graphpad如何做正态性检验(QSPR分子描述符预选中的互相关极限)

文丨异文录
编辑丨异文录

几十年来,QSAR/QSPR(定量结构-活性/性质关系)建模一直是计算、医学和环境化学的各种重叠子领域中的流行方法。分子描述符的产生和选择是这一过程的重要部分。在典型的QSAR工作流程中,分子描述符的起始池是基于过滤掉:1.在整个数据集内保持不变的描述符;2.与另一个描述符高度相关的描述符而合理化的。
虽然前者相当简单,但后者在决定什么被认为是强相关时涉及到一定程度的主观性。尽管如此,大多数QSAR模型研究没有报告这一步。在这项研究中,我们详细考察了各种可能的描述符互相关限制对所得QSAR模型的影响。基于当代QSAR文学的四个案例研究,使用基于等级差异总和(SRD)和方差分析(ANOVA)的组合方法进行统计比较。

从20世纪30年代汉密特的标志性作品中,20世纪60年代的汉斯和藤田,定量结构-活性和结构-性质关系(QSAR/QSPR)已经走了很长的路,演变成一个普遍存在的概念,在化学的许多子领域中出现。QSAR研究是每年数百种出版物的主题,并且该领域的状态被不时地彻底总结。
QSAR的重要性甚至得到了经济合作与发展组织(OECD)的认可,该组织公布了一套QSAR模式验证的原则(以及详细的指导文件)。此外,在过去的几十年中,该领域的研究人员一直关注于确定和促进QSAR建模和验证的最佳实践。
描述符(预)选择是QSAR工作流程不可或缺的一部分。它通常涉及删除具有缺失值的描述符、整个数据集的常数值或共线(相互关联)描述符。根据托德希尼和康松尼的术语,整个过程被称为变量约简:“变量约简包括选择能够保留整个数据集中包含的基本信息的变量子集,但消除冗余、高度相关的变量等。

变量缩减不同于变量选择,因为变量子集是从感兴趣的响应中独立选择的。”虽然去除恒定(或接近恒定)变量相对简单,但是在QSAR研究中,对于具体的相关性极限的选择没有明确的一致意见:来自近年来QSAR文献的随机样本显示选择1.000、0.98、0.95、0.90、0.80,甚至0.70。此外,大多数研究要么没有报道所选择的相互关联极限,或者干脆省略这一步。
应该注意的是,一些新一代的变量选择和QSAR建模方法(如PLS回归或主成分回归,PCR)固有地忽略了冗余变量(使变量减少对于小数据集是不必要的),然而这些方法不一定在相关和流行的QSAR建模软件中实现。此外,变量约简在大型数据集的情况下非常有用,可以节省计算时间,甚至(尤其是)用于高级回归方法,类似于变量选择工具,如遗传算法。
托德希尼在2004年提出了一个相对简单和流行的方法(QUIK规则)以及其他人。用于描述符之间的共线性检测(经合组织甚至在其指导文件中提出)。快速规则基于检查QSAR模型中描述符集合的总相关性(基于K多元相关指数)与模型描述符加上响应变量(K正常男性染色体组型)并拒绝任何两者差异不够大的模型。

虽然这是在检查共线性之后建模时的一种成功且流行的方法,如果发现共线性过大,它不提供关于从数据集中移除的描述符数量的指导(以改进模型)。我们这项工作的目标是为QSAR模型中描述符的选择提出选择互相关极限的指导方针。我们报告了一个详细的QSAR模型的统计比较,该模型基于文献中的四个案例研究,具有各种不同的终点,具有广泛的相互关联限制。
值得强调的是,我们的目的是公平地比较互相关极限,而不是建立最佳模型,这已经在原始出版物中完成了。我们希望利用这些高度多样化的数据集提供一般性的结论。在任何建模任务中,都有许多在统计意义上无法区分的次优解决方案。SRD作为一个多准则决策工具,能够区分次优的解决方案。根据我们最近的比较研究,等级差异总和(SRD)和方差分析(方差分析)的组合被应用于评价。

分析中使用了四个案例研究。第一数据集包含IC50新型N-苯甲酰基-L-联苯基丙氨酸衍生物作为α4整合素有效抑制剂的价值。第二个是一项ADME性质评估研究,其中包含超过300种化合物的logBB值(血脑分配系数)。第三个是对苯衍生物的毒理学研究,其中毒性值以急性毒性(pLC50)对于黑头鲦鱼(黑头鱼)。在第四个案例研究中,pIC50报道了一组N-取代马来酰亚胺的hMGL酶(人单酸甘油酯脂肪酶)的值。表中总结了所用数据集的具体细节。数据集的Smiles和SDF文件用于分子描述符生成。

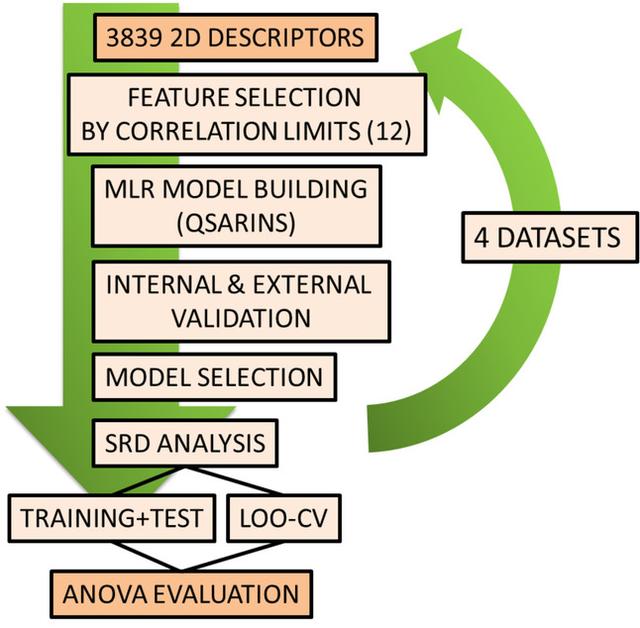
用DRAGON 7软件总共生成了3839个2D描述符。具有常量值的描述符和至少有一个缺失值的描述符被排除。接下来,描述符之间的绝对互相关极限被设置为:0.8000、0.8500、0.9000、0.9500、0.9700、0.9900、0.9950、0.9970、0.9990、0.9999、1.0000或无。对于每对相关的描述符,显示与其他描述符最高相关的描述符被自动排除。对应于不同限制的每个描述符集被保存用于模型构建阶段。所选数量的描述符可以在图中看到对于每个数据集。该图还强调了由不同互相关极限选择的描述符数量的数据集依赖性。

下一步,格拉马蒂卡及其同事的QSARINS 2.2.2软件被用于模型构建。该软件具有用于模型生成、验证(内部和外部)的丰富的统计方法工具箱,并且还可以输出模型的几个性能参数。为了只关注相互关联限制的影响,我们在建模期间对所有四个案例研究使用了相同的设置。
这些模型通过多元线性回归(MLR)和普通最小二乘法(OLS)计算,并使用遗传算法(GA)进行变量选择。这Q2对于留一交叉验证作为遗传算法的目标函数,这是一个标准的和广泛接受的回归模型的选择。群体的数量是100,并且执行100次迭代。突变概率设置为20 %,模型中包含的变量的最大数量为10。
基于原始文章,数据集被分成训练集和测试集,并保持固定。对于模型选择,我们建议根据普遍认可的实践——使用在变量选择过程中用作目标函数的相同性能参数。然而,在目前的研究中,通常会产生一个以上的模型,具有非常相似的Q2值。从这些模型中,最终的模型是根据它们的R2进一步评估的值。

排名差异总和(SRD)用于所选模型的比较。SRD是一种新颖、稳健的模型/方法比较统计方法,基于“理想”参考方法的使用。参考值可以是一组实验确定的值,但也可以使用基于数据融合可能性的假设一致方法,也是。按照惯例,输入矩阵在列中包含变量,在行中包含样本(这里是分子)。
该过程基于以下步骤:1.根据每个模型和参照按数量级排列样品,2.计算每个分子在每个模型和参照之间的绝对等级差异,3.合计每个模型的计算差异。得到的总和被称为SRD值,它们代表模型与参考的城市街区距离。关于SRD程序的详细说明可以作为我们早期工作的补充。使用归一化SRD可以比较不同研究的SRD值:

排名差异总和采用两种类型的验证。秩和随机数比较(CRRN)是一种随机化检验,它给出了具有随机化秩的SRD值的分布。基于这种验证,人们可以断定表征模型的SRD值是否与随机数的使用重叠。N-应用折叠交叉验证来检查两个模型的SRD值明显不同。这里,使用了七重交叉验证的连续和重复取样版本。
在目前的研究中,比较了QSAR/QSPR模型——通过选择不同相关限度的描述符进行计算。输入矩阵包含端点由数据集的每个分子的各种QSAR模型预测,在每种情况下以实验确定的终点作为参考。进行了两种形式的SRD分析:1.训练集和测试集的预测值,2.训练样本的留一交叉验证预测。
方差分析(ANOVA)用于四个数据集的SRD结果的统计比较。该方法基于不同样本组平均值的成对比较。交叉验证的SRD值被用于分析,相关极限被分组使用。应用STATISTICA 13 进行ANOVA评估。该程序的完整工作流程如图所示。
作为第一级比较,对模型的一些重要性能参数进行了比较,以检查这些参数是否能够区分具有不同相关限制的模型。校准的拟合优度(R2),交叉验证(Q2),以及外部验证,交叉验证的均方根误差和和谐系数基于我们之前的发现,选择参数进行评估。数字显示了四个数据集的这些值的分布。
可以清楚地看到R2、Q2和CCC履历值彼此非常接近,并且它们具有狭窄的分布。之间的相关系数R2和Q2数据集的值高于0.90。另一方面,R2分布更广。RMSE值更依赖于数据集,但它们处于相同的范围内。补充材料图S1显示了分解为独立数据集的相同信息,强调了这些性能参数的有限区分能力。
因此,经典的性能参数,虽然众所周知和接受,是不足以解开小的变化和影响。由于SRD最近在这方面超过了他们,我们决定用它来做进一步的分析。根据每个模型,SRD分析基于预测的终点,并以两种方式对每个数据集进行:1.使用训练和测试集分子的预测值,2.使用训练集分子的留一交叉验证值。SRD结果的一个例子可以在图中看到。


在图1所示的情况下所有的模型都比使用随机数好得多。竖线表示具有不同相关限制的型号。从SRD的结果中,我们使用了28行7重蒙特卡罗交叉验证的SRD值与方差分析进行比较。在补充材料表S1中可以看到这些值的示例。
根据四个数据集(α=0.05)的结果,在ANOVA程序中作为分类因素的互相关限值具有统计学意义。方差分析的结果可以在S2补充材料表中找到。因此,在描述符选择过程中使用不同的互相关限制对QSAR模型构建的最终结果具有显著影响。
基于四个数据集的平均值和方差的比较,如图所示。这一步是必要的,因为SRD值取决于模型的性能。因此,只有考虑到误差传播定律,我们才能比较误差线

如图所示,和四个数据集的单独结果,建议使用描述符的相互关联限制,但选择具体值并不简单。通常,过低的值通常会使结果恶化。另一方面,介于0.95和0.9999之间的范围总是能够产生一个或两个特定值,这些特定值对于所得到的模型来说表现出显著的改进。
笔者认为:分子描述符的选择在QSAR/QSPR模型的建立中起着重要的作用。这通常不会在研究文章中详细报道,但根据我们的发现,在分子描述符预选过程中选择的相互关联限制对结果有显著影响。对应用的四个数据集的SRD和方差分析表明,总体上下限恶化了结果模型。
0.95和0.9999之间的区域适用于变量缩减,在最终确定选择之前,值得检查多个限制,因为具体的选择本质上取决于数据集。此外,我们已经表明,即使是看似微不足道的变化也可以删除大量的描述符。因此,除了提出上述选择相互关联限值的详细方法外,我们强烈建议未来QSAR研究的作者公开他们应用的具体相互关联限值,以保证整个建模工作流程的可重复性。

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






