神经网络计算器代码(一文详解MIT在读博士胡渊鸣提出的新型计算语言Taichi)

From:Taichi 编译:T.R
今晚八点
本周刷爆朋友圈的胡渊鸣大神来给talk啦!
欢迎各位携鲜花火箭游艇前来围观学习!
详情戳这里!
细心的我门也注意到很多同学除了膜拜,说得最多的就是“看!不!懂!”,那在直播开始前,就先由我门来带大家详细解读这大道至简的99行代码背后的编译技术吧!
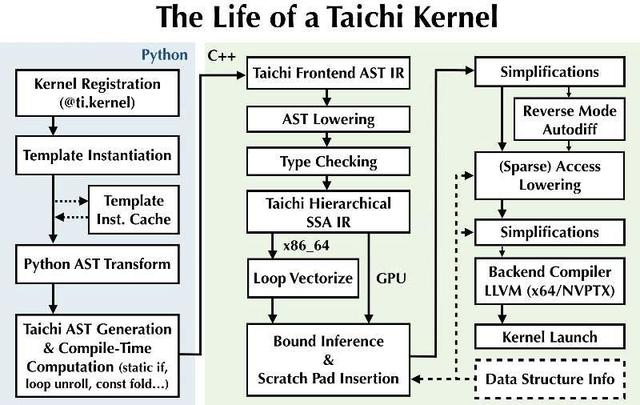
系统概览
其实Taichi编程语言主要有两个目的:
1) 从科研角度,探索能够加速视觉计算的新的语言抽象和编译技术
2) 从实用角度,降低高性能视觉计算程序的开发和部署成本
文章《99行代码的冰雪奇缘》介绍的更多的是第二个比较实用的层面,本文更侧重技术层面,讨论稀疏视觉计算相关的语言和编译技术。
三维视觉计算涉及的数据通常是稀疏的。为了利用数据的稀疏性,研究人员们设计了多种分层级的数据结构,包括多级稀疏体素栅格、粒子和三维哈希表等。但内在的复杂性和开销为开发和应用高性能的稀疏数据结构带来了一系列挑战:数据的非规则性、对于稀疏的三维数据结构实现高性能的计算代码是十分棘手的任务。首先对不同层级的遍历需要更多量级的时钟周期;同时对高效的并行计算需要有效的负载均衡;最后对非活跃的元素还需要进行有效的内存分配与稀疏性维持。
为此来自MIT和伯克利的研究人员提出了一种数据导向的编程语言——Taichi(太极),以对稀疏的数据结构实现高效的编程、接入和维护。它提供了高级的编程结构,用户可以独立于特定的数据结构编写计算代码;同时提供了不同稀疏特性的元素构件,可以被任意组合与复用到非常广泛的多层级的稀疏数据结构中去。通过数据结构与计算的解耦(decoupling),使用户可以在无需改变代码的情况下应用多种不同的数据结构进行便捷的实验,并且让用户可以像面对稠密数据一样进行计算编程。
此外编译器还可以更具数据结构的语义和索引分析自动的优化局部性、移除冗余操作、维持稀疏性和内存分配、为GPU和CPU生成高效并行化、矢量化的指令。实验表明,这种语言在数值模板、邻近查找、粒子散射等常用的计算核上具有优异的表现,在物质点法、有限元分析、多重网格泊松求解器、体积路径追踪和稀疏栅格三维卷积等等仿真、渲染和视觉任务上验证了这种新型语言的性能。总之,利用更少的代码(1/10)能达到更高的性能(4.55x)。
设计理念大多数稀疏的三维数据都具有一定的空间模式特性,为了实现高性能的计算,需要在不增加计算和存储开销的情况下为数据的稀疏性进行有效建模。
为了探索和分析数据中的空间稀疏性,新语言的开发需要满足以下四个高层级目标:
强大的表达能力。由于目标应用是具有复杂特征的计算核,所以这种语言需要有足够的表达能力来覆盖庞杂的数值计算模式;
高性能计算。高性能计算意味着实现优异的局部性与并行机制,但目前的方法大多与任务或硬件相关,要实现通用的硬件架构和多种数据结构还需要进行深入的研究;
强大生产力。先前的方法需要手动处理内存分配、并行化、边界条件等,需要利用底层接口进行编程。新语言可以让用户像操作稠密数据一样进行稀疏数据编程,编译器将自动生成优化后的代码。
可移植性。一个高性能的编程语言应该能够为不同的硬件环境自动生成优化代码。
基于这些考量,太极编程语言的设计方案将围绕以下六个方面展开:
1、解耦数据结构与计算。用户需要一种高级接口来进行计算编程,除了像操作稠密数据一样编程,同时还需要在不修改代码的情况下具备尝试不同稀疏数据结构的能力。研究人员通过笛卡尔索引(如二维坐标(1, 2), (7, 9)等)来抽象数据结构,实际的数据结构定义了索引与实际内存地址间的映射。
2、规则栅格最为构建单元。太极中的基本数据结构是规则栅格,它可以方便的压缩到一维array中,这与现代计算机架构中的线性内存地址十分相近。它不会直接对网格或者图等更不规则的结构建模,多分辨率的表达需要手工构建。
3、通过层级架构描述数据结构。为了对稀疏性建模并表述不同种类的数据结构,研究人员开发了一种数据结构迷你语言来编写数据结构层级。这种迷你语言由多个基本组件构成,包括稠密数组、哈希表等。
4、固定数据结构层级。为了简化编译器的优化流程和内存分配流程,研究人员假定了在编译时层级是固定的。这种语言不支持八叉树或包围体层级等的动态深度。
5、单程序多数据(SPMD)。SPMD方法可以有效的利用CPU的矢量指令能力与GPU的大规模计算能力,为了探索稀疏性,研究人员设计了仅仅在激活元素上进行并行迭代的计算核,这为程序员提供了简单的富有表达力的稀疏计算接口。
6、自动生成后端优化代码。太极的优化器可以自动生成高性能的后端代码,优化局部性、最小化冗余访问、自动并行化和内存分配,用户只需为编译器提供后端目标架构和相关调度提示即可。
高性能稀疏数据编程语言——太极为了深入了解这一新型编程语言,研究人员利用物理仿真和图像处理中常用的拉普拉斯算子来作为例子对语言进行了实例说明,下面首先给出拉普拉斯算子的有限差分离散化形式:
通过将多维索引映射到实际值来抽象数据结构。例如针对二维的矢量场,无论内部的数据结构如何总可以通过u[i,j]的形式来访问其中的值。编译器可以自动分析这些访问并生成最小化访问的代码。太极的前端内嵌在C 的框架中(注:为了易用性,新版本已换成内嵌在Python 3.6 中),通过在活跃数据结构(例如非零的像素或体素)上定义内核循环来实现计算。内核中包含了操作数据结果的关键代码。下面的例子展示了拉普拉斯算子的内核,利用for循环来对u进行操作。
在太极中,在活跃元素上进行for循环是稀疏计算的关键,编译器会自动维护这种稀疏性。当读取到非活跃值时,编译器将返回一个默认值(ambient value 0);当对一个非活跃值写入时,编译器将自动修改内部数据结构、分配内存、并将元素标注为活跃状态。
太极采用了单程序多数据的流程,但其中还包含了三个额外部件:并行化稀疏for循环,多维稀疏数组访问器、用于优化程序调度的编译器提示。其中for循环会自动的并行化和矢量化,同时支持像if-then-else和while等流控制语句。基本的构造方式和编译提示如下所示:
在构建好计算代码后,用户需要制定内部的数据结构层级,包括数据结构如何互相嵌套和稀疏性的表达这类的宏观结构以及数据如何组织等微观层级。太极中提供了结构节点来组合层级,以及修饰器来为结构节点提供特定的性质。其构造和语义如下图所示。
这些数据结构单元提供了访问开销和空间开销的平衡。例如哈希表的访问时间很长,但它却具有高效的内存空间,特别是对于极度稀疏的数据来说更是如此。这样的数据结构在只有少数激活元素时就适合做顶层;然而,像bitmask这样的稠密掩膜可以迅速激活和访问,但是在稀疏条件下占用空间太大了。所以基于这些基础元件,用户可以构建任意的数据结构,编译器将负责除了计算核如何在特定稀疏数据上计算的。
虽然这些数据结构的节点简洁,但它们却足够表达大范围的数据结构。下图展示了如何利用太极语言表示复杂的数据结构。新的数据结构只需要寥寥几行代码即可构建,快速地实现有助于我们为目标任务和硬件寻找到最优的解决方案。
针对特定领域的优化
层级数据结构为稀疏数据提供了丰富的表达,但其复杂性也带来了较高的访问开销,编译器可以针对下面三种典型的问题减少访问开销:
1、缓存外访问。计算机中如果从主内存中读取数据会比访问缓存慢几百倍,对于GPU来说更是如此,这就需要有效利用共享内存去缓存数据;
2、数据结构层级遍历。遍历层级数据结构的开销十分昂贵,例如哈希表的查询需要几十到几百个时钟周期,但是可以通过空间局域性来分摊这些开销;
3、实例激活。对于写访问,需要激活先前的未激活节点。这需要引入原子操作或者自旋锁,这不仅慢而且还是串行的操作。
针对这三个方面,研究人员进行了不同的处理以便优化结构提升销量。对于访问带宽的限制,利用边界推理实现Scratchpad优化,提供了构造函数Cache(v)实现Scratchpad优化。
对于冗余访问的削减,研究人员开发出了一种针对性的中间表示(Intermediate Representation, IR)来表述数据结构操作。这种中间表示可以为矢量化访问特别设计,同时包含访问与数据结构的具体信息,使得优化更容易进行。下面显示了编译期对于三次数据结构访问的优化例子。
此外,针对并行化和负载均衡也需要进行有效的优化。如果针对非规则数据直接划分计算单元就会造成下面这种情况,使得不同计算核间的负载不同。
太极的策略是生成一系列叶子块的任务列表,将数据压平到一维数组中去,不完整的树。更重要的是,针对每一个block而不是每一个元素生成任务,分摊了生成任务列表的开销。
在CPU上可以对树进行轻量级的串行遍历,任务清单随后将被队列化放入线程池中,并可以通过OpenMP进行并行化处理。在GPU中则维护多个任务清单,每一个针对从根到叶子节点的路径。清单通过层层递进的方式生成,从根节点开始,激活父节点的队列用于生成激活子节点。同时通过CPU与GPU间的异步执行进一步减小开销。
下表显示了太极在四个基准上的优化结果( Opt表示开启在Taichi IR上面的针对数据访问的优化,-Opt表示关闭这些Taichi的优化,直接交给后端编译器(gcc/nvcc/LLVM)生成代码。)
可以看到,Taichi通过针对稀疏数据结构设计的中间表示及其优化实现了通用编译器难以做到的优化。
由于篇幅有限,更多的设计与优化细节可以参考论文中的具体描述以及项目的官网:
http://taichi.graphics/wp-content/uploads/2019/09/taichi_lang.pdf
http://taichi.graphics/
注:本文主要描述Taichi截止在2019年5月的设计,最新技术细节请参考项目源代码。
最后研究人员在一些具体的实例上为我们展示了算法的性能,下面让我们一起来看看这些有趣又硬核的例子。
ref:
http://taichi.graphics/
https://github.com/yuanming-hu/taichi
https://arxiv.org/abs/1910.00935
⚠️
别忘了今晚胡渊鸣带来的线上直播哦!
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖
将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。将门创新服务
专注于使创新的技术落地于真正的应用场景,激活和实现全新的商业价值,服务于行业领先企业和技术创新型创业公司。将门技术社群
专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容,使创新成为持续的核心竞争力。
专注于投资通过技术创新激活商业场景,实现商业价值的初创企业,关注技术领域包括
机器智能、物联网、自然人机交互、企业计算。在近四年的时间里,将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: bp@thejiangmen.com,



















免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






