nodejs苹果系统使用教程 NodeJS扒Pixiv咱P站的个人收藏夹经历
着重说明,非墙内向,体验代码时务必保证科学上网环境。

Pixiv
场景咱大P站,绅士聚集地……你好我好大家好,身体越来越不好。
我这边需要把自己多年收藏的图集整理出来,然后永久保存在移动“硬”盘里,不多,就1000多张。但是,一张一张的点击,放大,再右键,实在是麻烦。所以便闲着花一小时写了个脚本,爬一下。
其实就是我会员到期了……
说明爬P站收藏夹算是我这段时间爬的最简单的数据了……讲真,不知道是P站不怕你爬还是技术团队忽视这一块,实在是简单的头大。以上不考虑登录过程。
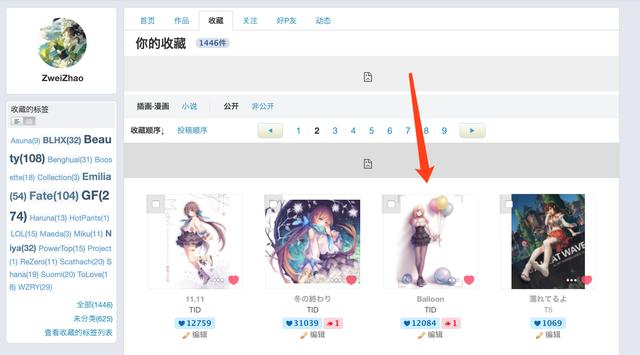
P站收藏夹保存本地常规方式显示收藏夹看目标作品(接一下TID大佬的Niya一用):
目标作品
进击进入目标作品:
目标作品页
点击图片放大看原图:
大图
然后右键:
右键
到这里,大家应该问题都不大。因为我们都是这么干的嘛……
爬取思路
- 查询相关接口
- 拿到cookie(不搞登录了)
- 关键referer
对,这三个就够了,没有淘宝那些坑爹的验证与算法。当然,你用Cookie去啃淘宝也不会太麻烦。
查询相关接口
这个很简单,因为P站是PHP的SSR,直接请求页面即可。
页面为:https://www.pixiv.net/bookmark.php?rest=show&p=1
p=这个参数直接点击进来是没有的,但是后面翻页会带上,所以我们默认就写上即可。
那么很简单,这里的p相关的数字一定得有个字段记录下,那么我们就弄个page吧:
let page = 1
然后就是请求这个页面了,再分析页面的各种标签了,我们当然借用superagent与cheerio了。superagent就不多说了,请求神器。cheerio可以理解就是服务端用的jQuery,老朋友了。
还有少不了的写文件与配置文件,写文件自然是fs,配置文件自己来,我喜欢如下:
配置文件
啥,Cookie和referer哪里来?看这:
获取点
cookie
referer
然后我们习惯性的记得,页面内容数量有上限的情况下,弄个参数记录当前索引。因为P站的收藏夹一个页面有20个图片,所以我们要记录下来,但是事实上,为了安全起见,这个最大数量最好是抓到数据后拿长度,这里先这么写,大家知道有这个东西即可。
let page = 1 , pageCurrentLength = 0 , pageMaxLength = 1
分别是:页码、当前页内的图片数量、当前页面最大数量。
那么加上引用包,我们的准备工作就就绪了,引入如下:
const config = require('./config/index') const request = require('superagent') const fs = require('fs') const cheerio = require('cheerio')
分别是:配置文件、superagent、fs、cheerio。
对了,记得npm install superagent cheerio啊。
开爬收藏页
找图片
通过调试器,我们很容易就找到图片对应的链接地址。这里随手搜索下相应class,发现刚好是20个,那么就可以简单的class来selector即可获取所有图片模块了。
之前都说了,cheerio就是服务端的jQuery,所以很容易就拿到,代码如下:
let thumbnails = $('._layout-thumbnail>img') , titles = $('a>h1.title')
恩,因为我们要命名图片,所以顺手把下面的title一起扣下来了,查找方式跟上面查图片木块一样一样的。
注意,这里与常规想法不同,P站简单的另一个原因。
我这里有留意看了下P站放大图片与这里缩略图的关系,然后发现,还真有关系。也因此,我节省了大批代码,不用去爬二级页面了。具体关系如下:
缩略图:https://i.pximg.net/c/150x150/img-master/img/2014/11/11/00/09/34/47020705_p0_master1200.jpg
放大图:https://i.pximg.net/img-original/img/2014/11/11/00/09/34/47020705_p0.png
相关关键词:
/c/150x150/img-master,_master1200,/img-original。
简单来说,/c/150x150/img-master换成/img-original,_master1200拿掉,就是放大图了。呼~这样就简单多了(这里有个坑,放大图后缀未必与这里一样,但是就png与jpg两种,后面有个函数专门干这个事情)。
正则搞起来:
originImgUrl = imgUrl.replace(/\/c\/150x150\/img-master(.*?)_master1200/, '/img-original$1')
imgUrl就是原来的缩略图,而originImgUrl就是我们的放大原图了,还是比较简单了嘛。
到这里(省略了常规性步骤),我们已经从收藏页获取了最多20个的图片模块,然后图片模块拿到了title以及通过正则匹配规则获取了原图路径,所以下面我们就是把图片弄下来,保存本地了。
是时候来fs了。
保存本地核心代码:
let stream = fs.createWriteStream(`./pixiv/imgs/${imgName.replace(/\//g, '')}`) , req = request.get(originImgUrl) .set('cookie', config.cookie) .set('referer', config.referer) req.pipe(stream) req.on('end', () => { if( pageCurrentLength >= pageMaxLength) restart( page) })
一个pipe的事情。
关于pipe,这里不多说,有兴趣的看下Node官方,如果只是看本文主题,复制这一坨代码即可。
过程嘛,就是请求的文件按照流Stream模式写入文件,避免大文件卡内存问题。
注意点是最后那个on end,每个文件写完后我们要确定收到,然后把文件数加一,直到文件写入达到页面所有数目,进行 page翻页。至于restart函数,明显就是启动函数了,这里调用启动函数一下。具体文末的代码会有总结,源码也有。
这里梳理一下先我们干了这么几件事。
- 收集整理cookie与referer来解决正常访问问题。
- 抓取php页面,然后分析功能模块。
- 找到缩略图与原图的规律,然后直接拿到原图的链接。
- 请求链接,看下是否有这个图片,如果没有就换一下后缀。
- 下载保存原图。
第一个是手动的,所以代码里面只是粘贴过来,我们不做业务处理。
第二与第三个合并一起,可以看做是功能模块,所以我们独立一个函数。
第四个,当做检测函数。
最后一个,独立一个函数。
于是我们有了三个函数,解决上述问题。
核心模块函数restart,就是启动函数,启动干嘛,自然是访问网页然后分析相关模块。
checkLinkStatus,检查图片类型状态,确定图片正确链接,我们只要head即可,所以使用了HEAD,而不是GET。
downloadFile,下载文件啦。
其中,需要传参如下:
checkLinkStatus({ imgTitle, imgName, originImgUrl }, index)
downloadFile({imgName, originImgUrl })
这里有优化点,不过我不打算弄了……等猴年马月维护吧。
checkLinkStatus使用的是HEAD,因为有没有这个文件,HEAD获取的报文头就已经知道了,没必要获取http请求的报文体了,也是为了加速。
至此,我们主逻辑全部完成,下面就是核心源码了。
核心源码头条排版坑爹,先图片再代码(辣眼睛):
top
middle
bottom
排版无敌的代码来了,下面有源码……
const config = require('./config/index') const request = require('superagent') const fs = require('fs') const cheerio = require('cheerio') // start page let page = 1 , pageCurrentLength = 0 , pageMaxLength = 1 function restart() { pageCurrentLength = 0 // debugger // if(page > 2) return request .get(`https://www.pixiv.net/bookmark.php?rest=show&p=${page}`) .set('cookie', config.cookie) .set('referer', config.referer) .end((err, res) => { if(err) { console.log(err) } const result = res.text $ = cheerio.load(result) let thumbnails = $('._layout-thumbnail>img') , titles = $('a>h1.title') // max length base on thumbnails length pageMaxLength = thumbnails.length Array.from(thumbnails).forEach(async (thumbnail, index) => { // debugger // if(index) return let imgUrl = thumbnail.attribs['data-src'] , imgFix = imgUrl.match(/\.\w $/)[0] , imgTitle = titles[index].attribs.title , imgName = imgTitle imgFix // normal rule with scale img and origin img. , originImgUrl = imgUrl.replace(/\/c\/150x150\/img-master(.*?)_master1200/, '/img-original$1') checkLinkStatus({ imgTitle, imgName, originImgUrl }, index) }) }) } function checkLinkStatus({ imgTitle, imgName, originImgUrl }, index) { request.head(originImgUrl) .set('cookie', config.cookie) .set('referer', config.referer) .end((err, res) => { // img's suffix maybe wrong. then should change to another one.(png and jpg) if(err) { let originImgUrlFix = originImgUrl.match(/\.\w $/)[0] , png = '.png' , jpg = '.jpg' if(originImgUrlFix === png) { imgName = imgTitle jpg originImgUrl = originImgUrl.replace(/\.\w $/, jpg) } else { imgName = imgTitle png originImgUrl = originImgUrl.replace(/\.\w $/, png) } } setTimeout(downloadFile.bind(null, { imgTitle, imgName, originImgUrl }), config.timeout * index); }) } function downloadFile({ imgTitle, imgName, originImgUrl }) { // ignore '/' error let stream = fs.createWriteStream(`./pixiv_col/imgs/${imgName.replace(/\//g, '')}`) , req = request.get(originImgUrl) .set('cookie', config.cookie) .set('referer', config.referer) req.pipe(stream) req.on('end', () => { if( pageCurrentLength >= pageMaxLength) restart( page) }) } restart()
上面都已经说明了,这里就不再带上过多注释了,没错,就是懒……
至于config,两种方案,一来看上面截图自己写一个,二来GitHub源码拉下来,自己改一下。
源码GitHub:https://github.com/ZweiZhao/Spider
如需要,建议使用dev分支,代码最新。
拉取后,cd Spider然后npm i,最后npm run pc即可运行。
不要忘了,运行前去弄一下Cookie!!!
不要忘了,运行前去弄一下Cookie!!!
不要忘了,运行前去弄一下Cookie!!!
效果
效果
兄弟们,我先去伤身体了。
,












免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






