : 小于等于
__in : 或
__rang : 在...之间,顾头也顾尾
__contains :模糊查询,区分大小写
__icontains :模糊查询,不区分大小写
__year : 查询年份
__month : 查询月份
案例:
# 神奇的双下划线查询
# 1.查询价格大于200的电影
res = models.Movie.objects.filter(price__gt=200)
print(res)
# 2.查询价格小于500的电影
res = models.Movie.objects.filter(price__lt=500)
print(res)
# 3.查询价格大于等于876.23的电影
res = models.Movie.objects.filter(price__gte=876.23)
print(res.query)
# 4.查询价格小于等于876.23的电影
res = models.Movie.objects.filter(price__lte=500)
print(res)
# 5.查询价格是123 或666 或876
res = models.Movie.objects.filter(price__in=[123,666,876])
print(res)
# 6.查询价格在200到900之间的电影 顾头也顾尾
res = models.Movie.objects.filter(price__range=(200,900))
print(res)
# 7.查询电影名中包含字母p的电影
res = models.Movie.objects.filter(title__contains='p') # 默认是区分大小写
res = models.Movie.objects.filter(title__icontains='p') # i忽略大小写
# 8.查询2014年出版的电影
res = models.Movie.objects.filter(publish_time__year=2014)
# print(res)
# 9.查询是1月份出版的电影
res = models.Movie.objects.filter(publish_time__month=1)
print(res)
在1.X版本中默认就是级联更新、级联删除
在2.X版本中需要自己手动设定
1.一对多1.增 直接写真实的表字段
# publish_id是外键字段
models.Book.objects.create(title='三国演义',price=123.23,publish_id=2)
2.增 通过对象
# Publish 是modles中有关联的表
publish_obj = models.Publish.objects.get(pk=1)
models.Book.objects.create(title='大话西游',price=66.66,publish=publish_obj)
1.改 直接筛选出来,直接改
models.Book.objects.filter(pk=1).update(publish_id=3)
2.改 通过对象
# 先获取出版社表id为4的对象
publish_obj = models.Publish.objects.get(pk=4)
models.Book.objects.filter(pk=1).update(publish=publish_obj)
add专门给第三张关系表添加数据
括号内即可以传数字也可以传对象 并且都支持传多个
# 1.获取书籍对象
book_obj = models.Book.objects.filter(pk=1).first()
# 2.书籍对象点‘.’外键字段就已经跨入第三张表中了。再用add添加绑定关系
book_obj.authors.add(1,2,3) # 给书籍绑定一个主键为1,2,3的作者
# 获取对象
author_obj = models.Author.objects.get(pk=1)
author_obj1 = models.Author.objects.get(pk=3)
# 添加绑定关系
book_obj.authors.add(author_obj)
book_obj.authors.add(author_obj,author_obj1)
remove专门给第三张关系表移除数据
括号内即可以传数字也可以传对象 并且都支持传多个
# 按照具体外键的值进行删除
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.remove(2)
book_obj.authors.remove(1,3)
# 获取相关对象删除
author_obj = models.Author.objects.get(pk=2)
author_obj1 = models.Author.objects.get(pk=3)
book_obj.authors.remove(author_obj)
book_obj.authors.remove(author_obj,author_obj1)
set 修改书籍与作者的关系
括号内支持传数字和对象 但是需要是可迭代对象
# authors外键字段,Author类名
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.set((3,))
book_obj.authors.set((2,3))
author_obj = models.Author.objects.get(pk=2)
author_obj1 = models.Author.objects.get(pk=3)
book_obj.authors.set([author_obj,author_obj1]) # 可迭代对象
clear() 清空关系
不需要任何的参数
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.clear() # 去第三张表中清空书籍为1的所有数据
mysql中跨表查询的方式
1.子查询 将一张表的查询结果当做另外一张表的查询条件
正常解决问题的思路 分步操作
2.链表查询
inner join
left join
right join
union
正反向的概念
正向
跨表查询的时候 外键字段是否在当前数据对象中 如果在
查询另外一张关系表 叫正向
反向
如果不在叫反向
口诀
正向查询按外键字段
反向查询按表名小写
案例:
正向查询的时候 当外键字段对应的数据可以有多个的时候需要加.all()
否则点外键字典即可获取到对应的数据对象
基于对象的反向查询 表名小写是否需要加_set.all()
一对多和多对多的时候需要加,查询有多个结果。 加_set.all()
一对一不需要,查询只有一个结果 不加
# 1.查询书籍pk为1的出版社名称
book_obj = models.Book.objects.filter(pk=1).first()
print(book_obj.publish.name)
# 2.查询书籍pk为2的所有作者的姓名
book_obj = models.Book.objects.filter(pk=2).first()
author_list = book_obj.authors.all()
for author_obj in author_list:
print(author_obj.name)
# 3.查询作者pk为1的电话号码
author_obj = models.Author.objects.filter(pk=1).first()
print(author_obj.author_detail.phone)
# 4.查询出版社名称为东方出版社出版过的书籍
publish_obj = models.Publish.objects.filter(name='东方出版社').first()
print(publish_obj.book_set.all())
# 5.查询作者为jason写过的书
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.book_set.all())
# 6.查询手机号为120的作者姓名
author_detail_obj = models.AuthorDetail.objects.filter(phone=120).first()
print(author_detail_obj.author.name)
只要表之间有关系 你就可以通过正向的外键字段或者反向的表名小写 连续跨表操作
# 1.查询书籍pk为1的出版社名称
# 正向
res = models.Book.objects.filter(pk=1).values('publish__name') # 写外键字段 就意味着你已经在外键字段管理的那张表中
print(res)
# 反向
res = models.Publish.objects.filter(book__pk=1) # 拿出版过pk为1的书籍对应的出版社
res = models.Publish.objects.filter(book__pk=1).values('name')
print(res)
# 2.查询书籍pk为1的作者姓名和年龄
# 正向
res = models.Book.objects.filter(pk=1).values('title','authors__name','authors__age')
print(res)
# 反向
res = models.Author.objects.filter(book__pk=1) # 拿出出版过书籍pk为1的作者
res = models.Author.objects.filter(book__pk=1).values('name','age','book__title')
print(res)
# 3.查询作者是jason的年龄和手机号
# 正向
res = models.Author.objects.filter(name='jason').values('age','author_detail__phone')
print(res)
# 反向
res = models.AuthorDetail.objects.filter(author__name='jason') # 拿到jason的个人详情
res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','author__age')
print(res)
# 4.查询书籍pk为的1的作者的手机号
# 正向
# 只要表之间有关系 你就可以通过正向的外键字段或者反向的表名小写 连续跨表操作
res = models.Book.objects.filter(pk=1).values('authors__author_detail__phone')
print(res)
# 反向
res = models.AuthorDetail.objects.filter(author__book__pk=1).values('phone')
print(res)
需要使用到:aggregate关键字
from django.db.models import Max,Min,Avg,Count,Sum # 导入模块
res = models.Book.objects.aggregate(avg_num=Avg('price'))
print(res)
# 查询价格最贵的书
res = models.Book.objects.aggregate(max_num=Max('price'))
print(res)
# 全部使用一遍
res = models.Book.objects.aggregate(Avg("price"), Max("price"), Min("price"),Count("pk"),Sum('price'))
print(res)
需要使用到:annotate关键字
# 1.统计每一本书的作者个数
res = models.Book.objects.annotate(author_num=Count('authors')).values('title','author_num')
print(res)
# 2.统计出每个出版社卖的最便宜的书的价格
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price','book__title')
print(res)
# 3.统计不止一个作者的图书
res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title')
print(res)
# 4.查询各个作者出的书的总价格
res = models.Author.objects.annotate(price_sum=Sum('book__price')).values('name','price_sum')
print(res)
如何按照表中的某一个指定字段分组?
res = models.Book.objects.values('price').annotate() 就是以价格分组
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个我们自己设定的常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
简而言之:F()查询可以动态获取表字段对应的值
需要导入模块:from django.db.models import F,Q
案例:
# 1.查询库存数大于卖出数的书籍
res = models.Book.objects.filter(kucun__gt=F('maichu'))
print(res)
# 2.将所有书的价格提高100
res = models.Book.objects.update(price=F('price') 100)
','逗号隔开是and关系
'|'管道符是or的关系
'~'是not关系
filter() 等方法中逗号隔开的条件是与的关系。 如果你需要执行更复杂的查询(例如OR语句),你可以使用Q对象。
示例1:
查询 卖出数大于100 或者 价格小于100块的
from django.db.models import Q
models.Product.objects.filter(Q(maichu__gt=100)|Q(price__lt=100))
# 1.查询书的名字是python入门或者价格是1000的书籍
res = models.Book.objects.filter(title='python入门',price=1000) # and关系
res = models.Book.objects.filter(Q(title='python入门'),Q(price=1000)) # 逗号是and关系
res = models.Book.objects.filter(Q(title='python入门')|Q(price=1000)) # |是or关系
res = models.Book.objects.filter(~Q(title='python入门')|Q(price=1000)) # ~是not关系
res = models.Book.objects.filter('title'='python入门')
q = Q()
q.connector = 'or' # q对象默认也是and关系 可以通过connector改变or
q.children.append(('title','python入门'))
q.children.append(('price',1000))
res = models.Book.objects.filter(q)
print(res)
选择了IT,必定终身学习
作者:Jeff
出处:dwz.date/bEnv
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






