存储技术面临市场窗口期(存储技术热点与趋势总结)
作者 | 张凯,SmartX 联合创始人 & CTO。
2 年前我们发表了一遍文章 2018 存储技术热点与趋势总结,受到了不少朋友的关注。2 年过去了,存储行业也在不断的发生着变化。今天,我们就结合过去两年学术界和工业界的进展,帮大家做一次总结,供大家参考。
本文内容会涉及到 Persistent Memory、Consensus、Consistency、
Persistent Memory(PMem)
PMem 在 2018 年的时候还仅限于学术界的探讨,而如今已经来到了工业界。Intel 在 2019 年 4 月份发布了第一款 Intel Optane DC Persistent Memory(内部产品代号 Apache Pass),可以说是一个划时代的事件。如果你完全没有听说过 PMem,那么可以先通过我之前的文章了解一下。
我们先来看一下实物的样子

是的,DIMM 接口,看起来就像内存。所以很多人会把 Optane PMem 和 Optane SSD 弄混,因为都叫 Optane。实际上 Optane SSD 是 NVMe 接口,走 PCIe 总线。由于接口和总线不同,Optane PMem 和 Optane SSD 的使用方式也完全不同的。
目前单条(因为长得像内存,所以就用“条”来做量词了)容量一共有三种选择:128G、256G、512G,价格还是相当贵的。
这里我想强调的是:PMem 并不是更慢的内存,也不是更快的 SSD,PMem 就是 PMem,他有大量属于自己的特性。为了使用好 PMem,我们还需要对 PMem 了解更多。
首先,由于 PMem 是 DIMM 接口,可以直接通过 CPU 指令访问数据。读取 PMem 的时候,和读取一个普通的内存地址没有区别,CPU Cache 会做数据缓存,所有关于内存相关的知识,例如 Cache Line 优化,Memory Order 等等在这里都是适用的。而写入就更复杂了,除了要理解内存相关的特性以外,还需要理解一个重要的概念:Power-Fail Protected Domains。这是因为,尽管 PMem 设备本身是非易失的,但是由于有 CPU Cache 和 Memory Controller 的存在,以及 PMem 设备本身也有缓存,所以当设备掉电时,Data in-flight 还是会丢失。

针对掉电保护,Intel 提出了 Asynchronous DRAM Refresh(ADR)的概念,负责在掉电时把 Data in-flight 回写到 PMem 上,保证数据持久性。目前 ADR 只能保护 iMC 里的 Write Pending Queue(WPQ)和 PMem 的缓存中的数据,但无法保护 CPU Cache 中的数据。在 Intel 下一代的产品中,将推出 Enhanced ADR(eADR),可以进一步做到对 CPU Cache 中数据的保护。
由于 ADR 概念的存在,所以简单的 MOV 指令并不能保证数据持久化,因为指令结束时,数据很可能还停留在 CPU Cache 中。为了保证数据持久化,我们必须调用 CLFLUSH 指令,保证 CPU Cache Line 里的数据写回到 PMem 中。
然而 CLFLUSH 并不是为 PMem 设计的。CLFLUSH 指令一次只能 Flush 一个 Cache Line,且只能串行执行,所以执行效率非常低。为了解决 CLFLUSH 效率低的问题,Intel 推出了一个新的指令 CLFLUSHOPT,从字面意思上看就是 CLFLUSH 的优化版本。CLFLUSHOPT 和 CLFLUSH 相比,多个 CLFLUSHOPT 指令可以并发执行。可以大大提高 Cache Line Flush 的效率。当然,CLFLUSHOPT 后面还需要跟随一个 SFENCE 指令,以保证 Flush 执行完成。
和 CLFLUSHOPT 对应的,是 CLWB 指令,CLWB 和 CLFLUSHOPT 的区别是,CLWB 指令执行完成后,数据还保持在 CPU Cache 里,如果再次访问数据,就可以保证 Cache Hit,而 CLFLUSHOPT 则相反,指令执行完成后,CPU Cache 中将不再保存数据。
此外 Non-temporal stores(NTSTORE)指令(经专家更提醒,这是一个 SSE2 里面就添加的指令,并不是一个新指令)可以做到数据写入的时候 bypass CPU Cache,这样就不需要额外的 Flush 操作了。NTSTORE 后面也要跟随一个 SFENCE 指令,以保证数据真正可以到达持久化区域。
看起来很复杂对吧,这还只是个入门呢,在 PMem 上写程序的复杂度相当之高。Intel 最近出了一本书 “Programming Persistent Memory”,专门介绍如何在 PMem 上进行编程,一共有 400 多页,有兴趣的小伙伴可以读一读。
为了简化使用 PMem 的复杂度,Intel 成立了 PMDK 项目,提供了大量的封装好的接口和数据结构,这里我就不一一介绍了。
PMem 发布以后,不少的机构都对它的实际性能做了测试,因为毕竟之前大家都是用内存来模拟 PMem 的,得到的实验结果并不准确。其中 UCSD 发表的 “Basic Performance Measurements of the Intel Optane DC Persistent Memory Module” 是比较有代表性的。这篇文章帮我们总结了 23 个 Observation,其中比较重要的几点如下:
- The read latency of random Optane DC memory loads is 305 ns This latency is about 3× slower than local DRAM
- Optane DC memory latency is significantly better (2×) when accessed in a sequential pattern. This result indicates that Optane DC PMMs merge adjacent requests into a single 256 byte access
- Our six interleaved Optane DC PMMs’ maximum read bandwidth is 39.4 GB/sec, and their maximum write bandwidth is 13.9 GB/sec. This experiment utilizes our six interleaved Optane DC PMMs, so accesses are spread acrOSs the devices
- Optane DC reads scale with thread count; whereas writes do not. Optane DC memory bandwidth scales with thread count, achieving maximum throughput at 17 threads. However, four threads are enough to saturate Optane DC memory write bandwidth
- The application-level Optane DC bandwidth is affected by access size. To fully utilize the Optane DC device bandwidth, 256 byte or larger accesses are preferred
- Optane DC is more affected than DRAM by access patterns. Optane DC memory is vulnerable to workloads with mixed reads and writes
- Optane DC bandwidth is significantly higher (4×) when accessed in a sequential pattern. This result indicates that Optane DC PMMs contain access to merging logic to merge overlapping memory requests — merged, sequential, accesses do not pay the write amplification cost associated with the NVDIMM’s 256 byte access size
如果你正在开发针对 PMem 的程序,一定要仔细理解。
PMem 的好处当然很多,延迟低、峰值带宽高、按字节访问,这没什么好说的,毕竟是 DIMM 接口,价格也在那里摆着。
这里我想给大家提几个 PMem 的坑,这可能是很多测试报告里面不会提到的,而是我们亲身经历过的,供大家参考:
尽管峰值带宽高,但单线程吞吐率低,甚至远比不上通过 SPDK 访问 NVMe 设备。举例来说,Intel 曾发布过一个报告,利用 SPDK,在 Block Size 为 4KB 的情况下,单线程可以达到 10 Million 的 IOPS。而根据我们测试的结果,在 PMem 上,在 Block Size 为 4KB 时,单线程只能达到 1 Million 的 IOPS。这是由于目前 PMDK 统一采用同步的方式访问数据,所有内存拷贝都由 CPU 来完成,导致 CPU 成为了性能瓶颈。为了解决这个问题,我们采用了 DMA 的方式进行访问,极大的提高了单线程访问的效率。关于这块信息,我们将在未来用单独的文章进行讲解。
另一个坑就是,跨 NUMA Node 访问时,效率受到比较大的影响。在我们的测试中发现,跨 NUMA Node 的访问,单线程只提供不到 1GB/s 的带宽。所以一定要注意保证数据访问是 Local 的。
关于 PMem 的使用场景,其实有很多,例如:
- 作为容量更大,价格更便宜的主存,在这种情况下,PMem 实际上并不 Persitent。这里又有两种模式:
- OS 不感知,由硬件负责将 DRAM 作为 Cache,PMem 作为主存
- OS 感知,将 PMem 作为一个独立的 memory-only NUMA Node,目前已经被 Linux Kernel 支持,Patchset
- 作为真正的 PMem,提供可持久化存储能力
关于 PMem 的其他部分,我们后续还会有专门的文章介绍。
顺便剧透一下,我们即将在今年上半年发布的 SMTX ZBS 4.5 版本中,包含了针对 PMem 的大量优化工作,和上一个版本相比,整体延迟可以降低超过 80%~
Distributed Consensus and Consistency
Distributed Consensus 在过去十年已经被大家研究的比较透彻了,目前各种 Paxos,Raft 已经的实现已经被广泛应用在各种生产环境了,各种细节的优化也层出不穷。
如果你想系统性的学习一下 Distributed Consensus 的话,那么推荐你看一篇剑桥女博士 Heidi Howard 的毕业论文“Distributed consensus revised”。这篇论文可以说是把过去几十年大家在 Distributed Consensus 上的工作做了一个大而全总结。通过总结前人的工作,整理出了一个 Distributed Consensus 的模型,并且逐个调节模型中的约束条件,从而遍历了几乎所有可能的优化算法,可以说是庖丁解牛,非常适合作为 Distributed Consensus 的入门文章。
说到 Distributed Consensus,就离不开 Consistency。Distributed Consensus 是实现 Strong Consistency 的非常经典的做法,但是,并不是唯一的做法。
Distributed Consensus 只是手段,Strong Consistency 才是目的。
实现 Strong Consistency 的方法还有很多。在过去一段时间里面,我认为最经典的要数 Amazon 的 Aurora。
Amazon Aurora 目前共发表了两篇文章。第一篇是 2017 年在 SIGMOD 上发表的 “Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases”,另一篇是在 2018 年的 SIGMOD 上发表了一篇论文 “Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes”。第二篇论文主要讲述了他们如何在不使用 Distributed Consensus 的情况下,达到 Strong Consistency 的效果。
为了介绍 Aurora,我们先来简单看一下通常 Distributed Consensus 是如何做到 Strong Consistency 的。

我们假设当前计算端的状态是 S0,此时我们收到了一个请求,要把状态变更为 S1。为了完成这个变更,存储端会发起了一次 Distributed Consensus。如果成功,则计算端把状态变更为 S1;如果失败,则状态维持在 S0 不变。可以看到存储端向计算端返回的状态只有成功和失败两个状态,而实际上存储端内部会有更多的状态,例如 5 个节点里面 3 个成功了,1 个失败了,1 个超时了。而这些状态都被存储端屏蔽了,计算端不感知。这就导致计算端必须等待存储端完成 Distributed Consensus 以后,才能继续向前推进。在正常情况下不会有问题,但一旦存储端发生异常,计算端必须要等待存储端完成 Leader Election 或 Membership Change,导致整个计算端被阻塞住。
而 Aurora 则打破了这个屏障。Aurora 的计算端可以直接向存储端发送写请求,并不要求存储端节点之间达成任何的 Consensus。
典型的 Aurora 实例包含 6 个存储节点,分散在 3 个 AZ 中。每个存储节点都维护了 Log 的列表,以及 Segment Complete LSN(SCL),也就是已经持久化的 LSN。存储节点会将 SCL 汇报给计算节点。计算节点会在 6 个节点中,找出 4 个最大的 SCL,并将其中最小的值作为 Protection Group Complete LSN(PGCL)。而 PGCL 就是 Aurora 实例已经达成 Consistency Point。

看上去好像和 Multi-Paxos 也有些相似?是的,但 Aurora 并不要求存储节点之间达成任何的 Consensus,发生故障的时候,存储节点不需要参与 Leader Election,也不需要等待所有的日志复制完成。这意味着计算节点基本上永远不会被阻塞。
Aurora 的精妙之处在于把 Distributed Consensus 从存储节点中抽离出来了,存储节点只是单纯的负责存储工作就好了,而 Consensus 由计算节点来完成。那这样看上去好像又和 PacificA 很相似?是的,我认为在整体思路上,Aurora 和 PacificA 是非常相似的。我个人认为 Consensus 和存储节点的解耦会是未来的一个趋势。
除了 Aurora 以外,Remzi 团队在 FAST 2020 上的 Best Paper:“Strong and Efficient Consistency with Consistency-Aware Durability”,我认为也是非常有意思的一篇文章。
通常来说,我们在考虑 Consistency 的时候,都会结合 Durability 一起考虑。需要 Strong Consistency,就会用 Distributed Consensus,或者其他的 Replication 方式完成一次 Quorum Write,保证了 Strong Consistency 的同时,也保证了 Durability,代价就是性能差;如果只需要 Weak Consistency,那么就不需要立刻完成 Quorum Write,只需要写一个副本就可以了,然后再异步完成数据同步,这样性能会很好,但是由于没有 Quorum Write,也就丧失了 Durability 和 Consistency。所以大家一直以来的一个共识,就是 Strong Consistency 性能差,Weak Consistency 性能好。
那有没有一种方法既能保证 Strong Consistency,同时又保证 Performance 呢?Remzi 在这篇论文中提出了 “Consistency-Aware Durability”(CAD)的方法,把 Consistency 和 Durability 解耦,放弃了部分 Durability,来保证 Strong Consisteny 和 Performance。实现的方法可以用一句话总结,就是 Replicate on Read。
在 Strong Consistency 中,有一个很重要的要求就是 Monotonic Reads,当读到了一个新版本的数据后,再也不会读到老版本的数据。但换一个角度思考,如果没有读发生,是不存在什么 Monotonic Reads 的,也就不需要做任何为了为了保证 Consistency 的工作(是不是有点像薛定谔的猫?)。

我们在写时做 Replication,完全是为了保证 Durability,顺便完成了保证 Consistency。如果我们可以牺牲 Durability,那么在写入时,我们完全不需要做 Replication,写单复本就可以了。我们只需要在需要 Consistency 的时候(也就是读的时候)完成 Consistency 的操作就可以了(也就是 Replication)。所以我把这种方法叫做 Replicate On Read。
如果你的应用程序属于写多读少的,那么这种方法就可以避免了大量无用的 Replication 操作,仅在必要的时候执行 Replication,也就是读的时候。这样既保证了 Strong Consistency,又保证了 Performance。真是不得不佩服 Remzi,把 Consensus,Consistency,Durability 研究的太透彻了。
可能做系统的同学觉得牺牲 Durability 好像不可接受,但是在类似互联网应用的场景中,一些临时数据的 Durability 其实是不太重要的,而 Consistency 才是影响体验的核心因素。我们以打车举例,如果你看到司机距离你的位置一开始是 1 公里,然后忽然又变成了 3 公里,这很可能是后台的 NoSQL 数据库发生了一次故障切换,而从节点中保存的数据是一个老数据,导致破坏了 Monotonic Reads。而司机位置这种数据是完全没有必要保证 Durability 的,那么在这种情况下利用比较小的代价来保证 Monotonic Reads,将极大地改善用户的体验,你会看到司机和你的距离会越来越近,而不是忽远忽近。
另外再推荐给大家两篇论文,一篇是 Raft 作者 John Ousterhout 大神的新作 “Exploiting Commutativity For Practical Fast Replication”,还有一篇是用 Raft 实现 Erasure Code “CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost”。有兴趣的同学可以自己看一下,这里我就不做介绍了。
Distributed Shared Memory and Heterogeneous computing

在开始之前,我们首先来回顾一下计算机的发展历史。到今天为止,主流的计算机都是在冯诺依曼架构下发展的,一切的设计都围绕着 CPU、内存进行。当 CPU、内存的能力不足时,就通过总线(Bus),不断地对他们的能力进行扩展,例如磁盘、GPU 等等。随着 CPU 速度不断升级,总线的速度也在不断地升级,以匹配 CPU 的运算速度。同时,为了安全高效的完成 CPU 以及外设之间的通信,产生了例如 DMA、IOMMU 等技术。而总线受限于物理条件,通常只能进行非常短距离的通信,CPU 能直接访问的所有的设备都需要集成在主板上,也就是我们今天看到的主机。
在早期 CPU 的处理能力还非常弱的时候,单个 CPU 无法胜任大规模计算任务。这个时候出现了两种发展的流派,一种是 Shared Memory,也就是在单机内扩展 CPU 的数量,所有 CPU 都共享相同的内存地址空间;另一种是 Distributed Memory,也可以理解为多机,每台机器的 CPU 有独立的内存和独立的地址空间,程序之间通过 Message-Passing 的方式进行通信。Shared Memory 技术对于硬件的要求较高,需要在处理器之间实现 Cache Coherence,而软件层面的改动较为容易,早期的典型代表就是 Mainframe Computer,也就是俗称的大型机;而 Distributed Memory 则对硬件的要求较低,但是软件需要采用 Message-Passing 的方式进行重写,例如早年的 MPI 类的程序,主要应用在 HPC 领域。由于 Mainframe 的硬件成本太高,MPI 逐渐成为了主流。

在上世纪八九十年代的时候,曾经流行了一阵 Distributed Shared Memory(DSM)技术,也就是分布式共享内存。DSM 通过操作系统的内存管理系统把各个独立服务器上的内存地址连接到一起,组成连续的内存地址,使得应用程序可以更方便的做数据共享。但 DSM 技术一直没有发展起来,主要是受限于不断提升的 CPU 频率和当时的网络速度越来越不匹配,导致 DSM 的通信成本过高,无法被普及。

到了 2000 年以后,CPU 的发展逐渐遇到瓶颈,单核计算性能已经不再可能有大的突破,CPU 逐渐转向多核方向发展,个人电脑也用上了 Shared Memory 技术。而随着大数据对算力和存储能力的要求,Distributed Memory 技术也越来越广泛地被使用,例如 MapReduce 和 Spark 这种计算框架就是典型的代表。
到了最近几年,CPU 速度依然没有明显的突破,但网络速度却在发生翻天覆地的变化。包括 IB 和以太网都可以达到 200Gb 的带宽和 us 级别的延迟(据说目前已经在制定 800Gb 的技术标准),以及 RDMA 技术的普及,使得 DSM 技术又再次被大家提起。
OSDI ‘18 的 Best Paper “LegoOS: A Disseminated, Distributed OS for Hardware Resource Disaggregation” 就是一种 DSM 系统,只不过除了 CPU 和内存外,LegoOS 还包括了对存储的讨论。在论文中,作者把 CPU、Memory 和 Storage 分别抽象为 pComponent、mComponent 和 sComponent,这些设备之间通过 RDMA 网络连接在一起。LegoOS 向用户提供了 vNode 的概念,每个 vNode 类似一个虚拟机,可以包含一个或多个 pComponent,mComponent 和 sComponent。而每个 Component 同时也可以服务于多个 vNode。LegoOS 会负责对资源的隔离。由于具有统一的内存地址空间,且兼容 POSIX 接口,应用程序不需要被改写就可以运行在 LegoOS 上。
LegoOS 是一个非常不错的想法,但我认为在实现上会面临着非常巨大的挑战,一方面由于大部分的功能都需要依赖软件来实现,延迟可能会受到一定的影响,另一方面是 LegoOS 没有采用 Cache Coherence 的模型,而是用了 Message-Passing 的方式在各个 Component 之间进行通信。Message-Passing 可能是更优雅设计方案,但是如果真的想要在工业界中实现 LegoOS 这种思想,硬件厂商有需要根据 Message-Passing 来重新设计 Driver,这对于已有的硬件生态来说恐怕是很难接受的。
在工业界中,尽管目前还没有看到 DSM 的成功案例,但是目前已经开始看到一些相关的技术出现。这里我们会重点关注一下总线(Bus)技术。
最近几年,异构计算(heterogeneous computing)变得越来越常见,CPU 通过 PCIe 总线和 GPU、FPGA 等异构计算单元进行通讯。而由于 PCIe 总线诞生时间较早,不支持 Cache Coherence,所以为编写异构计算的应用程序带来了极大的复杂度。例如应用程序想要在 CPU 和 GPU 之间共享数据,或者 GPU 和 GPU 之间共享数据,必须自行处理可能产生的 Cache 一致性问题。
为了适应逐渐增加的异构计算场景,各个厂商开始筹划推出新的总线技术,这包括:
- 来自 Intel 的 Compute Express Link(CXL)
- 来自 IBM 的 Coherent Accelerator Interface(CAPI)
- 来自 Xilinx 的 Cache Coherence Interconnect for Accelerator(CCIX)
- 来自 AMD 的 Infinity Fabric
- 来自 NVIDIA 的 NVLink
毫无例外,不同厂家的技术都提供了对 Cache Coherence 的支持,这正是 PCIe 总线所缺乏的,也是工业界所需要的。目前这场关于下一代总线的竞争还在进行中,但大家认为能笑到最后的恐怕还是 Intel 所支持的 CXL。
这里我们只对 CXL 做一个简单的介绍。
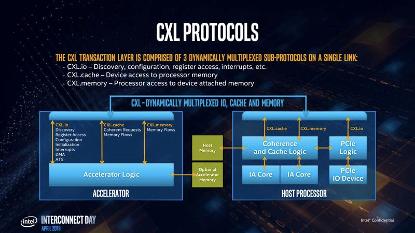
CXL 协议中定义了 3 种子协议:
- http://CXL.io:不提供 Cache Coherence 的 IO 访问,类似于目前的 PCIe 协议
- CXL.cache:用于设备访问主存
- CXL.memory:用于 CPU 访问设备内存
例如对于一个 GPU 设备,可以通过 CXL 来进行 GPU 到 CPU,GPU 到 GPU 的数据交换。而由于 CXL 支持 Cache Coherence,这个过程将变得非常简单,这无疑是一个重大的变化。而对于存储设备来说,CXL 使得 PMem 无论是作为持久化内存还是易失性内存,都可以不仅仅局限在内存总线,而是可以通过 CXL.memory 和 CPU 进行通信。这意味着 PMem 未来不仅仅可以提供类似目前 NVMe 设备的热插拔功能,还可以摆脱内存总线对散热和功耗的限制。甚至更进一步,未来可能会出现 CXL over Fabric 的技术,CPU 可以通过 CXL 协议访问远端内存。
CXL 1.0 将采用和 PCIe Gen5 向兼容的硬件标准,这样一来硬件厂商不需要为适配不同协议而生产两种不同接口的硬件设备,统一采用 PCIe Gen5 的标准就可以了。如果在设备协商阶段发现对端支持 CXL 协议,那么就可以采用 CXL 协议运行,否则可以采用 PCIe Gen5 运行。
CXL.cache 和 CXL.memory 组成了一个异构的 Shared Memory 系统,这对传统的 Shared Memory 系统是一个极大的扩展,让异构计算变得更加简单。而 CXL over Fabric 可能会组成一个由硬件支持的 Distributed Shared Memory 系统,这将使 Memory-level Composable Infrastructure 成为可能。在未来的数据中心,很可能会出现专门用于池化内存的服务器,CPU、内存像乐高一样搭建起来将真正成为现实。而这一切都有可能在未来的 5~10 年内发生。
其他方面
Open-Channel SSD
Open-Channel SSD 我在之前的文章中也做过介绍。和两年前相比,目前已经被很多云厂商用起来了。相比于传统 SSD,采用 Open-Channel SSD 的好处是可以定制 FTL,从而方便对特定的 Workload 进行优化。但 Open-Channel SSD 短期内恐怕只会被云厂商采用,毕竟大部分用户没有定制 FTL 的需求,通用的 FTL 就已经足够了。而随着 SPDK 中加入了对 FTL 的支持,也许未来会有厂商选择直接在用户态运行 Open-Channel SSD。
LSM-Tree 优化
过去两年这方面的进展也比较少,我看过唯一相关的论文,是在 FAST ’19 上的一篇论文:SLM-DB: Single-Level Key-Value Store with Persistent Memory,对 PMem 上运行 LSM-Tree 进行优化。目前随着 IO 设备的速度越来越快,大家都比较认可 LSM-Tree 已经从 IO Bound 转移到 CPU Bound,LSM-Tree 的劣势越来越明显,这让大家开始反思是否应该继续使用 LSM-Tree 了。
Machine Learning and Systems
尽管两年前开始有 Machine Learning For Systems 的相关工作,但是过去两年一直没有什么实质性的进展,反倒是 Systems for Machine Learning 有一些和 GPU 任务调度相关的工作。
VirtIO without Virt
VirtIO 是专门为虚拟化场景设计的协议框架。在 VirtIO 框架下,可以支持各种不同设备的虚拟化,包括 VirtIO-SCSI,VirtIO-BLK,VirtIO-NVMe,VirtIO-net,VirtIO-GPU,VirtIO-FS,VirtIO-VSock 等等。而 VirtIO 设备虚拟化的功能一直都是由软件来完成的,之前主要是在 Qemu 里面,现在还有 VHost。而目前逐渐有硬件厂商开始尝试原生支持 VirtIO 协议,把虚拟化的功能 Offload 到硬件上完成,这样进一步降低 Host 上因虚拟化而产生的额外开销。这也是 AWS Nitro 的核心技术之一,通过把 VirtIO Offload 给硬件,使得 Host 上的几乎所有 CPU、内存资源都可以用于虚拟机,极大的降低了运营成本。
Linux Kernel
目前 Linux Kernel 已经来到了 5.0 的时代,近期比较重要的一个工作就是 IO_URING。关于 IO_URING,我们之前在文章中也做过介绍。IO_URING 和一年前相比又有了巨大的进步,目前除了支持 VFS 以外,也已经支持 Socket,为了提高性能还专门写了新的 Work Queue。IO_URING 的终极目标是 one system call to rule them all,让一切系统调用变成异步!
总结
回顾过去两年,存储领域还是有非常巨大的进展,我们正处在一个最好的时代。工业界的进展相对更让人 Exciting 一些,非易失内存、CXL 协议、支持 VirtIO 的硬件等等,都可以说是开启了一个新的时代。而学术界尽管也有一些不错的 idea,但主要进展还是围绕在一些老的方向上,急需出现一些开创性的工作。
就我们公司而言,未来的一个工作重点就是如何充分利用 PMem 的特性,提高存储系统整体的性能。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com