亚马逊无货源模式怎么去精细化(亚马逊云科技实时数仓的场景剖析与架构搭建实战)
导读:无论是架构师还是工程师,在开始埋头实战之前,都需要了解的未来数据平台的一些趋势。本文主要介绍Amazon实时数仓架构以及Amazon提供的实时数仓服务,如何基于Amazon服务搭建的实时数仓架构;传统数仓-lambda-Kappa-数据湖的架构演进过程及典型数仓案例;Serverless、Redshift实时数据架构及优势。
今天的介绍会围绕下面四点展开:
- 数仓架构演进
- Amazon Serverless实时数据湖架构
- Amazon Redshift更强劲的云原生实时数据仓架构
- Redshift实时数仓 ML
01
数仓架构演进
从传统离线数仓架构到lambda架构、Kappa架构,以及数据湖架构,每一个数仓架构的演进都是在解决不同的问题,解决上一代数仓遗留下来的问题。

1. 数仓架构演进
- 传统数据仓库架构
使用关系型数据库(比如Oracle、PG)直接做数据仓库,在海量数据集下性能比较弱,扩展性比较差,存储架构上存算耦合。为了解决传统数仓架构的性能弱、扩展性差的问题,演进了基于hadoop生态的离线数仓,Hadoop生态通过横向扩展能力提高了性能、计算能力、扩展性,但离线数仓仍然存在T 1延迟。如果数仓的某一个链路出现了故障,那么故障的恢复代价也是比较高的。
- Lambda架构
为了解决延迟高的问题演进了Lambda架构,Lambda 架构的设计是为了在处理大规模数据时发挥流处理和批处理的优势。通过批处理提供全面、准确的数据,通过流处理提供低延迟的数据。Lambda架构要维护两套架构,开发运维成本相对较高,流和批数据一致性也很难保证。
- Kappa架构
远比Lambda架构简单,将批处理改成流处理,通过kafka建仓,ODS层,DWD层,DWS层都在kafka上搭建。主要缺点是:第一,数据的回溯成本较高;第二,很难与OLAP引擎的结合。
- 湖仓架构
hudi、iceberg 本身提供了ACID属性,提供upset(更新数据)能力,提供了time travel(时间线)能力、 schema evolution(对应半结构化数据结构定义的修改)能力,这些特性可以解决数据回溯成本高,OLAP引擎结合困难的问题,但是基于hudi数仓架构存在分钟级别的延迟,或者是小时级别的延迟。
2. 实时湖仓架构

- 数据接入
有三类数据,包括移动端日志数据,业务端数据,关系型数据库的数据。关系型数据库中的数据(RDS)通过CDC工具将变更日志发送至kafka。
- 数据存储
kafka将数据发送至hudi或iceberg,底层存储选择S3做存算分离,数仓各层都可以做OLAP查询。
- 数据聚合层
数据处理之后提供给应用层进行API接口服务、报表展示等。
实时湖仓架构在数仓的每一层都可以做OLAP引擎,实现存算分离,存储与计算去做耦合,扩展各自的资源。
3. 实时计算

湖仓架构数据可以做到分钟级别的延迟,对于需要低延迟的场景,需要做到秒级甚至是毫秒级延迟的场景,如果数据落地无法实现秒级延迟,需要将源数据同步到kafka,通过flink本身的计算引擎进行计算,做完计算之后将数据存储至数据库,通过API直接去调用访问。
我们去做实时计算场景,需要考虑当前业务是不是真的需要做实时计算;通过实时计算带来的业务价值是什么,不要把实时计算和实时数仓柔和在一起。
4. Serverless的引入

上述实时计算的架构hudi flink在整个计算流程中,需要把整个架构搭建起来,运维的复杂度很高,系统的稳定性也都需要很大的精力去保障,如何做到更轻的运维,更好的弹性伸缩能力,更好的系统稳定性,更好的成本节省,更简易的配置,让我们的精力专注到业务系统上来,这就引入了Serverless服务,能够把架构能够变得更简单。
--
02
Amazon Serverless实时数据湖架构

1. Amazon Analytics Serverless
Kinesis Data Streams,是一个消息系统,是一个实时数据流服务:
① KDS 是HTTP协议。
② kafka有partition,KDS有Shard,每个shard提供了固定的吞吐大小,1MB/write,2MB/read提供了横向扩展能力,按照shard扩展读写能力。
③ On-demand模式,在Serverless的架构上,不在需要关注机器,当使用On-demand模式(按需的模式)时候,需要关注的就是进来的流量是多少,写进去的流量是多少,出去的流量是多少。
④ 秒级创建,秒级删除,比使用kafka更容易,不需要搭建集群和维护集群。扩缩容根据sharp弹性扩缩。
Kinesis Data Analytics是一个做数据分析的服务:
① 是托管的一个flink runtime。
② 预置计算资源、并行计算、自动扩展和应用程序备份(实施为检查点和快照)。
③ Studio可视化的开发Flink Job,一键部署上线。
④ 自动checkpoint管理。
Athena是一种交互式查询服务:
① 底层基于PrestoDB,OALP引擎。
② 扫描数据量收费,无需关注计算资源。
③ 无需预置费用,不使用不收费。
④ 支持hudi、Iceberg。
⑤ 行列级别的权限控制。
2. 无服务器实时湖仓架构

无服务器的实时数据库架构,数据链路与实时数据架构是相同的,选择Serverless的服务来承接这个链路,无服务架构是看不到集群,因此是零运维,资源可弹性扩缩,数据在S3上供持久的数据质保证,提供可视化的开发部署,监控报警灵活,配置直接继承。在无服务器的实时数据库架构中,我们更多的关注业务系统业务应用的开发,无需运维工作。

在无服务实时湖仓架构的基础上,我们还会思考架构设计能不能更简单,数仓能不能做到读写分离,数据跨region、跨账号共享等,为解决客户面临这些痛点演进出Amazon Redshift。
--
03
Amazon Redshift更强劲的云原生实时数据仓架构

1. Redshift分布式和群集服务
- Redshift有两种类型的节点,Leader和Compute。Leader节点管理跨Compute节点的数据分发和查询执行。数据仅存储在Compute节点上。
- Auto-scaling clusters 在高并发的场景下秒级弹出来与当前配置大小相同集群。
- CAAS是一个Serverless compiler,所有SQL进入Redshift都会做编译,在集群之外是不可见的。
- Spectrum沿用了 Amazon Redshift 的查询优化机制,可以生成高效的查询规划,即便面对诸如多表 join 或者带统计函数(window function)的复杂查询也能胜任。可以对多种格式的数据源直接查询–Parquet, RCFile, CSV, TSV, Sequence, Avro, RegexSerDe 等。
- AQUA,Amazon Redshift的分布式硬件加速缓,针对数据分析的自研芯片。AQUA缓存可横向扩展,并可跨众多节点并行处理数据。每个节点都包含一个由亚马逊云科技设计的分析处理器组成的硬件模块,可以极大地加速数据压缩、加密和数据处理任务(如扫描、聚合和过滤)。
- Data sharing clusters可以跨集群、跨region的数据共享。还提供了联邦查询功能,可以直接查关系型数据库中的数据。
2. Redshift 实时数据摄取能力

首先Redshift支持高达30万/秒的实时数据摄入能力;Redshift通过执行SQL语句就能数据加载至KDS中,不需要中间再架构一个计算引擎,对于整个架构设计,只需要一个SQL语句就能实现;update数据Delete Insert实现。第二,支持宽表、多表关联、复杂聚合等各种SQL查询。第三,通过super数据类型解析半结构化数据非常高效。
3. Redshift 实时数仓

Redshift架构:通过KDS将数据加载到Redshift,在Redshift中建ODS层、DWD层、DWS层,BI工具通过JDBC使用数据。这个架构上能够做到简单、快速、稳定。Redshift引擎在数仓上能够自动优化排序键(在过滤条件中自动选择键值排序更高效),自动选择每列的压缩算法,自动选择分布键值(数据在各个节点可以自动均匀分配),自动刷新表的统计信息等。Redshift都尽量做到自动化优化处理,使用者只需创建查询语句查询即可。
4.Redshift 实时数仓与实时计算
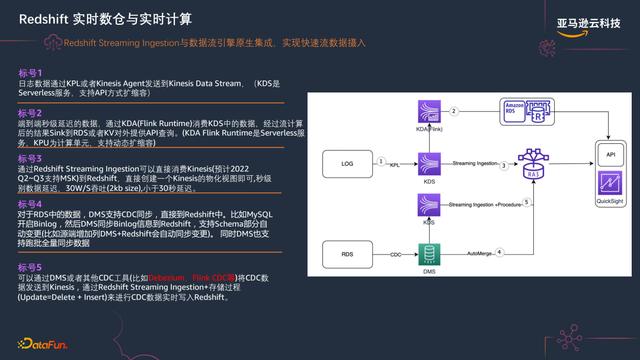
Redshift Streaming Ingestion与数据流引擎原生集成,实现快速流数据摄入。
- 日志数据通过KPL或者Kinesis Agent发送到Kinesis Data Stream(KDS是Serverless服务,支持API方式扩缩容)。
- 端到端秒级延迟的数据,通过KDA(Flink Runtime)消费KDS中的数据,经过流计算后的结果Sink到RDS或者KV对外提供API查询(KDA Flink Runtime是Serverless服务,KPU为计算单元,支持动态扩缩容)。
- 通过Redshift Streaming Ingestion可以直接消费Kinesis到Redshift,直接创建一个Kinesis视图即可,秒级别数据延迟,30W/S吞吐(2kb size),小于30秒延迟。
- 对于RDS中的数据,DMS支持CDC同步到Redshift中,MySQL开启Binlog, DMS同步Binlog信息到Redshift。Redshift支持Schema自动变更(比如源端增加列DMS Redshift会自动同步变更),同时DMS也支持跑批全量同步数据。
- 可以通过DMS或者其他CDC工具(比如Debezium,Flink CDC等)将CDC数据发送到Kinesis,通过Redshift Streaming Ingestion 存储过程(Update=Delete Insert)来进行CDC数据实时写入Redshift。
--
04
Amazon Redshift 实时数仓 ML
1. Redshift 实时数仓 ML

业务场景:通过游戏玩家数据预测玩家可能购买的道具推送给玩家购买。
该场景实现方式:KDS通过streaming 将数据加载至Redshift中,通过View的方式将用户的基本信息和道具的基本信息取出做拼接通过Redshift Model创建模型,模型通过训练返回结果。Redshift会自动选择算法训练模型。Redshift在训练模型的时候调用后台的SagerMaker Autopilot服务,该服务自动寻找最佳算法和超参数进行模型训练。训练后的模型会被自动部署为一个函数供直接使用。每天12小时训练一次模型。
2. Amazon Serverless 预览版

- Amazon Redshift Serverless(Preview):Serverless 预览版将运维的工作交给云去做,我们更关注核心业务,做业务上的开发与应用,更简单地去云上的服务,随用随付费。Redshift 已有Serverless Preview版本,通过JDBC直接链接就可以使用。
- Amazon EMR Serverless(Preview):EMR Serverless在云上构建hadoop集群,云上托管Hadoop集群,集群的运维管理工作需要自己承担。EMR Serverless Preview版本不需要在关注集群的管理。
- Amazon MSK Serverless(Preview):MSK Serverless托管的kafka服务,无需关注计算资源,按照流量使用进行收费。
今天的分享就到这里,谢谢大家。
分享嘉宾:潘超 亚马逊云科技 数据分析专家
编辑整理:陈凯翔 亚厦股份
出品平台:DataFunTalk
01/分享嘉宾

潘超|亚马逊云科技 数据分析专家
8年大数据研发架构经验,企业任职从大数据研发>架构师>数据平台 Leader>CTO-SSA,对企业大数据平台的构建有丰富的实战经验。在大数据存储,离线及实时数据分析处理,OLAP 等技术上有深入的研究,在企业级用户画像、推荐系统等业务等场景上有丰富的经验。
02/关于我们
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100 线下和100 线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章700 ,百万 阅读,14万 精准粉丝。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






