理解神经网络的激活函数(神经网络激活函数综合指南)
#群星8月榜#

在人工神经网络(ANN)中,单元被设计成大脑中生物神经元的松散副本。1943年,McCulloch和Pitts设计了第一个人工神经元,它由一个线性阈值单元组成。这是为了模拟人工神经元不只是输出它们接收到的原始输入,而是输出激活函数的结果。这种行为是受到生物神经元的启发,神经元会根据它接收到的输入而激活或不激活。从感知机模型到更现代的深度学习架构,各种各样的激活函数都被使用过,研究人员一直在寻找最完美的激活函数。在这篇文章中,我将描述激活函数的经典属性以及何时使用它们。本文还将介绍更高级的激活函数,如自适应激活函数,以及如何获得最优激活函数。
激活函数特性概述在寻找神经网络的激活函数时,有几个特性必须考虑在内:
- 非线性:众所周知,与线性函数相比,非线性改进了神经网络的训练。这主要是由于非线性激活函数允许ANN分离高维非线性数据,而不是被限制在线性空间。
- 计算成本:在模拟期间的每个时间步都使用激活函数,特别是在训练过程中的反向传播。因此,必须确保激活函数在计算上是可跟踪的。
- 梯度:在训练人工神经网络时,梯度可能会出现梯度消失或梯度爆炸的问题。这是由于激活函数在每一步之后收缩变量的方式,例如,logistic函数收缩到 [0,1]。这可能导致网络在几次迭代后没有剩余的梯度可以传播回来。一个解决方案是使用非饱和激活函数。
- 可微性:训练算法是反向传播算法,需要保证激活函数的可微性才能保证算法正常工作。
本节将描述人工神经网络中最常见的一些激活函数,它们的属性以及在常见机器学习任务中的性能。
分段线性函数
这个函数包含一个最简单的激活函。其范围为[0,1],但导数未在b中定义。
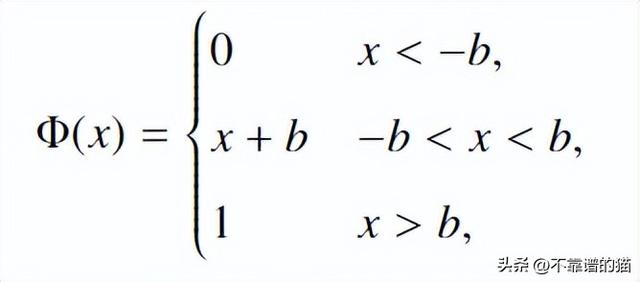

b=2的分段线性函数
一般来说,这个激活函数只用作回归问题的输出。
Sigmoid函数
sigmoid函数是20世纪90年代初最流行的函数之一。Hinton等人将它用于自动语音识别。函数定义为:

这个函数是可微的,这使得它非常适合反向传播算法。

Sigmoid 函数
如图所示,sigmoid函数是有界的,这是它受欢迎的原因。然而,它受制于一个消失的梯度问题,神经网络越深,使用sigmoid作为激活函数对其进行训练的效果就越差。
双曲正切函数
在 2000 年代初期,双曲正切函数取代了 sigmoid 函数。函数定义为:

它的范围为[-1,1],这使得它适合于回归问题,因为它具有零中心的特性。

双曲正切函数
这个函数的主要缺点是饱和。实际上,双曲正切饱和得非常快(比sigmoid快),这使得人工神经网络在训练过程中很难相应地修改权重。但值得注意的是,在循环神经网络中,该函数常被用作隐层单元的激活函数。
整流线性单元
整流线性单元(ReLU)被用来克服梯度消失的问题。它被定义为

值得注意的是,与sigmoid函数和双曲正切函数相反,ReLU函数的导数是单调的。

ReLU 函数
ReLU函数由于其无界性,通常用于分类任务,它克服了梯度消失问题。此外,由于没有指数函数,计算成本比sigmoid更低。这个函数在几乎所有神经网络体系结构的隐层中都使用。主要的缺点是这个函数对于负值有一个饱和问题。为了克服这个问题,有人建议使用leaky ReLU:

所有这些函数都可以在两个标准分类任务上进行比较:MNIST和CIFAR-10。MNIST机器学习数据库包含手写数字,CIFAR-10包含10个类别的对象。我在这里提供了文献中每个激活函数的最佳性能的总结,这些性能与体系结构无关。
|
MNIST |
CIFAR-10 | |
|
Sigmoid |
97.9 |
89.43 |
|
Tanh |
98.21 |
88.19 |
|
ReLU |
99.53 |
95.3 |
|
Leaky ReLU |
99.58 |
95.6 |
上一节强调了激活函数的选择取决于网络必须解决的任务及其在网络中的位置,如隐藏层或输出层。因此,与其试图找到最佳激活函数,不如尝试击败我们使用的现有函数。这就是引入自适应激活函数的原因。
参数激活函数我要讨论的第一类自适应函数是参数激活函数。例如,可以使用参数双曲正切函数:


参数双曲正切函数
参数a和b适用于每个神经元。在训练过程中,使用经典的反向传播算法,参数会发生变化。
参数激活函数的优点是:通过添加参数,几乎可以用这种方式修改任何标准激活函数。当然,添加的参数增加了计算的复杂性,但它会带来更好的性能,它们被用于最先进的深度学习架构。
随机自适应激活函数
引入自适应函数的另一种方法是使用随机方法。它首先由Gulcehre等人提出,它包括使用结构化和有界噪声来加快学习速度。换句话说,在将确定性函数应用于输入之后,再添加一个有特定偏差和方差的随机噪声。这对于饱和的激活函数尤其有用。随机自适应函数的一个例子如下:

随机自适应 ReLU
这种类型的噪声激活函数对于饱和非常有用,因为噪声应用于阈值之后,因此它允许函数超过阈值。在参数激活函数的情况下,这些函数在大多数机器学习任务中优于固定激活函数。
下面是一些自适应函数在经典MNIST和CIFAR-10任务中的性能总结:
|
MNIST |
CIFAR-10 | |
|
Adaptive Tanh |
99.57 |
91.14 |
|
Adaptive ReLU |
99.75 |
96.89 |
自适应函数确实比它们的对应函数具有更好的性能。
最后近年来,神经体系结构变得越来越大,拥有数十亿个参数。因此,主要的挑战之一是获得快速收敛的训练算法,这可以通过使用自适应函数来实现(尽管它们的计算成本很高)。它们在分类和回归机器学习任务中都有较高的表现。
,
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






