三星有麒麟的处理器吗(三星8nm工艺最高售价1500美元)

来源:内容编译自anandtech,谢谢。
在寄予了很大的期望,并泄漏了不少信息后,NVIDIA终于在今天上午发布了其下一代视频卡GeForce RTX 30系列。这系列是基于NVIDIA Ampere架构的游戏和图形变体设计,并基于三星8nm工艺的优化版本打造。NVIDIA方面表示,这些新卡在游戏性能方面取得了重大改进。最新一代的GeForce还将具有一些新功能,以进一步将这些卡与NVIDIA基于Turing的RTX 20系列分别开来。
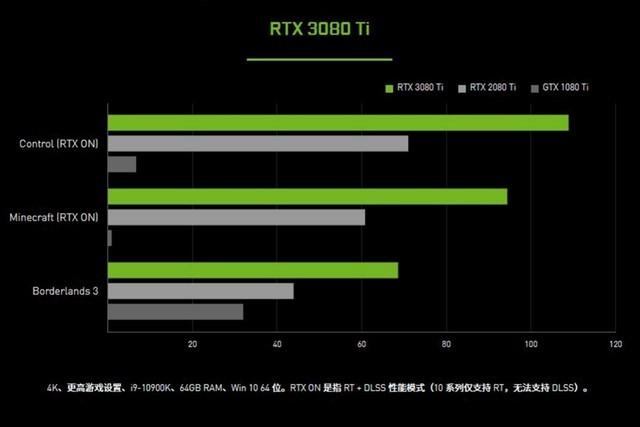
NVIDIA新发布的RTX 30系列的前三张卡分别是:RTX 3090,RTX 3080和RTX3070。这些卡都将在下个月半的时间内推出。其中RTX 3090和RTX 3080更是必须一提。这两款显卡将分别作为NVIDIA GeForce RTX 2080 Ti和RTX 2080 / 2080S的后继产品,他们创下了图形性能的新高。当然,RTX 3090的价格也创下了历史新高。
第一款上市的显卡是GeForce RTX3080。NVIDIA表示,新显卡是上一代产品RTX 2080性能的两倍,该显卡将于9月17 日以700美元的价格发售。一周后,功能更强大的GeFoce RTX 3090将在9月24 日上市,售价为1500美元。而TX 3070被定位为更多传统的甜蜜点卡,它将在下个月将以499美元的价格上市。
游戏领域的Ampere架构:GA102
与NVIDIA过往的做法一样,他们在今天上午的公开演讲不是深入探讨架构。但NVIDIA仍然继续其成功的发布经验。这意味着要进行大量的演示,推荐和宣传视频,并概要介绍最新一代GPU所采用的几种技术和工程设计决策。最终的结果是,我们对RTX 30系列有一个不错的了解,但是我们必须等待NVIDIA提供一些深入的技术介绍,才能了解得更透彻。
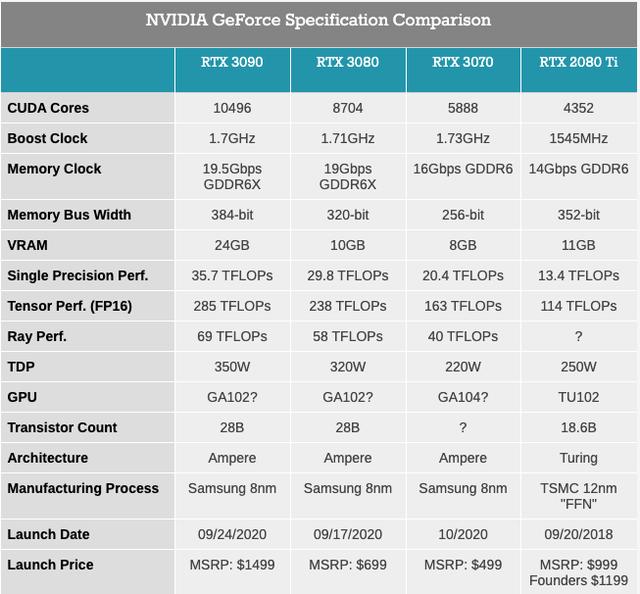
据了解,顶级显卡中使用的Ampere和GA102 GPU为NVIDIA的产品线带来了几项主要的硬件改进。其中最大的改进是晶体管尺寸的不断缩小,这要归功于三星8nm工艺的定制版本。我们对此工艺的信息有限,因为它没有被使用太多的地方,但从较高的层次上讲,这是三星公司最密集的传统非EUV工艺,源自其较早的10nm工艺。
总而言之,NVIDIA在采用更小的工方面已经有些迟了,但是由于该公司已经重新开发了首先交付大型GPU的亲和力,因此他们需要更高的晶圆产量(更少的缺陷)才能将芯片交付市场。

对于NVIDIA的产品而言,三星的8nm工艺是对他们先前工艺的完整升级,台积电的12nm“ FFN”本身就是台积电16nm工艺的优化版本。因此新工艺让NVIDIA的晶体管密度显着提高,
就GA102而言,在它里面集成了280亿个晶体管,这在大量的CUDA内核和其他可用硬件中得到了体现。图灵(Turing)和麦克斯韦(Maxwell)等中代架构在架构水平上获得了大部分收益,而安培(Ampere)(如之前的帕斯卡(Pascal))则受益于光刻工艺的适当改进。所有这一切的唯一障碍是Dennard Scaling 它已经死了并且不会回来。因此,尽管NVIDIA可以在芯片中封装比以往更多的晶体管,但功耗却在提高,这在显卡的TDP中得到了体现。
NVIDIA没有为我们提供GA102的特定die尺寸,但是根据一些照片,我们有足够的信心相信它会超过500平方毫米。它比754平方毫米的 TU102的尺寸要小得多,但它仍然是一个相当大的芯片,并且是三星生产的最大芯片之一。
继续,让我们谈谈Ampere架构本身。作为NVIDIA A100加速器的一部分,这个架构于今年春天推出,直到现在我们也仅是从面向计算的角度看到了Ampere。GA100缺少几个图形功能,因此NVIDIA可以最大化分配给计算的芯片空间,因此,像GA102这样的以图形为重点的Ampere GPU仍然是Ampere系列的成员,两者之间有很多区别。这就是说,到目前为止,NVIDIA一直能够对Ampere的游戏方面的能力保持神秘。
从计算的角度来看,Ampere看起来与Volta相当,而从图形的角度来看也是如此。GA102并未引入任何新奇的功能块,如RT核或张量核,但已对其功能和相对大小进行了调整。此处最显着的变化是,与Ampere GA100一样,应用在游戏的Ampere继承并更新了功能更强大的张量内核,NVIDIA将其称为第三代张量内核。单个Ampere SM可以提供比Turing SM两倍的张量吞吐量,尽管只有一半的张量核心数量。而且,NVIDIA似乎在GA102上保留了基本的设置。那就使得NVIDIA的FP16张量核心性能比上一代提高了一倍以上。
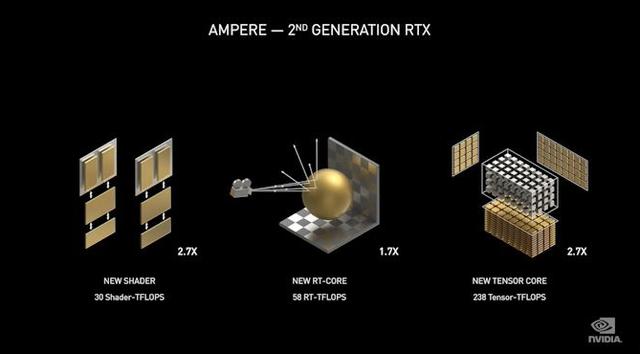
同时,NVIDIA已经确认GA102中使用的张量内核,其他Ampere图形GPU也支持稀疏性以实现更高的性能,那就意味着NVIDIA在张量内核功能方面没有退步。总体而言,对张量核心性能的关注,强调了NVIDIA对深度学习和AI性能的承诺,因为该公司认为深度学习不仅是其数据中心业务的驱动器,而且也是其游戏业务的驱动器。我们只需深入研究NVIDIA的深度学习超级采样(Deep Learning Super Sampling :DLSS)技术,即可了解原因。DLSS部分依赖于张量内核来提供尽可能多的性能,而NVIDIA仍在寻找更多方法来充分利用其张量内核。
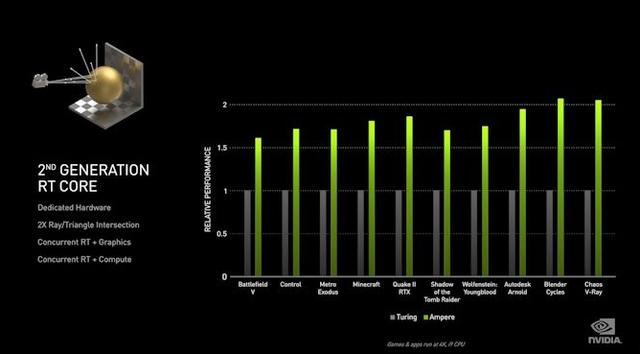
光线追踪(RT)核心也得到了增强,尽管我们不确定到什么程度。除了具有更多SM的GA102在整体上具有更多的功能外,据说各个RT内核的速度最高可快2倍,而NVIDIA可能专门引用了光线/三角形相交性能。NVIDIA的演示幻灯片中也有一些关于RT核心并发的简短说明,但是该公司在简短演示中并未对该主题进行任何真正的详细介绍,因此我们正在等待技术简介以获取更多详细信息。
总体而言,更快的RT内核对于游戏行业的光线追踪野心是一个好消息,因为光线追踪在RTX 20系列卡上的性能成本很高。话虽如此,但NVIDIA所做的任何事情都无法完全消除这种损失。光线追踪是一项艰巨的工作,需要一段时间,但更多且经过重新平衡的硬件可以帮助降低成本。
最后但同样重要的是,我们要关注一下着色器核心( shader cores)。这是对游戏性能最重要的领域,也是NVIDIA今天所说得最少的领域。我们知道,新的RTX 30系列卡包含了数量惊人的FP32 CUDA内核,这要归功于NVIDIA在其SM配置中将其标记为“ 2x FP32”。结果,即使是中端的RTX 3080也提供29.8 TFLOP的FP32着色器性能,是上一代RTX 2080 Ti的两倍以上。简而言之,这些GPU中有数量惊人的ALU,坦率地说,考虑到晶体管数量,ALU比我预期的要多得多。
当然,Shading 性能并不是一切,这就是为什么NVIDIA自己对这些显卡的性能要求不如仅Shading 性能方面的提高那么高。但是,考虑到计算机图形的令人尴尬的并行性,着色器在很多时候肯定是瓶颈。这就是为什么在此问题上投入更多的硬件(在这种情况下,更多的CUDA内核)是一种有效的策略的原因。
此时的主要问题是这些附加的CUDA内核是如何组织的,以及对于SM中的执行模型意味着什么。我们诚然在这里进入了更详细的技术细节,但是Ampere如何轻松地填充这些额外的内核将成为其能够更好地发挥所有这些teraFLOP性能的关键因素。这是由线程扭曲中额外的IPC提取驱动的吗?还是运行进一步的扭曲?
最后一点,当我们在等待有关新卡的更多技术信息时,值得注意的是,NVIDIA的规格表或其他材料均未提及卡中的任何其他图形功能。值得称道的是,图灵已经领先一步,提供的功能将在两年内成为新的DirectX 12 Ultimate /功能级别12_2,比其他任何供应商都要早。因此,随着Microsoft和其他领域的追赶,NVIDIA并没有立即追求的更高功能。不过,看到NVIDIA从其广为人知的帽子中抽出一两个新的图形功能来吸引众人,还是很不寻常。
I / O:PCI Express4.0,SLI和RTX IO
NVIDIA在 GeForce卡中引入了Ampere,也将Ampere改进的I / O功能带入了消费市场。尽管这里没有什么是开创性的,但这里的一切都有助于保持NVIDIA最新一代显卡的良好运转。
据了解,I / O前端的功能包括对PCI-Express 4.0的支持。这是在NVIDIA的A100加速器上引入的,因此,它的加入是在意料之中,但这仍然是自8年前GTX 680推出以来NVIDIA PCIe带宽的首次增加。借助完整的PCIe 4.0 x16插槽,RTX 30系列卡在每个方向上的I / O带宽达到32GB /s,是RTX 20系列卡访问速度的两倍。
至于PCIe 4.0对性能的影响,我们目前预计不会有太大的不同,因为很少有证据表明Turing卡受到PCIe 3.0速度的限制,即使PCIe 3.0 x8在大多数情况下也已足够使用。安培的更高性能无疑会增加对更多带宽的需求,但幅度不会太大。这可能就是为什么甚至NVIDIA都没有大力推广PCIe 4.0支持的原因(尽管在这里仅次于AMD可能是一个因素)。
同时,似乎SLI支持将持续存在至少至少一代。NVIDIA的RTX 3090卡包括一个用于SLI和其他多GPU用途的NVLInk连接器。因此,多GPU渲染即使几乎没有发生,也仍然有效。NVIDIA今天的演讲没有对该功能进行任何进一步的详细介绍,但是值得注意的是,Ampere架构引入了NVLink 3,如果NVIDIA将其用于RTX 3090,则意味着3090的NVLink带宽可能是上一代的RTX 2080 Ti的两倍,每个方向的速度为100GB/s。
总体而言,我怀疑RTX 3090上包含NVLInk连接器对于计算用户来说是一个新玩法,由于知道VRAM容量对先进的深度学习模型的重要习惯,许多用户将对拥有24GB VRAM的快速消费级卡感到垂涎三尺。。不过,NVIDIA绝不会放弃在图形方面进行追加销售的机会。
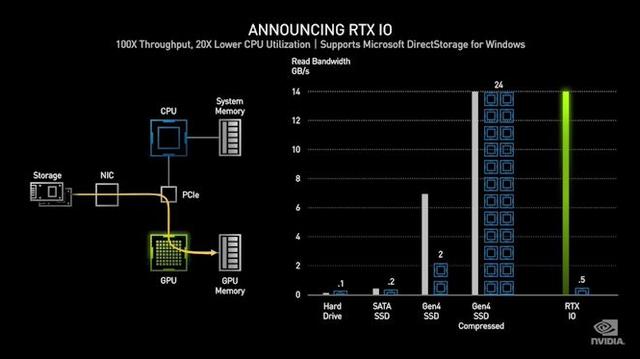
最终,随着RTX 30系列的发布,NVIDIA还宣布了他们称为RTX IO的新I / O功能套件。从高层次看,这似乎是NVIDIA对Microsoft即将推出的DirectStorage API 的实现,就像在首次启动的XboxSeries X控制台上一样,它允许从存储到GPU的直接连接,实现异步assets流的传输,通过绕开CPU来完成大部分工作,DirectStorage(以及扩展为RTX IO)可以通过让GPU更直接地获取所需的资源来改善I / O延迟和GPU的吞吐量。
除了Microsoft为该技术提供标准化API之外,这里最重要的创新是Ampere GPU能够直接解压缩assets。游戏assets经常被压缩以用于存储目的-至少Flight Simulator 2020占用甚至更多的 SSD空间,并且当前将这些assets解压缩为GPU可以使用的东西是CPU的工作。将其从CPU卸载不仅可以将其释放给其他任务,而且最终完全摆脱了中间人,这有助于改善assets流性能和游戏加载时间。
务实地说,我们已经知道该技术已经应用于Xbox Series X和PlayStation 5,因此很大程度上是Microsoft和NVIDIA与下一代游戏机保持同等水平。但是,它确实需要在GPU端进行一些真正的硬件改进,以处理所有这些I / O请求并能够有效地解压缩各种类型的assets。
Ampere功耗效率改进:1.9倍?可能不是
除了整体视频卡性能之外,NVIDIA的第二大技术支柱是整体功耗效率。功率效率是GPU设计的基石,因为图形工作负载有令人尴尬地并行化,并且GPU性能受到总功耗的限制。功率效率是所有GPU发布中经常关注的焦点。NVIDIA为确保RTX 30系列的发布而给予了一定的关注。
总体而言,NVIDIA声称Ampere的功耗效率提高了1.9倍。对于后Dennard时代的制造工艺节点的全面发展,这实际上是一个令人惊讶的说法。请注意,这绝非不可能,但这远超NVIDIA从Pascal升级到Turing所获得的提升。
但是,如果深入研究NVIDIA的说法,这个1.9倍的提升就显得越来越夸张。
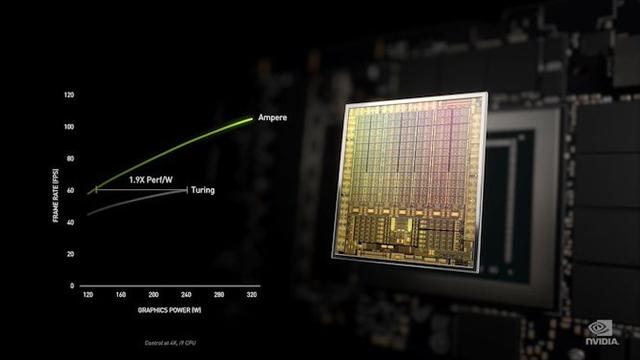
此处的直接奇怪之处是,通常功耗效率是以固定的功耗水平而不是固定的性能水平来衡量的。随着晶体管的功耗大约增加电压的三次方,像Ampere这样具有更多功能块的“更宽”部分可以以更低的频率进行时钟输出,从而达到与Turing相同的整体性能。本质上,这张图是将最坏的Turing与最好的Ampere进行比较,那么问题来了,如果我们将Ampere降频到与Turing一样慢,那会是什么样?而不是“在相同约束下安培比图灵快多少?”。
换句话说,在特定的功耗下,NVIDIA的图表并未向我们展示了直接的性能比较。
如果您实际上进行了固定的功耗比较,那么Ampere在NVIDIA的图表中看起来就不会那么好。在此示例中,Turing在240W时达到60fps,而Ampere的性能曲线大约为90fps。可以肯定的是,这仍然是一个很大的改进,但是每瓦性能仅提高了50%。最终,功耗效率的确切提高将取决于您在图表中的采样位置,但是很显然,按照更常规的指标定义,NVIDIA使用Ampere的功耗效率提高不会达到NVIDIA幻灯片所声称的90%。
所有这些都反映在新RTX 30系列卡的TDP中。RTX 3090消耗的功耗高达350瓦,甚至RTX 3080也消耗320W的功率。如果我们信奉NVIDIA的性能要求,RTX 3080提供的性能比RTX 2080高出100%,功耗增加了49%,那么每瓦性能的有效提高仅为34%。而RTX 3090的比较则更加苛刻,NVIDIA宣称性能提高了50%,功耗增加了25%,那就意味着其净功耗效率仅增加了20%。
最终,很明显,NVIDIA在Ampere一代产品中获得的大部分性能提升将来自更高的功耗限制。有了280亿的晶体管,这些卡将变得更快,但是它将需要比以往更多的电源来点亮它们。
支持PAM的GDDR6X
除了核心GPU架构本身之外,GA102还引入了对另一种新内存类型的支持:GDDR6X。这是由Micron和NVIDIA开发的GDDR6演进版技术,GDDR6X旨在通过在内存总线上使用多级信令来实现更高的内存总线速度(并因此获得更大的内存带宽)。通过采用这种策略,NVIDIA和美光科技可以继续推动具有成本效益的独立存储技术的发展,从而继续满足NVIDIA最新一代GPU的要求。这标志着NVIDIA在过去几代产品中的第三种存储技术,从GDDR5X到GDDR6再到GDDR6X。
美光公司上个月发布了有关该技术的一些早期技术文件时表示,通过采用脉冲幅度调制4(ulse Amplitude Modulation-4 :PAM4),GDDR6X能够每个时钟发送四个不同的符号,实质上是每个时钟移动两位,而不是通常每个时钟移动一位。为了简洁起见,我不会完全重述该讨论,但我将重点介绍。
在非常高的水平上,PAM4与NRZ(二进制编码)的区别是使单个单元(或在这种情况下为传输)将保持的电气状态数增加一倍。PAM4使用4种信号电平,而不是传统的0/1高/低信令,因此一个信号可以编码为四种可能的两位模式:00/01/10/11。这样一来,PAM4可以承载的数据量是NRZ的两倍,而不必将传输带宽加倍,这将带来更大的挑战。

反过来,PAM4需要更复杂的存储控制器和存储设备来处理多种信号状态,但同时也会降低存储总线频率,从而简化了其他方面。对于NVIDIA来说,最重要的一点可能是它的电源效率更高,每位带宽消耗降低约15%。可以肯定的是,总的DRAM功耗仍在上升,因为这远远超出了带宽获得的补偿,但是DRAM上节省的每一焦耳都被应用在GPU的其他方面。
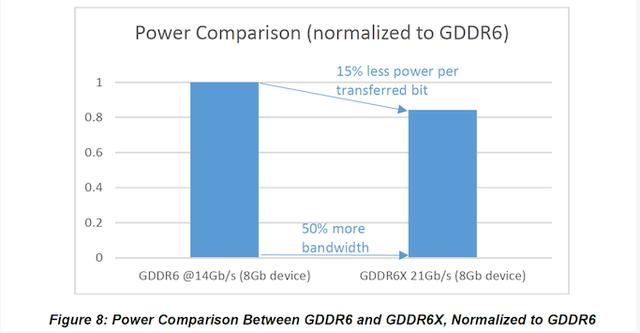
根据美光的文件,该公司设计的第一代GDDR6X达到21Gbps。但是NVIDIA在这里显得略为保守,RTX 3090的速度为19.5Gbps,RTX 3080的速度为19Gbps。即使在这些速度下,假设内存总线大小相同的情况下,内存带宽仍比上一代卡提高了36%-39%。总体而言,这种进展仍然是规范的例外。从历史上讲,我们通常看不到连续几代产品都能获得如此大的内存带宽。但是,随着提供更多的SM,我只能想象NVIDIA的产品团队很高兴拥有它。
但是,GDDR6X确实存在一个明显的缺点:容量。
尽管美光计划在将来开发16Gbit芯片,但从今天开始,他们将来只会生产8Gbit芯片。此密度与NVIDIA RTX 20系列卡及其GTX 1000系列卡上的存储芯片相同。因此,至少对于这些卡而言,没有“免费”的存储容量升级。RTX 3080仅获得10GB的VRAM,而RTX 2080仅为8GB,这是因为使用了较大的320位内存总线(即10个芯片而不是8个芯片)。同时,RTX 3090获得24GB的VRAM,但是只能通过在384位内存总线上以clamshell 模式使用12对芯片,从而使存储芯片的数量做到RTX 2080 Ti的两倍多。
HDMI 2.1和AV1引入,VirtualLink出局
最后,在显示I / O面板上,Ampere和新的GeForce RTX 30系列卡在此处进行了几个显着更改。最重要的是,他们终于有了对HDMI 2.1的支持。HDMI 2.1已经在电视中(并将在今年的主机中交付)面世,它为桌面带来了一些功能,其中最引人注目的是支持更大的电缆带宽。
HDMI 2.1电缆可以传输高达48Gbps的数据,是HDMI 2.0的2.6倍以上,从而可以提供更高的显示分辨率和刷新率,例如以165Hz以上的频率运行的8K电视或4K显示器。带宽的飞跃甚至使HDMI领先于DisplayPort。DisplayPort 1.4仅提供大约66%的带宽。虽然DisplayPort 2.0 最终会击败它,但目前看来,Ampere对于该技术而言还为时过早。
综上所述,我仍在等待NVIDIA确认其新GeForce卡是否支持全48Gbps信号速率。因为某些HDMI 2.1电视已经发货,支持更低的数据速率,因此,NVIDIA在这里做同样的事情并非不可想象。
从游戏的角度来看,HDMI 2.1的其他功能是通过HDMI支持可变刷新率。但是,此功能不是HDMI 2.1独有的,确实已经被移植到NVIDIA的RTX 20卡,因此,随着电缆带宽的增加,对它的支持将在这里变得更加有用,但从技术上讲,它并不是NVIDIA卡的新功能。。
同时,RTX 20系列卡上引入的VirtualLink端口即将淘汰。业界试图建立一个端口,以将视频,数据和电源整合起来,用于VR头戴式耳机中,但这个尝试已经失败了,三大头戴式VR制造商(Oculus,HTC,Valve)都没有使用该端口。因此,您不会在RTX 30系列卡上找到该端口。

最后,当我们讨论视频时,NVIDIA还确认了新的Ampere GPU包括其NVDEC视频解码模块的更新版本。该芯片制造商将这一功能提高到了NVIDIA所谓的Gen 5,增加了对新AV1视频编解码器的解码支持。
人们普遍期望,即将出现的免版税编解码器将成为H.264 / AVC的事实上的继任者,因为HEVC进入市场已经有很多年了(并且最近所有的GPU都已经支持了)。编解码器附近的madcap专利使用费情况不利于其采用。相比之下,AV1在分发中的使用应提供与HEVC相似或略好于HEVC的质量,但无需支付版税,这使其对内容供应商的吸引力更大。迄今为止,AV1的一个缺点是CPU负担很重,即使在高端台式机中,硬件解码支持也很重要,以便避免占用CPU资源并确保流畅,无干扰的播放。
NVIDIA在这里没有详细介绍其AV1支持的内容,但是另一篇博客文章提到了10位色彩支持和8K解码,因此听起来NVIDIA已经覆盖了基础。
同时,没有提及对该公司NVENC区块的进一步改进。最近针对Turing发布进行了修改,从而扩大了NVIDIA HEVC编码功能的范围以及整体HEVC和H.264图像质量。否则,对于硬件AV1编码,我们还为时过早,因为该编解码器的某些独特属性正在使硬件编码更难破解。
免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2420期内容,欢迎关注。
晶圆|蓝牙|5G|光刻|华为|台积电|DRAM|半导体材料
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com