r语言做数据的描述性统计分析(R语言学习笔记六)
导语:最近一直在学习一份R语言资料,是斯坦福大学的老师写的。可以直接在线学习,https://web.stanford.edu/class/bios221/book/index.html。里面有配套的R代码,小编在这里写一点读书笔记。本章介绍常见的离散分布及其应用。
1. 伯努利试验和二项分布1.1 定义
若试验E只有两个结果A和Ā,概率分别为p和1-p,则称E为伯努利试验,将E独立重复n次称为n重伯努利试验。最典型的伯努利试验就是抛硬币的例子,比如抛3次硬币,观察到2次正面向上的概率为:(下图)。

用X表示n重伯努利试验中A发生的次数,则称随机变量X服从二项分布,记为X~b(n, p),其分布律为:

二项分布的期望和方差分别E(X) = np和D(X) = np(1-p).
1.2 R语言实例
在R中常用的分布通常有对应的4个函数,分别以p(probobility,概率),d(distribution,分布),r(random,随机数),q(quantile,分位数)这四个字母开头。以二项分布为例,有如下4个函数:

pbinom(q, size, prob): 计算累积概率
dbinom(x, size, prob): 计算取某个值x的特定概率
rbinom(n, size, prob): 产生n个b(size, prob)的二项分布随机数
qbinom(p, size, prob): 分位数函数
其中size和prob两个参数分别表示伯努利试验的次数和每次试验成功的概率,即分别对应二项分布中的两个参数n和p。假如碱基突变的概率为5×10-4,我们模拟10000个位点发生突变的碱基数,并绘制条形图。
> simulations = rbinom(n = 300000, prob = 5e-4, size = 10000)
> barplot(table(simulations), col = "lavender")

再比如要生成10000个服从b(100, 0.2)的随机数,画出概率密度直方图,并添加正态分布拟合曲线。
> library(dplyr)
> library(ggplot2)
> tibble(x = rbinom(10000, size=100, prob=0.2))%>%
ggplot(aes(x= x))
geom_histogram(aes(y=..density..))
stat_function(
fun =dnorm,
args =list(mean = 20, sd = 4),
color ="red"
)

上述代码中使用了一种特殊的数据框tibble,这是R语言大神Hadley Wickham在tidyverse包中新定义的一种数据类型,是弱类型的data.frame,与data.frame有相同的语法,但使用起来更加灵活。如果要了解更多内容,可以参考R for Data Science这本书
(https://r4ds.had.co.nz/)。
模拟数据的期望和方差分别为20和0.4,根据中心极限定理,当n取很大值的时候,二项分布趋近于正态分布。因此我们的模拟数据能够与上图中的正态分布N(20, 0.4)拟合。
2. 泊松分布2.1 定义
泊松分布适合于描述单位时间内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,DNA突变的碱基个数等等。泊松分布只有一个参数λ,记为X~π(λ),其分布律为:
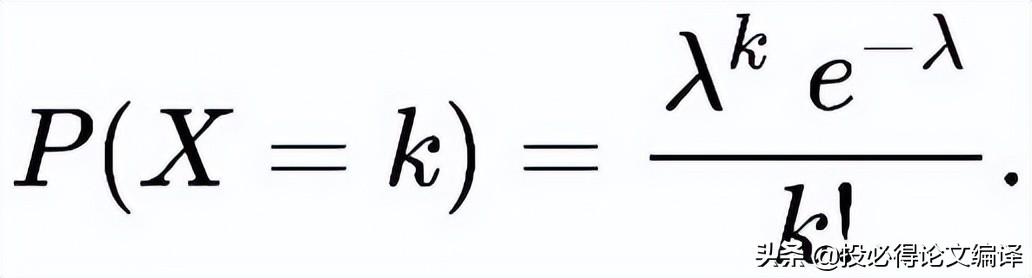
泊松分布的期望和方差都等于λ,即E(X) = D(X)= λ。当二项分布的n较大时,可以用泊松分布逼近二项分布,其中λ = np.
2.2 R语言示例
我们分别生成1000个服从二项分布b(10000, 0.01)和泊松分布π(100)的随机数,并画图。
> library(tidyverse)
> tibble(x = rbinom(1000, size = 10000, prob =0.01), y = rpois(1000, 100)) %>%
pivot_longer(cols = c(x, y)) %>%
ggplot(aes(x= value))
geom_density(aes(col = name))
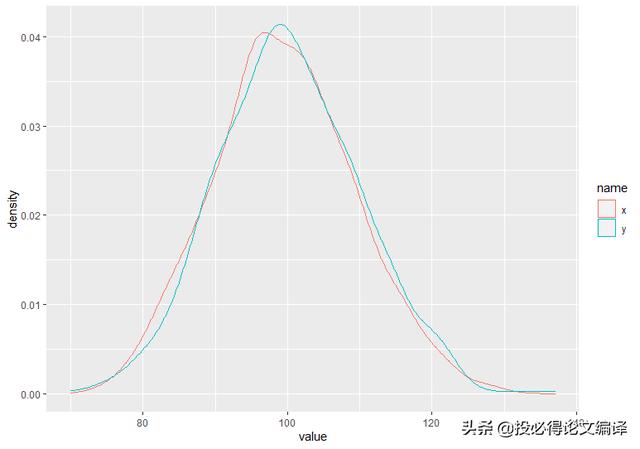
这里先解释一下上述代码,首先我们创建了一个tibble类型的数据框,包含x和y两列,分别服从b(10000, 0.01)和π(100)。再用pivot_longer()函数将数据框转换成长数据,最后作出直方图。
从图中我们可以看到两条曲线能够很好地重合,这也说明了我们上述的结论正确,即泊松分布可以看做是n很大p很小的二项分布。
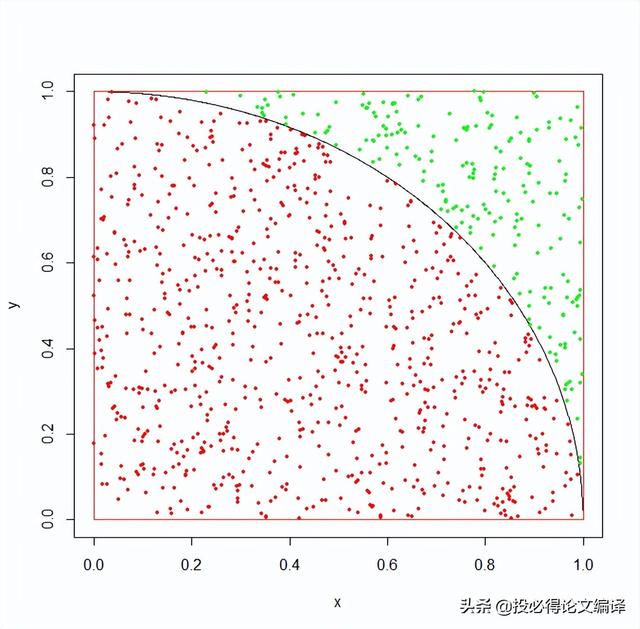
3. 蒙特卡洛方法(Monte Carlo)蒙特卡洛方法是指通过产生大量的随机数,来用于数值统计计算以获得问题的近似解。一个经典的例子是用蒙特卡洛模拟计算圆周率π,如下图所示,在正方形内产生足够多的随机点,这些点落在圆内的概率就是圆面积和正方形面积的比值,所以落在圆内的点的个数比上所有的点的个数(在正方形内的点)就等于落在圆内的概率。据此即可计算出π = 4*圆面积/正方形面积,下面用代码说明。
> calpi <- function(n){
x <- matrix(runif(2 * n), ncol = 2)
return(4*mean(rowSums(x^2)<=1))
}
> pi_new <- c()
> for (i in 1:1000){
pi_new[i] <- calpi(i)
}
> plot(pi_new)
> abline(h=pi, col = 2 )

可以看到当随机数的个数n越来越大的时候,通过蒙特卡洛计算出的π逐渐接近真实值。
最后再看一个例子,假如X~π(0.5)中,X样本数为100。我们想知道X≥7的概率。我们当然能够用理论公式计算,p = 1- p(X≤6) = 1-。但这样计算显然是很复杂的,我们可以用蒙特卡洛模拟,生成大量的符合泊松分布的样本,然后计算概率。具体代码如下:
> maxes = replicate(100000, {
max(rpois(100, 0.5))
})
> table(maxes)
maxes
1 2 3 4 5 6 7
8 23430 60446 14469 1530 110 7
> mean( maxes >= 7 )
[1] 0.00011
最后算出的p值为0.00011,也就是在这些样本中几乎不可能观察到大于7的值。蒙特卡洛模拟的限制在于其精度≤1/n,其中n表示产生的随机数。这也就是说要想得到足够精确的结果,必须产生足够数量的随机数,也对计算机的性能提出了很高的要求。
R语言学习笔记系列R语言学习笔记(二)
R语言学习笔记(三)——实用的内置函数
R语言学习笔记(四)—pheatmap
R语言学习笔记(五)——曼哈顿图
手握这些网站,分分钟搞定R语言自学
关注【投必得论文编译】获取每天最新科研/论文写作干货!
得SCI写作神器大集合!- 科研笔记神器:拆书神器,一分钟建立一个知识图谱
- 一入科研深似海,这些科研工具让你如有神助
- PDF阅读器具备谷歌翻译功能了,效率值拉满
- 学术写作 - 文献综述高分模版
- SCI英文润色软件推荐-StyleWriter,一款可定制的润色工具

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com