量化回测工具哪个好用(问卷数据清洗与分析的几点经验)

问卷调查作为最常用的社会研究方法之一,广泛的应用到各个类型的用户调研项目中。经历了问卷设计这第一道关卡后,面对回收后的大量数据,你是否也有以下的困惑
- 回收后的数据是真实的吗?
- 用什么工具处理问卷数据最高效?
- 如何分析和解读问卷数据?
一.工具:该用什么来处理数据?
其实进行基础的描述性统计与交叉分析时,Excel和Spss这两款工具都有相对应的功能可以实现,大家可以根据平时的使用习惯自行选择。
在实际工作中,这两个工具常结合起来使用。Spss的优势在于,两个视图查看数据比较方便、可以撰写语法来实现数据批量处理;Excel的优势在于,图表的可视化更丰富、更改图表外观非常便捷。因此,通常先使用Spss来进行数据清洗和分析,再导出到Excel中对图表的格式进行编辑。
二.清洗:如何对数据进行清洗?
线上问卷投放成本低、回收时效高,但由于难以监控用户填答的过程,致使问卷中常隐藏着一些不真实的数据,因此,回收问卷后的第一步,就是给数据做清洗以保证数据尽可能的真实有效。数据清洗包含三个方面,其一,规范数据视图(主要针对Spss);其二,清理无效样本。其三,对特殊题型进行处理。
1.数据视图规范化
数据视图规范化是一个经常被忽视的环节,虽然它不对数据结果产生直接的影响,但是前期对数据视图做好规范化处理有利于减少后续数据分析、语法撰写出现失误的概率,也就是说,它是一个微小、但却可以提升工作效率的步骤。那么,如何对Spss的数据视图进行规范化呢?
由于Spss中的变量视图与数据视图相关联,因此只需对变量视图的11列逐一进行调整、规范化即可。具体参考步骤如下
- 名称:将名称列与原始问卷中的编码进行一一对照,检查是否有误
- 类型:将类型列与原始问卷中的题型进行一一对照,选择题需为数字、填空题需为字符串
- 宽度:将同类题型变量取值所占有的宽度调成一致以方便后续查看
- 小数:根据题型进行调整,选择题的小数需为零,填空题的小数依据题目具体分析
- 标签:将标签调整成直观易懂的描述;将名称列合并到标签列中以便后续查看
- 值:将值列与原始问卷中的选项进行比较,检查是否有误
- 缺失:逻辑跳转题的“未选择”会被计为零值,不利于后续的交叉分析;可对照原始问卷中的逻辑跳转设置,将该跳转题零值剔除(对于缺失值的处理,因问卷系统不同而有差异,此处以京东limesurvey为例)
- 列:将同类题型的数据视图中的列宽调成一致以方便后续查看
- 对齐:将数字类型右对齐、字符串类型左对齐
- 测量:将定类变量设置成名义;将定序变量设置成有序;将定距定比变量设置成标度
- 角色:一般系统默认为为输入,代表自变量

变量视图规范化可参考此示意图
2.清理无效样本
清理无效样本遵循两个原则,从整体到部分、从一维到二维。
首先,对问卷样本整体进行处理。
① 根据填答完整性处理
- 首先需要剔除未完整填答必答题的样本,即未完整填答问卷的样本。其次,为尊重用户隐私,我们会将一些敏感问题设置为非必答题,这时可以根据项目需求来决定是否需要剔除非必答题未完整填答的样本
② 根据提交时间处理
- 提交问卷的时间同样重要,有时正式投放问卷前,调研员会对问卷进行测试填答,有时样本填答问卷的日期超出了计划日期,因此需要剔除问卷提交时间早于和晚于问卷投放时间的样本
③ 根据填答时间处理
- 填答问卷时长过短或过多的样本均被视为无效样本,因此我们需要剔除少于最低填答时间(一般情况下,填答每道问题需要5秒,因此最低填答时间即为5秒*题目数量)和填答时间过长(一般情况下,问卷填答时间不超过30分钟)的样本
其次,对问卷各部分进行处理。
通常情况下,问卷设计会分为三部分。
- 甄别部分:此部分会设置一些题目来甄别参与问卷调查的用户是否为我们的目标样本
- 主体部分:此部分会根据项目的研究内容测量用户行为、用户态度
- 属性部分:此部分会获取用户的人口属性(人口属性(性别、年龄、婚姻、城市)、社会属性(学历、职位、个人月收入、家庭月收入)以便做用户画像
① 甄别部分处理
- 剔除不符合甄别条件的样本。根据项目需求,问卷中可能会设置一些甄别调研目标用户的题目,如拟对使用过某产品的用户进行问卷调查,那么在问卷设计时则会用一道甄别题来询问“您是否使用过该产品”,若该用户选择“否“,则需要剔除这类不符合甄别条件的样本
② 主体部分处理
- 剔除连续性回答样本。连续性回答有两种情况,其一,选择同一选项过多:如该问卷有30道题,但某样本选择A选项有25道题,则将该样本视为连续性回答样本,需剔除;其二,填答呈现某种规律性:如某样本在填答中呈现“A-B-A-B”或”A-B-C-D”等某种规律,则被视为规律性填答的样本,需剔除
- 剔除不符合固定填答逻辑的样本。在问卷设计中,有一类题组前后两道题(几道题)有关联的逻辑,如选择前一道题A的人不能选择后一道题的B,此时则需要剔除互斥题矛盾的样本
- 剔除未通过陷阱题的样本。为了确认用户是有在认真填答问卷,有时会在问卷主体部分穿插一道“常识题“,如”中国的首都是哪里“,若用户选择非北京的城市,则会把该样本剔除
③ 属性部分处理
- 各个属性题组的内部数据清理,剔除人口属性、社会属性、站内属性三个属性题组内部数据存在矛盾的样本。如人口属性内部(性别、年龄、婚姻、城市),年龄与婚姻可能存在矛盾,20岁以下的女子、22岁以下的男子婚姻状态不能为已婚;社会属性内部(学历、职业、个人月收入、家庭月收入),个人月收入不能大于家庭月收入
- 各个属性题组间的数据清理,将人口属性、社会属性、站内属性进行两两比较,剔除题组间数据存在矛盾的样本。如人口属性的年龄与学历之间可能存在矛盾,小于18岁的群体一般情况下不会拥有本硕博学历
④ 各个部分间处理
- 将问卷甄别部分、主体部分、属性部分进行逐一比较,剔除各部分间数据存在矛盾的样本。比较原则,将题目数量较少的部分与题目数量较多的部分进行比较。每一部分逐一比较虽然需要花费一定的时间,但为了确保样本是真实有效的,这个步骤是必不可少的
3.对特殊题型进行处理
问卷中时有一些文本题,如选择题中的“其他,请注明“选项或填空题。
在处理文本题时,有两种情况,其一,回码,即当文本题的填答内容可量化或与原始选项可合并时,需将文本题的填答内容转置成可计算的数值,并删除文本题的填答内容。如某选择题为“请问您使用过下列哪些网购平台“,即便选项中有”京东“,但用户没有注意到该选项,而是在”其他,请注明“选项中填写了”京东“,此时就需要对该样本的填答情况进行回码,将之纳入到京东选项下,并删除文本填答内容。
其二,重新编码,若文本题的填答内容不可回码,需要进行重新编码,并记录到编码簿中。仍然以“请问您使用过下列哪些网购平台“这道题为例,若用户在”其他,请注明“中填写了未在既有选项中出现的答案,则需要对该答案进行重新编码,并做记录。
三.分析:如何对问卷数据进行基础分析?
1. 常用问卷数据分析与解读维度
问卷数据分析时,最常使用的分析方法为频数分析、描述分析、交叉分析。
① 频数分析
- 总体频数
拿到问卷数据后,首先可以将每道题各选项的频数按降序排列,从而对数据分布趋势有一个整体了解
数据解读:了解用户总体的行为、态度偏好
- 分组频数
除观察各选项的总体分布趋势外,也可将具有相似特征的选项进行合并分组分析,从而获得更宏观维度上的数据解读。以商品关注要素题目为例,浏览商品时关注的这11个要素可按降序排列,我们可以发现,用户最关注品牌,其次为参数信息,对店铺的关注最弱。但有时,我们不需要这么细致的分析维度,此时可以把这11个要素分组为商品层面和平台层面,来观察用户更关注哪个层面,将各选项百分比加总后可以得出结论,浏览商品时,较平台层面,用户对商品层面更为关注。同时,还可以对每个维度内的选项进行降序排列,从中可以得知,商品层面中,用户对品牌的关注最强,对新品的关注最弱
数据解读:了解不同维度上的用户行为、态度偏好
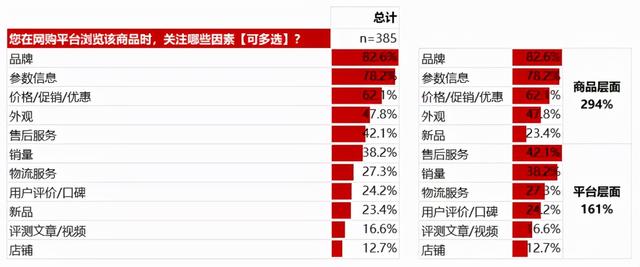
频数分析可参考此示意图
②描述性分析
常用于计算数值型的单变量统计量,主要包括以下三种类型的统计量。
- 描述集中趋势的统计量
常用的统计量有均值、中位数、众数、百分位数
- 描述离散程度的统计量
常用的统计量有样本方差、样本标准差、均值标准差、极差、离散系数
- 描述分布形态的统计量
常用的统计量有偏度和峰度
数据解读:了解用户行为、态度(数值型变量)的基本特征和整体分布形态,同时可为后续做更复杂的分析与建模做铺垫
③交叉分析
适用于对两个及两个以上变量之间的关系进行分析,从而得出更为立体的调研结论。
- 用户属性、用户行为、用户态度做交叉
如可以将用户属性进行拆分来观测不同用户属性的数据分布与总体的差异,关注显著高于和低于总体的数据。以商品关注要素题目为例,总体样本中71.6%的用户在浏览商品时关注品牌,其中81.4%男性关注品牌、61.8%的女性关注品牌,数据间有显著差异,则需要关注品牌在用户性别上的差异,并做出标记。当用户属性为定序变量时,可看行变量是否随着用户属性的升序或降序呈现出某种趋势,如随着年龄的递增,用户越关注商品品牌。需要注意的是,当行变量在用户属性上的数据差异较大时,应对照用户属性的样本量进行检验,若样本量少于30,数据差异的误差可能较大
数据解读:了解用户属性、行为、态度间的关系

交叉分析解读可参考此示意图
除上述提到的基本统计外,还可以应用聚类分析、相关分析、回归分析等对问卷进行深入分析。
2.数据格式规范化
数据格式规范化有助于快速的查找数据,也能让合作项目的小伙伴清晰的了解到问卷数据的产出,提升工作效率。使用何种格式来规范数据没有固定的模板,这里可以提供一些参考。
① 标记样本量
- 这一步骤是必须且重要的,问卷中的每道问题总填答人数、每个选项的填答人数都需要逐一进行标注
② 形成列联表
- 一般情况下,将问卷题目与选项置入到行变量中,将样本属性(如细分人群)的变量置入到列变量中,以方便查看
③ 根据题组拆分sheet
- 将反映不同研究内容的题组数据置于Excel不同的sheet中,以便后续能够快速查找

数据格式规范化可参考此示意图
中科易研以十余年行业积累为基础,结合互联网大数据技术,秉承“数据、信息、知识、智慧”的方法论,坚持“用数据说话、用数据决策、用数据管理、用数据创新”的理念,以自主研发获得国家发明专利的易研问卷平台和易研大数据云平台为依托,专注于为教育科研机构、政府企事业单位提供基于数据采集、数据清洗、数据检索、数据管理、数据分析和可视化、数据资源整合等全流程数据服务,并为用户提供大数据云平台搭建服务。
以上就是回收问卷后,从清洗到分析的一些经验,有需要的小伙伴们赶紧用起来吧!
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com