如何查询一个公网的ip(估算了一下公网IP地址的数量)
我们知道,每次拔号上网运营商会给你分配一个IP地址,通常每次都不一样。 我记录了355 次拔号得到的IP地址。其中:
- 237 个地址是各出现了(仅)1次的;
- 50 个地址是各出现了(仅)2次的;
- 6 个地址是各出现了(仅)3次的。
因为公网IP是稀缺资源,于是就想琢磨一下我这里运营商的IP地址池到底有多大。根据这些数据能否估算出地址池的大小N呢?
题图
1) 简单的数学模型上面的实验中总共得到了293 (237 50 6)个IP地址,反过来,未被选中的地址是 N - 293个。 于是可知:
- 经过355次拔号,某一特定地址不被选中的概率是 (N - 293)/N;
- 另一方面,仅拔号一次,某一特定的地址不被选中的概率是 (N - 1) / N。
于是我们可以得到下面的方程,并在Mathematica里求数值解(注意要限定实数域,否则会得到很多复数解)。

图:简单模型的方程及其解
显然 N > 293,于是有意义的解是 891.992。这是一个类似于平均值(数学期望)的数。 我们可以说,N在892附近。至于有多近,现在还不清楚,N可能是800,也可能是1000。
不过,这个模型里没有用到[237, 50, 6]这个1,2,3次的分布。这样做对吗?
2) 简单的模拟实验我准备用Python模拟一下,用到下面一些package。
import random import numpy as np import pandas as pd import matplotlib.pyplot as plt from multiprocessing import Pool
numpy里有一些现成的函数,用很短的代码就可以完成模拟;pandas用来画图,最后为了提升速度会用到多进程。代码在Jupyter Notebook里运行。
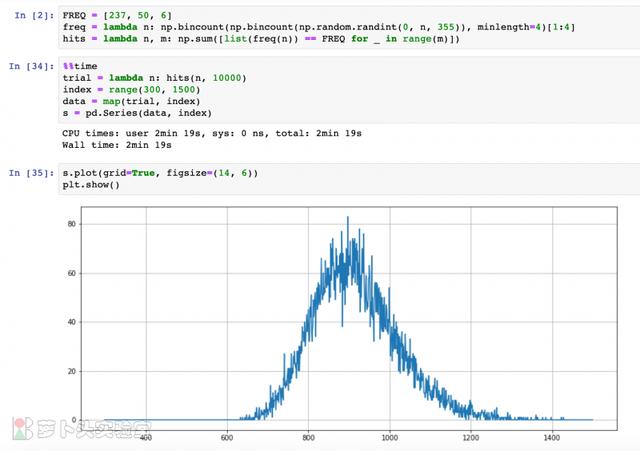
图:简单的模拟实验
一次实验的代码其实只有一行,流程是:
- 生成355个0~n之间的随机数;
- 统计每个数出现的频次;
- 统计每个频次出现的频次(即出现了0, 1, 2, 3... 次的数有多少个),其中出现0次的数目是不需要的。
把实验得到的频次和目标频次进行比较,相等就把计数加1. 对于每个n值,试验10000次,看看有多少命中的。
可以看到峰值确实是在900附近,大约是0.6%的命中率。也就是说,对于N在900附近时,从中取355次地址,大约有0.6%的可能会出现[237, 50, 6]这样的分布。
尽管这个值很低,但我们要看相对的高低,在900附近,是最有可能出现这个分布的。
3) 程序的改进前面的代码里可能会匹配到[237, 50, 6, 2](即还有2个地址各出现了4次)这样的分布,所以严谨一点,我们可以把匹配目标设为[237, 50, 6, 0, 0, 0]。再长也没有必要了,因为高频次的数量降低是很快的。
把程序改为多进程模式的。4核8线程的CPU把Pool大小设为8,实测CPU占用率能达到100%(而之前确实是1/8左右的占用率)。把每一个N值的模拟次数增加到2千万,这样可以得到较为平滑的曲线。
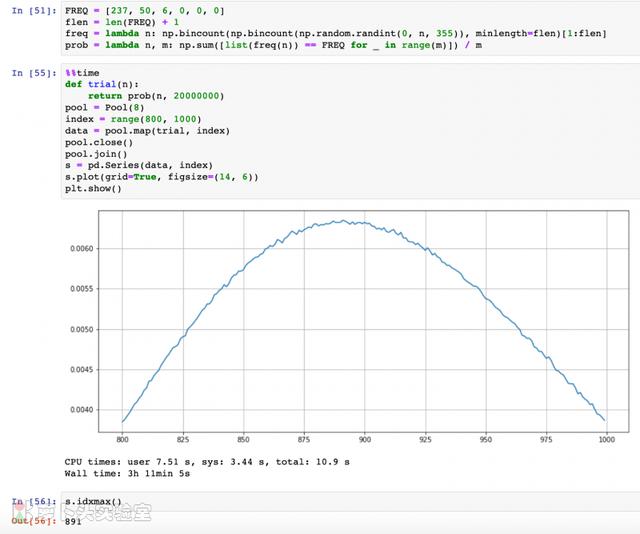
图:改进的模拟程序
这时可以得到最大概率对应的N值是891, 和简单的数学模型非常一致。
4) 概率公式和概率积分根据“不尽相异元素的全排列”可以推出,出现[237, 50, 6]这个结果的概率p[n],和n的关系,如下图。 用这个结果画出的曲线(图略)和模拟的完全一致,但速度快得多,而且是完全平滑的。
直接把这个概率“积分”(严格讲是累加),得到的结果是1.6. 为什么不是1呢?
因为这个概率p(n)表示的是对于某一个n,出现[237, 50, 6]这个结果的概率(它的反面是出现其它频次的概率);而我们需要的概率q(n)是指,[237, 50, 6]这个结果的对应的N,100%会落在比如说293~10000之间,那么它落在n的概率是多大呢?
让我们假定这两个概率是正相关的,这样把p(n)的积分归一化,就可以得到q(n)。于是我们用概率公式得到下面归一化的积分曲线。
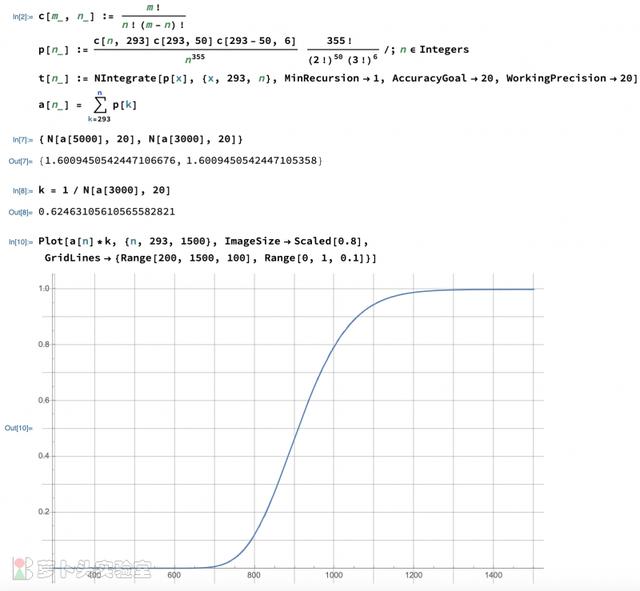
图:概率公式和概率积分
从图中可以估算出,N 98%的可能会落在700~1200之间。曲线的陡峭程度反映了N的集中程度(如果取样次数比355次更多,结果应该会更集中)。
5) 伯努利试验和二项分布其实这个问题是概率论中的一类典型问题,可以和伯努利试验及二项分布对应上。
在每次拔号中,选中某一地址为成功,否则为失败。m次拔号中,某个地址被选中k次的分布符合二项分布 b(k, m, p),其中p是被选中的概率(对于大小为n的地址池,p为1/n)。
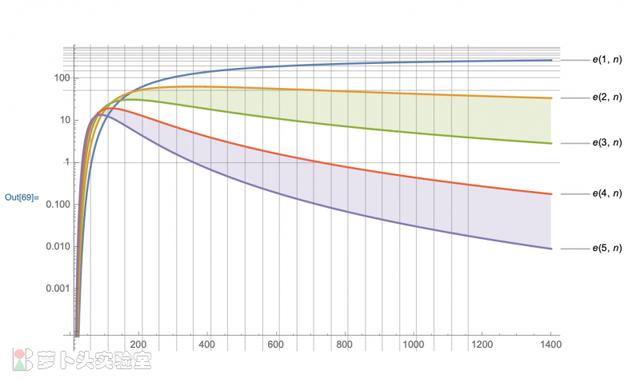
于是,m次拔号中,被选中k次的地址的总数的期望值为:b(k, m, p) * n。具体如下图所示:
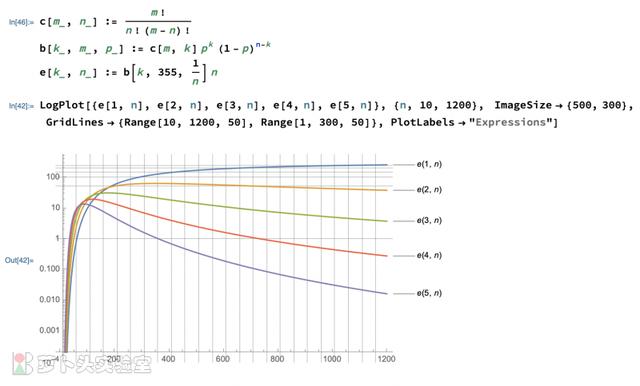
图:基于二项分布的计算
上图中给出了出现1~5次的地址总数随地址池大小n的分布。下图则给出了目标频次[237, 50, 6]附近( /-10%)所对应的n值。比如,当n取值700~1150时,最有可能出现237个1次地址。因为图中是期望值,所以并不意味着在这个范围之外不会出现237个1次地址,只是图中区域是概率最高的部分。这也可以理解,为什么根据3个条件得出的范围并不是严格一致。
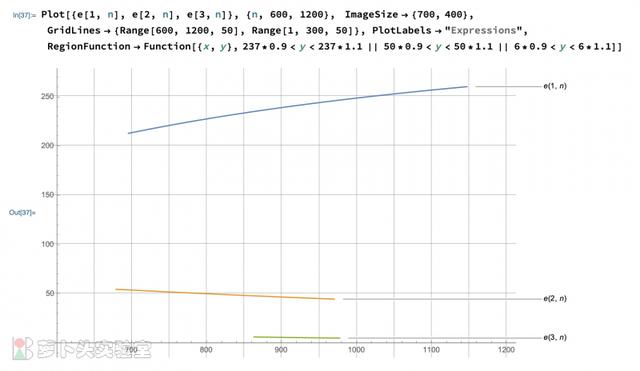
图:基于二项分布的结果
6) 结语本文对“我这里”的公网IP地址的数量这一蛋疼的问题,从数学上进行了推演,从程序上进行了模拟。数学简洁但高深,模拟笨拙但直观。殊途同归,两者得出了基本一致的结果。
本题可以作为码农编程的一个小练习,比如有人用了PHP语言,因为它有高精度的数值计算;有人用了R语言,因为它有现成的统计函数;继续的改进甚至可以考虑使用GPU提升模拟速度。
至于“我这里”是多大的范围,根据公里级的IP地理信息应该可以推测出来。这不是本文的重点。
本题在讨论过程中,得到了色影无忌众多网友的见解,@siliconworm, @TakeThat05, @rks, @pipedream,特此致谢。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






