代码解读工作原理(识别工作代码示例)
工作代码示例是软件开发中实用重用的有用资源。工作代码示例提供了特定编程问题的解决方案。早期的研究表明,现有的代码搜索引擎在查找工作代码示例方面并不成功。它们无法将高质量的代码示例排列在结果集的顶部。为了解决这个问题缺点是,文献中提出了多种基于模式的解决方案。然而,由于它们的高时间复杂度或查询语言限制,这些解决方案不能在互联网规模的源代码引擎中无缝集成。本文提出了一种适用于Internet规模的源代码搜索引擎的工作代码实例识别方法。我们的方法的时间复杂度与现有的因特网上的代码搜索引擎的复杂性一样低,大大低于支持自由形式查询的基于模式的方法。我们使用25000个开源Java项目的代表性语料库来研究我们的方法的性能。我们的发现支持我们的方法在互联网规模的代码搜索的可行性。我们还发现,在发现工作代码示例方面,我们的方法优于Ohloh代码搜索引擎(以前称为Koders)。
关键词源代码搜索、克隆检测、工作代码示例
1. 绪论源代码示例是一个代码片段,即几行可重用的源代码,用于说明如何解决编程问题。源代码示例在编程中起着重要作用,并为学习[27][29]和重用[10][18][19]提供了内在资源。代码示例可以加速开发过程[23]并提高产品质量[25]。工作代码示例是一个代码片段,可以考虑用于学习和实用重用。这样的工作代码示例可以产生广泛的应用程序,从API的使用(例如,如何使用JFreeChart库保存图表)到基本的算法问题(例如,气泡排序)。理想的工作代码示例应该简洁、完整、自包含、易于理解和重用。
在软件开发中,显式地记录代码示例[15][35][37]并不常见。程序员必须通过以前编写的项目和Internet上公开可用的代码库(例如sourceforge.net)来搜索代码示例。使用源代码搜索引擎[6][10]在因特网上搜索源代码示例。这些引擎被称为互联网规模代码搜索引擎[14],例如Ohloh代码(以前称为Koders)和谷歌代码搜索[13](自2013年3月起停止服务)。
代码片段和查询之间的文本相似性是现有因特网规模代码搜索引擎所使用的主要度量。Holmes等人研究[16]表明,这种相似性不足以成功地进行代码示例搜索。BuSE和Wiemer[10]讨论了现有代码搜索引擎的答案通常是复杂的,即使在切片之后。综上所述,现有的Internet规模代码搜索引擎不支持正确定位工作代码示例。
为了在不影响用户与引擎交互方式的情况下改进Internet规模的代码搜索引擎,任何候选解决方案都必须具有三个属性。首先,搜索算法的输入输出格式必须与互联网规模代码搜索引擎的输入输出格式相同。具体来说,它必须支持自由形式的查询。输出应该是一组排序的代码片段。第二,搜索算法的时间复杂度必须很低。否则,该解决方案无法与在线引擎集成,用于搜索大规模数据。第三,它不应该局限于API使用查询。尽管最近的研究表明,相当多的代码搜索查询与API使用问题有关,但程序员仍然使用代码搜索引擎来解决其他问题[3][28]。
已有文献提出了几种基于模式的代码搜索方法。这些方法都不能满足所有这些特性。例如,较早的方法保持高的时间复杂度。在运行时嗅探的时间复杂度为[12 ],其中n是片段数。当有一个涵盖数百万代码片段的综合语料库时,这样的复杂性降低了它们的适用性。此外,早期的方法主要关注API的使用,其输出是抽象的编程解决方案。抽象的编程解决方案是一系列API方法调用指纹,例如,文件打开->文件读取->文件关闭。
我们提出了一种在发现工作代码示例的情况下提高因特网规模代码搜索引擎性能的方法。我们的研究不同于先前的工作(例如SNIFF[12]和PRIME[26]),因为我们的方法通过利用克隆检测的基本原理来满足上述三个条件。我们的方法结合了Baker的p-弦[4]和Carter等人的方法。[11]基于向量空间模型的克隆检测方法。我们使用频繁项集挖掘(frequent itemset mining)[7]来扩展这个思想,以检测流行的编程解决方案。此方法不限于API指纹;它考虑所有源代码令牌。此外,我们发现工作代码示例的方法与因特网规模代码搜索引擎保持相同的复杂性。这种方法在数百毫秒内对覆盖数百万代码片段的语料库回答一个自由形式的查询。
本文的主要贡献如下:
我们提出了一种可以被互联网规模的代码搜索引擎无缝使用的方法(例如,Ohloh代码)。我们的方法提高了它们发现工作代码示例的性能。
我们用大约25000个Java开源项目来评估我们方法的可伸缩性和可行性。我们确定了一个高级的排序模式,用于在一个有噪声的综合语料库中发现工作代码示例。最后,我们观察到我们的方法在识别工作代码示例方面优于Ohloh代码。
论文的组织
第二节概述了我们的研究动机。第三节概述了背景克隆检测技术。第4节提供了我们在事实提取、挖掘和搜索方面的方法细节。在第五节中,我们介绍了评估结果和对有效性的威胁。第6和第7节介绍了有关工作、结论和今后的工作。
2. 激励性例子在这篇文章中,我们提出了一种查找和排序工作代码示例的方法。在这一节中,我们用两个激励性的例子来阐述我们的问题陈述。对于每一个例子,我们讨论的结果之一,将获得从现有的互联网规模的代码搜索引擎,先前提出的基于模式的代码搜索方法(例如,嗅探[12]),以及我们的方法。为了提高可读性,我们将我们的方法与其他基于模式的代码搜索方法分开讨论。
2.1冒泡排序例子
气泡排序是一个经典的规划问题。然而,冒泡排序由于其时间复杂度而不是一种常用的排序算法。因此,没有本机或流行的API在Java中实现bubble排序。然而,初级开发人员和学生仍然在互联网上搜索泡沫排序实现[21]。一个典型的自由格式查询不是query={bubblesort},就是query={bubble,sort}。

图1.冒泡排序
互联网规模代码搜索引擎.冒泡排序查询是代码搜索引擎(例如,Ohloh代码)支持的查询之一。基于相关性的搜索方法[9]很容易找到这样的代码片段,因为它通常嵌入到一个称为bubble sort的方法或类中。Ohloh代码利用这些结构数据进行术语匹配。因此,Ohloh代码返回的第一个命中是嵌入在名为bubbleSort的方法中的算法的正确实现。然而,这些引擎严重依赖于从Web搜索引擎中采用的术语匹配和相关性搜索。因此,Ohloh代码返回的第二个hit是空if条件。这个代码片段是作为第二个点击放置的,因为它属于一个名为sortingalgorithms-bubble-sort-2.java的文件。本例强调了任何仅依赖于术语匹配和文本相似性的代码搜索方法所面临的挑战。
基于模式的代码搜索方法.PRIME[26]和SNIFF[12]等方法无法回答冒泡排序查询。这主要是因为它们仅限于挖掘与API相关的指纹。
我们的方法.图1显示了我们的spotting方法在560毫秒内为bubble排序查询返回的第一个结果。结果是基于550万个索引代码片段,每个片段至少有5行代码从25000个开源项目中提取出来。spotted snippet是bubble排序算法的实现之一。这个激励性的例子还突出了我们的代码搜索方法的一个有趣的特性。匹配的答案可能不一定包含查询词。我们利用克隆检测的思想来实现这个特性。在本例中,在发现的片段中没有出现bubble、sort或bubblesort之类的查询词;而代码片段实际上实现了bubble排序。值得一提的是,我们的搜索方法使用代码片段的内容,不考虑其他资源,如内联注释、Javadocs和所有者方法、类或文件的签名。此外,我们的方法能够搜索和挖掘正则和控制流语句与基于图的搜索方法相比,具有更低的复杂性,例如Prime[26]。总之,对于气泡排序问题等情况,支持控制流语句的挖掘和搜索是非常重要的,因为循环和条件构成了它们实现的基础。
2.2MD5例子
第二个激励示例是一个代码搜索问题,该问题与在Java中为MD5散列值生成发现工作代码示例有关。目标是以字符串格式获取对象(如密码)的MD5表示。MD5哈希代码生成并不是使用Java本机库的一项简单的编程任务。首先,在名为MD5的Java库中没有方法或类名。负责生成MD5的实际类和方法是MessageDigest,getInstance()、update()和digest()。其次,将哈希值的二进制表示转换为字符串,有特殊情况需要处理。如果没有正确的转换方法,如果生成的哈希值以0开头,则在从原始格式转换为字符串(Binary→Numeric→String)的过程中,将忽略前导0。互联网规模代码搜索引擎。现有的代码搜索引擎不支持这样的查询(例如,query={messagedigest,md5})。例如,Ohloh代码的前10个答案中没有一个是完整的代码示例,说明如何使用MessageDigest生成MD5哈希值。在最好的情况下,结果只显示如何使用getInstance方法创建MessageDigest的对象。
基于模式的代码搜索方法.这个查询对于最近提出的基于模式的代码搜索方法来说是一个挑战。对于这个正在运行的示例,不可能使用前面的大部分工作,因为它们不支持自由形式的查询,并且仅限于API名称(即,无法在查询中处理MD5术语)。令人惊讶的是,支持自由形式查询的SNIFF也未能回答此查询。
我们的方法.图2显示了我们的方法为MD5查询返回的排名靠前的结果。这是一个基于Buse和Weimer[10]讨论的完整答案,因为它包括所有实现步骤,甚至包括错误处理案例。
2.3总结
总之,本节中的示例突出了我们方法的三个主要特性:(1)为API使用和算法问题定位工作代码示例;(2)提供自包含示例的能力;以及(3)对术语匹配的依赖性较小。此外,我们提出的方法只需要代码片段content1。这些特征说明了我们在语用重用上下文中进行代码搜索的潜力。我们的方法利用了克隆检测基础,这使得我们能够消除早期基于模式的方法和现有因特网规模代码搜索引擎的局限性。
3. 背景最初,源代码中的相似性检测已经被克隆检测研究人员在软件维护的背景下进行了探索。底层算法(如Koschke[20]和Inoue等人。[17])主要克隆类型的目标检测[5][32]。一般来说,虽然类型1要求内容相似性(即令牌名称的相似性),但类型2侧重于模式相似性。进一步的变化(即附加语句)导致类型3相似性。

图2.MD5例子
克隆类型是根据源代码中可观察到的相似形式定义的。在源代码级别,克隆共享两种形式的相似性:(1)模式和(2)内容。例如,“int temp=0;”和“float f=2;”构成2型克隆对,因为它们遵循相同的模式。在本例中,如果忽略标记名,则共享模式是可见的。将主标记替换为时,两个语句的输出都将为“β β=β;”,这将显示模式的相似性。
我们发现这种方法对于发现工作代码示例非常有用。例如,通过使用类型2克隆检测技术表示语料库中的所有代码片段,我们可以识别实现bubble sortalgorithm的公共代码行(如图1)。由于实现bubble sort的所有代码片段也可能不包含精确的语句,因此我们还考虑使用Type-3克隆检测技术来查找具有稍微不同语句的类似片段。我们的方法基于两个早期的克隆检测思想Brenda Baker[4]和Carter等人[11]的《软件维护》。在下面,我们将分别回顾这些想法。最后,我们讨论了基于这两种思想导出的相似性搜索模型。
基于p字符串的2型相似性检测.在我们的研究中,我们采用了Brenda Baker的参数化模式匹配理论[4]中的参数化字符串(或p字符串)的思想来检测2类源代码克隆。p字符串使我们能够在某些特定形式的不同情况下匹配两个字符串,例如,使用不同的变量名。在此上下文中,字符串引用源代码标记序列。如果两个字符串分别包含字母∑和∏中的普通符号和参数符号,则称为p字符串。利用这种思想,我们可以检测两个字符串是否相似,即p-match,当存在一对一变换函数,它通过操纵参数符号(字母表)将一个字符串转换成另一个字符串。在我们的研究中,由于标记名的不同会对模式挖掘的召回产生负面影响,因此我们使用p字符串的概念来提高我们的召回率。例如,这种方法帮助我们找到实现冒泡排序的常见代码行(如图1),即使它们是用不同的变量名。
利用余弦相似性进行3型相似性测量.最初,Carter等人。[11]提出余弦相似性作为一种可用于3型克隆检测的度量。他们把代码片段转换成小尺寸的向量。向量表示底层编程语言关键字(例如while或return)的出现和频率。卡特等人通过向量之间的角度测量两个代码段之间的相似性。在我们的方法中,我们扩展了卡特等人的原始想法。[11]3类相似性搜索,通过重新定义向量元素。我们不使用编程语言关键字作为向量的内部元素,而是使用pstring。
我们的通用相似性搜索模型.使用所采用的克隆检测技术,我们能够(1)挖掘流行的抽象解决方案(例如,气泡排序实现的编程模式),即使输入数据在语句和标记名上有所不同,并且(2)导出一个相似性搜索模型,以找到与主题最接近的模式。本文将此派生函数称为通用相似搜索模型。我们的搜索模型使用了向量空间模型(VSM),该模型在信息检索中得到了广泛的应用,如[9]。在我们的例子中,向量捕获的是代码片段的p字符串,而不是术语。
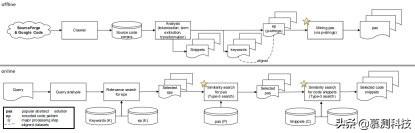
图3.我们发现工作代码示例的方法
x维空间组成向量,例如,向量是sl=,hx是一个字符串x的频率。与传统的信息检索相似,我们也通过计算实体的出现频率来确定其局部和全局的流行程度。我们的加权函数来自TF-IDF[34]。
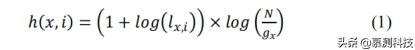
局部频率(用lx,j表示)捕获特定代码段中p字符串的出现次数。全局频率gx表示至少出现一个p字符串的代码段总数,其中代码段总数由表示。
两个模式之间的相似度使用余弦相似度函数来计算,余弦相似度函数用来测量参与向量之间的角度。因此,我们导出了一个支持2型和3型模式相似性的相似性搜索函数。注意,我们的搜索功能的复杂性类似于因特网上现有的代码搜索引擎(例如,ohloh代码),因为两者都使用相同的底层搜索模型,即向量空间模型。时间复杂度是O(nlogn),其中n是匹配的数目。因此,我们的方法的复杂性比其他类似的方法(例如,嗅探 O(n2))要低。

Sl=,hx是p字符串x的权重。
4. 方法图3总结了我们提出的方法的主要在线和离线处理步骤。关键的挖掘和搜索步骤如图3所示。通用相似性搜索模型涵盖了两个关键的相似性搜索步骤(第3节)。脱机进程负责提取代码片段、生成p字符串和相关关键字。最后,检测出流行的模式。在运行时,对于给定的查询,首先标识最相关的p字符串。然后,我们连续两次使用泛型相似性搜索模型,首先找到最佳候选流行模式,然后找到最佳代码示例。
4.1定义
在本节中,我们将定义方法中的主要概念。
定义1.查询被定义为无序集,q={t1,t2,...,tn},其中,每个术语ti可以是数据类型(例如,基元类型、类名或接口)、方法名或一般概念(例如,下载或冒泡排序)。
定义2.代码段定义为从方法体中提取的代码行的有序列表。我们只将代码片段用于最终结果预览。表示语料库中所有片段的集合。
定义3.编码的代码模式epy是所有字符串的集合,这些字符串都是使用p-strings思想相互p-match的:epy ={p1,p2,...,px}.每个epy都由一个唯一的标识符y来标识。对于用Java编写的每一行非空代码,我们添加一个字符串pi。通过对属于epy的所有字符串应用标识符拆分技术,我们提取了一组相关的关键字。给定epy的一组相关关键字称为ep的关键字 epky={k1,k2,...,ky}.K和E分别表示所有epk和eps的集合,其中对应的实体是对齐的。图4提供了ep和epk集合的一些示例。
定义4.抽象(编程)解决方案aps是一组(无序的)编码代码模式{ep1,ep2,…,epy}。在主要的处理步骤中,我们使用代码片段cm的抽象表示(即apsm)。apsm是一组(无序的)编码代码模式,对应于代码片段cm中的代码行。图4给出了一个与MD5哈希代码生成相关的代码片段的aps示例。最后,我们定义了一个流行的抽象解决方案(pas)作为一个抽象解决方案,它的所有项都出现在给定的语料库中超过一定数量的apse中。A和P表示所有apses和pases的集合。当A和C中的对应项对齐时,P仍然是一个独立的集合。
4.2数据分析步骤
在这一部分中,我们将详细描述挖掘流行抽象解决方案(pas)的方法。
4.2.1事实抽取
如图3所示,这种方法至少需要两个数据系列:(1)代码片段和(2)流行的抽象解决方案。虽然代码片段可以从广泛的web爬行和数据收集中提取,但识别流行的抽象解决方案需要不同类型的数据处理。
除了流行的抽象解决方案外,最初的处理步骤填充了语料库的所有部分。唯一的输入数据是从Internet上爬网的源代码数据集。数据集仅包含源代码段。不需要其他信息,例如依赖项的内容(例如库的二进制文件)。我们将每个文件分割成代码片段。对于每个方法体,我们创建一个代码段。

图4.抽象规划解抽取的一个实例
要创建抽象编程解决方案,必须在更高的抽象级别上转换原始内容(代码片段)。我们的方法使用p字符串的思想来创建这个抽象表示,它允许删除不必要的代码细节(例如变量名)。我们利用一个称为编码码模式(ep)的概念,将p字串的概念映射到向量空间模型,而不是原来的基于参数化后缀树的搜索模型[4]。在这种方法中,我们假设所有p-match的pstring共享相同的编码模式。我们还为每个编码的代码模式分配一个唯一的标识符。图4提供了所有内部(即临时)和持久提取事实的示例。在本例中,输入是一个代码段,用它表示有五行代码。首先,我们为每一行代码创建相应的代码。其次,我们将所有提取的eps映射到相应的唯一标识符。通过p字符串[4]进行的Type-2克隆检测有助于我们有效地定位类似的代码模式(即O(1))如图4中的第1行和第5行。对于每个epx,我们维护一个所有相关关键字的全局集,称为epkx。也就是说,每当我们遇到一个epx,我们就从给定的代码行中提取所有关键字并将它们添加到epkx中。图4包括与ep95相关联的关键字的示例。如示例所示,除了当前提取的关键字(如MD5)之外,集合还包括其他相关术语(如SHA),这些术语是通过访问其他使用场景和片段中的相同模式(即ep95)而在前面添加的。最后,灰色区域突出显示了实际的持久输出,它包括三个主要部分:(1)更新的关联关键字集epkx;(2)抽象解apsi;(3)片段i的频率信息li。这三种事实类型构成了我们方法的基线搜索空间。注意,apsi是一个集合,它不包含相应代码段ci的排序信息。利用这种数据表示(如aspi和li),我们可以将向量空间模型和余弦相似性应用于类型3相似性搜索。
4.2.2挖掘流行的抽象解决方案
抽象编程解决方案和相关关键字不足以支持定位工作代码示例。我们需要在语料库中找出流行的解决方案,以提高我们的搜索方法的质量。为了识别流行的抽象编程解决方案,可以使用频繁项集挖掘,例如FPgrowth算法[8]。由于算法的输入是编码的代码模式aps(而不是实际代码),因此输出将是流行的抽象编程解决方案pas。
频繁项集挖掘算法[7]能够在提供的记录集中提取流行模式,记录是一个或多个项。在最简单的形式下,算法需要一个数据集和一个支持值。支持值确定模式在被视为频繁项集之前出现的最少次数。
我们修改了项目集挖掘的概念,称为最大频繁项集挖掘。该变异具有两个特殊性质:(1)考虑最大项集,(2)没有序约束。排序约束的省略为我们提供了一个健壮的挖掘特性,其中代码语句不会干扰模式挖掘过程。此外,这种方法有助于我们在大规模数据上成功地运行该算法。最大属性克服了其他项目集挖掘方法的一些挑战,例如产生指数数量的频繁子项目集的可能性。当需要答案完整性时,在搜索空间中出现子项集是一种威胁。最大项集定义为:给定代码基{e={e1,e2,…,em}中的m个可能元素(即编码的代码模式)和n个代码片段C={ci|ci⊆E,i∈{1,...,n}},PASy,x 是所有可能的信誉良好的代码模式的集合被定义为PRy,x ={el|A⊆C,|A|=y,el∈∩ck∈ack},其中|PRy,x |≥x。一个频繁项集PRy,x是最大的,如果不存在PRy,x ∈PASy,x ,PRy,xPRy,x 。x是最小大小,y是支持(即模式的最小流行度)。
作为数据处理的最后一步,我们运行挖掘算法来提取流行的抽象解。(1)流行的抽象解,以及(2)原始抽象解,(3)它们的出现频率信息和(4)相关关键字,构成了我们方法的完整搜索空间。
4.3搜索和排序工作代码示例
由于在我们的研究环境中获得最佳结果集通常是不切实际的[26],替代方法是提供能够产生高质量排序结果集的检索和排序模型。解决方案的流行性是一个关键的标准,不能忽略它以避免结果集质量差,例如[37]。还有其他因素影响排名过程,例如,文本相似性。对于自由形式的查询,相似性是连续的(而不是二进制的),因此除了简单的过滤和匹配之外,还需要其他解决方案。这些因素之间的权衡使得发现工作代码示例成为一项具有挑战性的任务。在下面,我们将描述如何使用我们的通用相似性搜索模型(第3节)来满足上述问题。对于给定的自由格式查询q=,该方法返回工作代码示例的排序结果集,方法是找到:(1)最相关的编码代码模式,(2)关于第一步的输出的最完整的流行抽象解决方案,以及(3)与第二步的输出最相似的代码片段。
第1步-相关性搜索.在图3中,第一个查询过程通过比较与查询项相关联的关键字来选择与前k个相关的编码模式。也就是说,在这个搜索问题中使用的数据是查询项和ep的关键字K,而输出由编码模式组成。应该注意的是,与q共享关键字的编码码模式ep不会自动包含在候选列表中。为了保持查询和最终发现的代码片段之间的相关性,只选择了前k个匹配项,因为在此步骤之后,查询项不再在搜索过程中显式使用。此外,匹配的eps根据它们与查询的相关性进行排序,这一步将著名的相关搜索方法重用为Web搜索引擎,例如[9]。
第2步-pas选择的相似性搜索.在这个阶段,使用我们的泛型类型3相似性搜索模型来识别前K个流行的抽象解决方案,其中查询由候选编码模式构成,即步骤1的输出。由于使用了基于克隆搜索的方法,现在可以根据与此中间查询的相似性对K个最流行的抽象解决方案进行排序。在这种贪婪的方法中,我们寻找满足大多数候选编码代码模式的最完整的流行解决方案。
第3步-工作代码示例的相似性搜索.在最后一步(图3)中,将发现最佳工作代码示例。上一步的排序结果集根据候选的流行抽象解决方案的完整性和与自由查询的相关性来确定它们的列表。在此阶段,我们迭代候选列表,并使用每个pas作为单独的查询,使用我们的Type-3相似性搜索模型搜索索引代码片段的抽象解决方案。对于每个pas,我们发现最相似(即简洁和完整)的代码片段。斑点片段根据它们与目标的抽象解决方案相似性进行排序。此外,这一步骤是必要的,因为它确保结果在语法和语义上是正确的,这一点至关重要,因为我们的pas挖掘和查询模型忽略了语句的顺序。这种搜索方法的内部结果是每个自由形式查询的二维命中列表。每一行包含与对应的杨树抽象解决方案匹配的排序代码段。因此,虽然每行中的片段高度相似,但它们看起来与其他行中的解决方案不同,因为它们满足不同的流行抽象解决方案。最后,通过选择每个候选的流行抽象解决方案的第一个匹配项,我们为给定的自由格式查询报告发现的工作代码示例。算法1总结了我们方法的三个搜索步骤。

过滤步骤.有些查询包含已知的Java类型(即Java类和接口)。在本例中,我们将丢弃与查询中提到的类型无关的任何代码段。这是一个启发性的,我们通过经验推导来提高返回相关答案的机会。启发式的动机是补偿与我们的类型2相似性搜索相关的问题,在实际搜索过程中忽略标记名。对于每个查询,我们都可以有正确、错误或没有答案。当筛选步骤丢弃所有前K个片段并返回“未找到答案”时,将出现“无答案”状态。的值受在给定可用处理资源的情况下,我们的方法可以在运行时检查筛选的片段数限制。
5. 案例研究为了评估我们方法的可行性、可伸缩性和性能,我们需要一个相当大的语料库。我们还需要一组度量来评估发现的工作代码示例的质量。在这一部分,我们总结了我们的语料库的细节。我们还回顾了查询集和质量评估方法的细节。最后,我们报告我们的发现和观察。
5.1设置
语料库.我们的语料库包括2012年第一季度爬网的源代码。这个数据集涵盖了大约25000个项目。该数据集基于从SourceForge和Google代码的SVN、Git和CVS存储库下载的源代码文件。为了删除数据集中的高级复制,对于由其完全限定名标识的每个可用类名,只选择一个Java文件。在过滤步骤中,我们偏向于最新的修订版,比如出现在trunk目录中的文件。这些带有重复文件的爬网数据最初包括1200万个Java文件。经过过滤步骤,数据减少到300万个Java文件(270万个常规Java类文件和140K个默认包文件)。我们还丢弃了小尺寸的方法块,例如少于五行的代码。最后,我们提取了550万个代码片段。表1总结了我们语料库的主要统计数据。
部署.为了部署搜索引擎的一个实例,我们使用一个基于Linux的系统,它有3.07GHz的CPU(Intel i7)和24GB的RAM。搜索引擎的已部署实例使用单个进程和线程模式,Java虚拟机进程除外,例如垃圾收集。数据处理步骤,例如挖掘和索引,在一天内完成。
查询数据集.作为性能评估的一部分,我们采用了Mishne等人的查询集[26],因为它不限于单个域。原始数据集包括来自6个Java库的7个查询。但是,我们通过包含额外的查询来扩展它。附加的查询来自StackOverflow上发布的编程问题。为了确保数据集反映真实的单词搜索场景,我们从Koders查询日志数据集[21]中选择了候选词。表2总结了由15个查询组成的最终查询数据集。此外,除了目标库(即域)和查询术语(即自由形式查询),表2还包括用于评估检索到的代码示例的相关性的查询的描述。
质量评估-工作代码示例的特性.一般来说,并不是所有满足查询条件的代码片段(例如,共享术语)都可以被视为工作代码示例[16][19]。尽管对于什么构成了一个良好的工作代码示例还没有正式的定义,但是文献中讨论了一些特性(表3)。首先,工作代码示例应该是正确的,并且与查询相关。代码示例应该包括实现底层编程问题所需的强制步骤。其次,工作代码示例应该简洁[10][23][36]、自包含[10]、完整[19]、易于理解和重用[15][26][37]。

表1.我们语料库的特点

表2.扩展查询集

表3.工作代码示例的特性
表3简要总结了用于识别高质量工作代码示例的特性和措施。在本文中,我们从正确性、简洁性和完整性的角度来评估性能。我们选择这三个特征,因为它们可以客观地进行评估。
5.2案例研究结果
本节介绍并讨论我们两个研究问题的结果。对于每个研究问题,我们提出问题背后的动机、分析方法和我们的发现。
RQ1–什么是发现工作代码示例的最佳排名模式?
动力.在这篇文章中,我们重点讨论了识别工作代码示例的问题。Spotting强调的是第一个返回答案的质量。因此,在评估识别方法时,诸如召回等绩效指标并不是主要关注的问题。这一要求将发现工作代码示例研究与其他相关代码搜索问题区分开来。因此,我们的目标是找到用于发现工作代码示例的最佳排序模式。一个理想的排名将其最佳答案放在热门榜的首位。以前,解决方案的流行度被考虑在代码搜索的上下文中进行排名(例如,[10][26][37])。直觉是,解决方案的受欢迎程度越高,最终用户接受的机会就越高。除了流行之外,我们还探讨了相似性和大小因素对识别工作代码示例的影响。
方法.对于这个研究问题,我们研究了一组潜在的排序模式的性能。我们可以根据代码示例与给定查询的相似性、流行抽象解决方案的流行程度以及流行抽象解决方案的大小对其进行排序。我们总共考虑了表4中总结的五种排名模式。相似性是基于在我们的方法产生的排名结果集中的点击位置。换句话说,是我们内在的排名计划在第4节中描述的。抽象解的普遍性是通过挖掘步骤得到的,即pas的支持值。大小是根据基本pas的长度来测量的。正如我们前面在第5.1节和表3中所讨论的,高质量的工作代码示例应该具备一些特性。我们从正确性、简洁性和完整性方面评估每个排名模式的性能。测量值选自表3。
正确性。只有满足表2中给定查询的描述,我们才认为答案是正确的。注意,由于过滤步骤的原因,我们的定位方法可能会错误地回答问题或返回“无答案”(第4节)。一般来说,我们宁愿不回答问题,也不愿返回错误的答案,以免对最终用户的信任产生负面影响。然而,在结果集中出现过多的“无应答”情况会降低搜索服务的感知质量。在本研究中,当我们从正确性的角度评估模式时,我们会区分不正确和“没有答案”的情况。我们计算正确答案与(1)个查询和(2)个已回答查询总数的百分比。两个相关的度量是query coverage()和precision()。一个好的排名模式应该能够从两个角度表现良好。
简洁完整。正确的答案可能会遗漏一些小任务,例如变量初始化或错误处理,因此,不仅要测量正确性,还要测量简洁性和完整性。
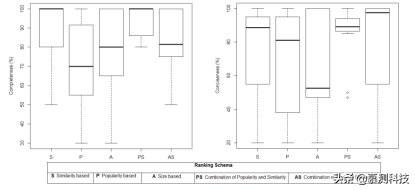
图6.完整性和简洁性措施概述

表4.研究的排名模式
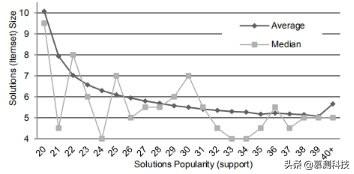
图5.我们流行的抽象解决方案的平均大小
为了能够度量简洁性和正确性,我们需要两个列表,涵盖每个编程问题(一个查询)需要完成的必要和补充任务。这些任务是为我们的查询集预定义的(表2)。必要的任务是根据表2中每个查询的描述派生的。这些补充任务与一些小的编程步骤有关,比如错误处理或变量声明。我们从原始查询集[26]提供的最佳答案或StackOverflow上排名靠前的答案中为每个查询提取这些任务,并通过完备性手动测量丢失的次要任务,例如[10][19]。完整性定义为已处理的任务数除以任务总数。最后,对于每个正确答案,我们都手动测量简洁性。简洁性定义为不相关的代码行数除以总行数。与已识别任务无关的代码行是不相关的。我们使用Wilcoxon符号秩检验(一种非参数检验)来确定观察结果是否存在显著差异。
结果.表4总结了使用覆盖率和精度度量的正确性研究结果。结果表明,只有基于大小和相似度相结合的排序方案在这两种度量中都表现不佳。基于流行度的排序能够成功地回答更多的问题,而基于相似度和基于大小的模式具有更好的精度。最佳精度是通过通俗性和相似性相结合来实现的。这种组合也比仅使用相似性(即)回答更多的问题。在我们的分析中,我们观察到流行和大小之间存在着一种关系。图5总结了我们的语料库中15856377个流行的抽象解决方案的平均大小。抽象解决方案按其流行程度分组,流行程度由解决方案在语料库中出现的次数(即支持值)来衡量。结果表明,随着受欢迎程度的增加,尺寸减小。除前几组外,平均大小保持在6到5之间的窄范围内。这种行为部分地描述了基于大小的排名模式(例如,AS)的较低性能。
接下来,我们从完整性和简洁性的角度研究了排名模式的性能。图6显示了我们的结果摘要。具体来说,我们从正确性评估阶段,即P和PS,对幸存的模式进行了研究,结果表明,从完备性和简洁性两个角度来看,流行度和相似性的结合优于纯流行度排名模式。Wilcoxon符号秩和检验也证实,在显著性水平为0.05时,改善具有统计学意义。
RQ1.流行性和相似性的结合导致了一个更好的用于发现工作代码示例的排名模式。
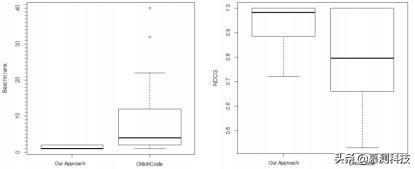
图7.最佳命中等级和NDCG研究摘要-比较我们的方法(PS等级模式)和Ohloh代码
RQ2–我们的方法是否能胜过互联网规模的代码搜索引擎?
动力.本研究的最终目标是提出一种搜寻方法,以侦测工作程式码范例,提升网际网路规模程式码搜寻引擎的效能。在这个研究问题中,我们将我们的方法与Ohloh代码(以前称为Koders)进行比较,Ohloh代码是一个公开的互联网规模的源代码搜索引擎。
方法.我们从发现问题的角度来评估这两种方法。理想的定位方法是将最佳工作代码示例放在列表的顶部。在识别工作代码示例的背景下,我们研究了适合于评估的两个度量。我们比较最佳答案的等级。具体来说,我们在给定的前k个点击率中找到最佳答案的排名。此评估方法显示最终用户应该查看/浏览多少次点击(即代码片段),直到她在排名结果集中找到最佳答案。一个好的方法把它最好的答案放在最前面。最佳答案是在每个方法的前k个点击中独立选择的。最好的答案是使用RQ1中使用的相同度量来确定正确性、完整性和简洁性。这是必要的,也是合理的,因为每种方法都有自己的语料库。k的初始值是10,即Ohloh代码默认结果集大小。然而,对于Ohloh代码的研究,在前10次点击中有一些查询没有正确答案。在这种情况下,我们将k增加10,直到到达一个至少有一个正确答案的窗口。
我们还使用归一化贴现累积增益(NDCG)[24]来研究性能。NDCG是目前信息检索领域最先进的方法之一。标准化的折现累积增益评估排名模式的排名能力,例如,高度相关的答案是否出现在命中列表的顶部。与其他流行的测量方法(如MAP[24])相比,NDCG的主要优势在于,当所研究的数据存在异质性时,其结果具有可比性。它可以比较使用不同数据集部署的两个搜索引擎或排名架构。数据稀缺等环境问题对NDCG的影响比K精度等其他度量指标要小。我们在表2中计算了每种查询方法的NDCG。为了保证算法的正确性、完整性和简洁性,我们考虑了RQ1中所研究的三个相同的度量,为每个方法的前k次点击分配了相关值。
结果.图7总结了我们对排名前k的最佳答案的研究。结果表明,我们的方法在使用可用资源方面优于Ohloh代码。我们的方法使其高质量的答案更接近排名结果集的顶部。我们的方法将其最佳答案列为最坏情况下的第二个攻击。图7还总结了我们的NDCG观察结果。与前面的方法类似,我们的方法优于Ohloh代码。最后,Wilcoxon符号秩检验证实,观察到的改善具有统计学意义。
RQ2.我们的分析表明,我们的方法优于Ohloh代码,研究的互联网规模的代码搜索引擎,发现工作代码的例子,通过一致地把最好的可用答案在两个热门点击。
5.3有效性威胁
与我们的绩效评估研究相关的有效性存在一些威胁。对外部有效性的威胁涉及推广我们的结果的可能性。我们确定了两个对我们研究的外部有效性的主要威胁。第一个问题是输入数据的差异。Ohloh代码和我们的方法使用不同的数据集。然而,两者都涵盖了从互联网上爬网的Java开源项目的相似数量,第二个关注点是查询数据集。我们选择了不限于单个应用程序域的最新查询数据集。由于查询的数量比之前的研究要少(例如,10到20个查询[2][33][36]),我们随机添加了Stackoverflow上发布的编程问题的查询。最终的查询数据集由15个查询组成。我们还通过选择从Koders查询日志数据集中提取的术语来确认查询术语反映了真实的单词查询[21]。尽管我们试图解决这两个问题,但它们仍然威胁着我们研究的有效性。在我们的研究中,我们考虑了正确性、简洁性和完整性度量来评估发现的工作代码示例的质量。我们在先前对代码示例质量的研究的基础上选择了这些度量。然而,这些措施并没有取代用户研究等其他评价方法。
6.相关工作在文献中存在各种形式的软件工程推荐系统[30]。在这一节中,我们回顾了一个子集的研究集中在源代码搜索。我们根据它们的输出类型分别报告相关工作。
6.1抽象解决
针对API使用场景,提出了多种挖掘和搜索方法。它们的主要输出是一个方法调用序列。在某些情况下,序列还包括RQ2。我们的分析表明,我们的方法优于Ohloh代码,研究的互联网规模的代码搜索引擎,发现工作代码的例子,通过一致地把最好的可用答案放在两个热门点击。信息,如对象实例化步骤。MAPO(Xie和Pei[38])在API使用的上下文中建立了基于频繁模式挖掘的代码搜索基线。Acharya等人。[1]扩展了此方法,包括API静态跟踪和部分序挖掘。UP Miner[37]由Wang等人提出。作为马普的继承人[38]。它将聚类和序列挖掘相结合,以发现重复出现的API指纹序列(即方法调用令牌)。在这个区域,嗅探(Chatterjee等人。[12])是少数几个通过利用最长的公共子序列挖掘和编程文档(即Javadoc)直接解决自由形式查询问题的模型之一。但是,SNIFF需要完整的编译单元(例如外部库和文档)。Mishne等人的PRIME[26]方法通过将模式挖掘任务延迟到运行时来遵循惰性方法。偷工减料早先在马坡镇、SnIFF和PARSEWEB[36 ]中进行了研究。Prime从方法调用序列中提取部分时间规范,以找到可能的解决方案。Prime是用额外语义分析扩展PARSEWEB的方法。
抽象的解决方案帮助我们识别编程问题的高级步骤,但它们不能替代源代码示例[10]。尽管可以使用主动簿记为每个抽象解决方案报告相应的代码片段,但代码片段没有排名。当抽象解决方案中有大量不同质量级别的代码片段(例如,多达17000个片段[26])时,这对于大规模实验来说是有问题的。我们的研究通过直接定位和排序代码示例来解决这个问题。此外,我们的方法不仅限于API指纹。
6.2合成源代码
另一种方法是从抽象解决方案合成源代码。PARSEWeb(Thummalapenta和谢(36))回答了“源到目的地”模板的编程问题。答案是满足给定问题的合成代码片段。为了确定回答给定问题的最佳方法,PARSEWeb模型方法调用序列包括数据流信息作为有向无环图和利用最短路径发现算法。最终的综合答案是根据它们的受欢迎程度和规模进行排名的。PARSEWEB提高勘探者(曼德林等)。[23])通过考虑其他信息来源(即代码样本)的方法,因为探矿者仅依赖于API定义。最近,Buse和Wiemer[10]将挖掘应用于从数据流和方法调用序列创建的图模型。Buse和Wiemer[10]的研究在综合源代码示例方面提供了有希望的结果,但是它仍然不能优于人工编写的代码示例。我们的研究提出了一种解决方案,可以从开发人员编写的源代码中发现工作代码示例。
6.3代码片段
Strathcona(Holmes和Murphy[15])使用结构匹配来查找与API使用问题最相似的代码示例。该方法的核心是通过继承链接、方法调用和类型使用之间的相似性度量,使用六种启发式方法进行结构比较。排名前10位的代码示例是根据它们在生存更多启发式方法方面的成功程度进行排序的。XSnippet(Sahavechaphan和Claypool[33])通过使用图形挖掘技术改进了Strathcona。目标是减少不相关答案的数量。但是,它只回答对象实例化问题。为了提高排名,采用了流行度、规模和上下文方面的组合。
正如Chatterjee等人所讨论的。[12],当前返回代码示例的方法仅限于(1)API使用场景和(2)期望最终用户知道必须使用哪些类和方法来完成给定的开发任务。它们依赖于特定的查询模板,例如单个API名称(例如,UpMeNever[37])、“源-目的地”(例如,PARSEWeb[36])或不完整的程序(例如Prime[26])。自由表单查询[12]通过允许最终用户使用各种术语(包括类和方法名称)来表示查询,从而放宽了这一条件。嗅探是最接近我们的方法。但是,它的输出是一个排序的抽象解决方案列表,而不是代码示例。它的时间复杂度高,在运行时(即,O(n2),其中n是命中的数量),从而降低了它的可用性与大型语料库的实际应用。最后,它仅限于查找已知api的代码示例,并且需要一个完整的编译单元,包括它们的文档。
也有一些研究提出了对Internetscalecode搜索引擎的改进。Reiss[31]提出了基于语义的代码搜索的思想,它利用测试用例等多种资源来提高代码搜索体验。McMillan等人。[22]方法(Portfolio)支持程序员查找相关函数及其使用场景。投资组合搜索是基于自然语言处理和网络分析算法,如调用图上的PageRank。与Koders的比较表明,Portfolio在找到给定编程任务的相关函数方面更好。我们的研究重点是寻找工作代码示例。与我们的研究最接近的是Bajracharya和Lopez[2]。他们提出了一种解决方案,通过利用API指纹提高检索方法在召回方面的质量。在我们的研究中,我们通过寻找更好的例子来提高搜索方法的质量。
7.结论可用的Internet规模的代码搜索引擎不支持有关代码示例的良好查询[10][16][26]。在本文中,我们使用代码克隆检测模型来支持识别工作代码示例。我们的方法使挖掘编程模式和搜索所有类型的语句(例如,控制流、数据流和API指纹)的相似性成为可能,而无需使用图形化模型来提高可伸缩性和效率。我们的方法支持自由形式的查询。这与大多数早期的工作不同,这些工作期望部分代码、API名称或数据流信息作为查询。我们的方法的时间复杂度类似于互联网规模的代码搜索引擎。我们以约25000个开源Java项目为代表,研究了该方法的可行性。我们首先确定在我们的研究背景下的最佳排名方法。我们发现流行度和相似性的结合优于文献中的主流排序方法。其次,我们通过与Ohloh代码(一个互联网规模的代码搜索引擎)的比较来研究我们的方法的性能。我们的研究表明,在寻找工作代码示例方面,我们的方法明显优于Ohloh代码。因此,我们的方法可以通过现有的代码搜索引擎在内部进行修改,以提高其在识别工作代码示例中的性能。作为近期的工作,我们计划研究我们的方法对其他流行编程语言的可行性。我们还计划发布我们的研究作为一个独立的搜索引擎。
8.致谢本文由南京大学软件学院2019级硕士刘满翻译转述。
感谢国家重点研发计划(2018YFB1403400)和国家自然科学基金(61690200)支持!
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






