java按日期分割大文件(指定大小分组压缩文件夹里面的文件案例)
今天给大家分享一个自己写的ava实战的小案例,主要功能是实现指定一个文件夹,然后分组压缩里面的文件。其实这个案例还是有一定用途的,比如日志文件夹里面有几千个文件,如果我需要给每个压缩包指定10M,把整个文件夹里面的日志文件都进行压缩,这个案例就能够用得上了。废话少说,直接上代码。我这边采用的是最基本的控制台程序,主要还是代码的逻辑有一定的借鉴意义。说明:暂时未考虑文件夹里面还有文件夹的情况。
二、代码示例- 新建FileModel.java 实体
主要指定文件名以及文件大小,方便分组的时候使用。
public class FileModel {
public FileModel(String name, double fileSize) {
this.name = name;
this.fileSize = fileSize;
}
// 文件名
public String name;
// 文件大小KB
public double fileSize;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getFileSize() {
return fileSize;
}
public void setFileSize(double fileSize) {
this.fileSize = fileSize;
}
}
- Main.java 代码:
文件夹中文件分组大小采用了递归的方式。为了实现效果代码都放在了Main.java里面。具体代码都有注释,直接看注释就行。
private static final double FILE_SIZE=5500; // 指定分组压缩的大小 550KB
private static final String PATH="D:\Test; // 指定要处理的文件夹
public static void main(String[] args) {
List<FileModel> list = getFiles(PATH);
HashMap<Double, List<FileModel>> map = new HashMap<>();
getArr(list,FILE_SIZE,map);
if(map.size()>0)
{
for (Double aDouble : map.keySet()) {
List<FileModel> fileModels = map.get(aDouble);
batchZipFiles(fileModels,PATH "\" aDouble.toString() ".zip");
}
}
System.out.println(map);
}
// 递归方式实现文件分组
private static void getArr(List<FileModel> list, double fileSize,Map<Double, List<FileModel>> map) {
List<FileModel> listAdd = new ArrayList<>();
if (list.size() > 0) {
for (FileModel fileModel : list) {
if (listAdd.size() == 0) {
listAdd.add(fileModel);
} else {
if (listAdd.stream().mapToDouble(FileModel::getFileSize).sum() < fileSize) {
listAdd.add(fileModel);
if(listAdd.size()==list.size())
{
map.put(listAdd.stream().mapToDouble(FileModel::getFileSize).sum(), listAdd);
}
} else {
// 取差集
list = list.stream().filter(item -> !listAdd.contains(item)).collect(Collectors.toList());
map.put(listAdd.stream().mapToDouble(FileModel::getFileSize).sum(), listAdd);
getArr(list,fileSize,map);
break;
}
}
}
}
}
//读取文件夹获取里面文件的名字尺寸 不考虑嵌套文件夹
private static List<FileModel> getFiles(String path) {
List<FileModel> files = new ArrayList<FileModel>();
File file = new File(path);
File[] tempList = file.listFiles();
if (tempList != null && tempList.length > 0) {
for (File value : tempList) {
if (value.isFile()) {
// System.out.println(value.getName() ":" getFileSizeString(value.length()));
files.add(new FileModel(
value.getName(), getFileSizeKB(value.length())
));
}
}
}
return files;
}
// 获取文件大小KB
private static double getFileSizeKB(Long size) {
double length = Double.parseDouble(String.valueOf(size));
return length / 1024.0;
}
// 返回文件大小尺寸
private static String getFileSizeString(Long size) {
double length = Double.parseDouble(String.valueOf(size));
//如果字节数少于1024,则直接以B为单位,否则先除于1024,后3位因太少无意义
if (length < 1024) {
return length "B";
} else {
length = length / 1024.0;
}
//如果原字节数除于1024之后,少于1024,则可以直接以KB作为单位
//因为还没有到达要使用另一个单位的时候
//接下去以此类推
if (length < 1024) {
return Math.round(length * 100) / 100.0 "KB";
} else {
length = length / 1024.0;
}
if (length < 1024) {
//因为如果以MB为单位的话,要保留最后1位小数,
//因此,把此数乘以100之后再取余
return Math.round(length * 100) / 100.0 "MB";
} else {
//否则如果要以GB为单位的,先除于1024再作同样的处理
return Math.round(length / 1024 * 100) / 100.0 "GB";
}
}
/**
* 压缩指定文件夹中的所有文件,生成指定名称的zip压缩包
*
* @param list 需要压缩的文件名称列表(包含相对路径)
* @param zipOutPath 压缩后的文件名称
**/
public static void batchZipFiles(List<FileModel> list, String zipOutPath) {
ZipOutputStream zipOutputStream = null;
WritableByteChannel writableByteChannel = null;
MappedByteBuffer mappedByteBuffer = null;
try {
zipOutputStream = new ZipOutputStream(new FileOutputStream(zipOutPath));
writableByteChannel = Channels.newChannel(zipOutputStream);
File file = new File(PATH);
File[] tempList = file.listFiles();
List<String> fileList = list.stream().map(FileModel::getName).collect(Collectors.toList());
File[] addList=new File[fileList.size()];
assert tempList != null;
for (File file1 : tempList) {
if(fileList.contains(file1.getName()))
{
long fileSize = file1.length();
//利用putNextEntry来把文件写入
zipOutputStream.putNextEntry(new ZipEntry(file1.getName()));
long read = Integer.MAX_VALUE;
int count = (int) Math.ceil((double) fileSize / read);
long pre = 0;
//由于一次映射的文件大小不能超过2GB,所以分次映射
for (int i = 0; i < count; i ) {
if (fileSize - pre < Integer.MAX_VALUE) {
read = fileSize - pre;
}
mappedByteBuffer = new RandomAccessFile(file1, "r").getChannel()
.map(FileChannel.MapMode.READ_ONLY, pre, read);
writableByteChannel.write(mappedByteBuffer);
pre = read;
}
}
}
assert mappedByteBuffer != null;
mappedByteBuffer.clear();
} catch (Exception e) {
} finally {
try {
if (null != zipOutputStream) {
zipOutputStream.close();
}
if (null != writableByteChannel) {
writableByteChannel.close();
}
if (null != mappedByteBuffer) {
mappedByteBuffer.clear();
}
} catch (Exception e) {
}
}
}
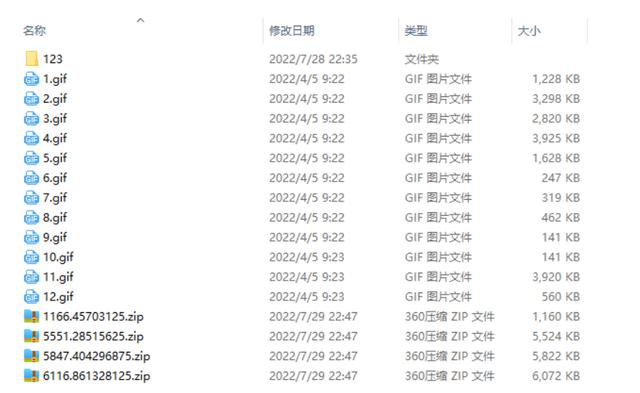
最终运行效果如下
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com





