一步一步动画图解LSTM和GRU(一步一步动画图解LSTM和GRU)
作者:Michael Nguyen编译:ronghuaiyang导读昨天的文章中提到了Michael的这篇文章,今天就来看看,做序列信号的处理,离不开LSTM和GRU,很多人会觉得这两个东西很复杂,特别是LSTM,里面一堆的门,看看就头晕。不过,其实只要帮你梳理一下,理解起来还是很清楚的,其实就是一个信息流动的过程,这次带给大家的分享更是通过动图的方式,让大家一次看个明白。
大家好,欢迎来到长短期记忆(LSTM)和门控循环单元(GRU)的图解指南。我是Michael,我是AI语音助手空间的机器学习工程师。
在这篇文章中,我们将从LSTM和GRU背后的直觉开始。然后,我将解释LSTM和GRU的内部机制。如果你想了解这两个网络背后发生了什么,那么这篇文章就是为你准备的。
本来这里有个视频的,不过油管上不了,给个地址给大家,大家各自想办法吧:https://youtu.be/8HyCNIVRbSU。
问题,短期记忆循环神经网络受短期记忆的影响,如果序列足够长,他们就很难将信息从早期的时间步传递到后期的时间步。因此,如果你想处理一段文字来做预测,RNN可能从一开始就遗漏了重要的信息。
在反向传播过程中,循环神经网络存在梯度消失问题。梯度是用来更新神经网络权重的值。消失梯度问题是指,当梯度随着时间的推移而缩小时。如果梯度值变得非常小,那它对学习就没有太大的帮助了。
Gradient Update Rule
所以在循环神经网络中,获得小梯度的层停止了学习。这些通常是较早的层。因此,由于这些层无法学习,RNN可能会忘记在较长的序列中之前看到的内容,从而产生短期记忆。
解决方案就是LSTMs 和GRUs
LSTMs 和 GRUs 可以用来解决短期记忆的问题。它们有一种叫做“门”的内部机制,可以调节信息的流动。
这些门可以知道序列中哪些数据是重要的,是保留还是丢弃。通过这样做,它可以将相关信息沿着长链传递下去,从而做出预测。几乎所有的业界领先的循环神经网络都是通过这两种方式实现的。LSTM和GRU可以用于语音识别、语音合成和文本生成。你甚至可以用它们为视频生成标题。
好了,在这篇文章的最后,你应该对LSTM和GRU擅长处理长序列的原因有了一个扎实的理解。现在,我将用直观的解释和说明来解决这个问题,并尽可能避免使用数学。
直觉
让我们从一个思想实验开始。假设你正在查看网上的评论,决定是否是否要买麦片,你会先看一下评论,看看别人认为它是好的还是坏的。
当你阅读评论时,你的大脑潜意识里只记住重要的关键词。你学会了“amzing”和“perfectly balanced breakfast”这样的词,你不太喜欢像“this”、“give”、“all”、“should”这样的词。如果第二天朋友问你评论说了什么,你可能不会逐字记住,你可能记得要点,比如“will definitely be buying again”。如果你和我差不多的话,其他的词就会从记忆中消失。
这就是LSTM或GRU的本质。它可以学会只保留相关信息进行预测,而忘记无关的数据。在这种情况下,你记住的单词使你判断它是好的。
复习一下循环神经网络
为了理解LSTM或GRU是如何做到这一点的,让我们复习一下循环神经网络。RNN是这样工作的:将第一个单词转换成机器可读的向量,然后RNN逐个处理向量序列。
Processing sequence one by one
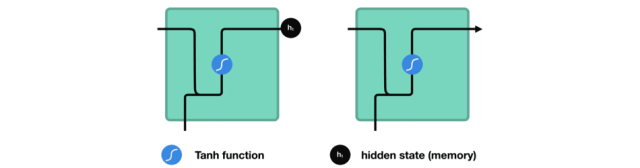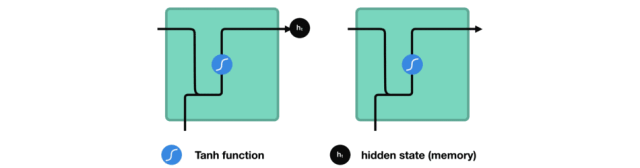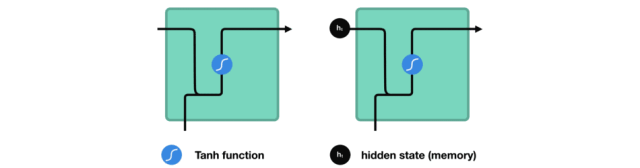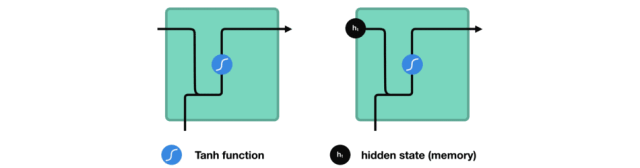
在处理过程中,它将前一个隐藏状态传递给序列的下一个步骤,隐藏状态充当神经网络存储器。它保存网络以前看到的数据的信息。
Passing hidden state to next time step
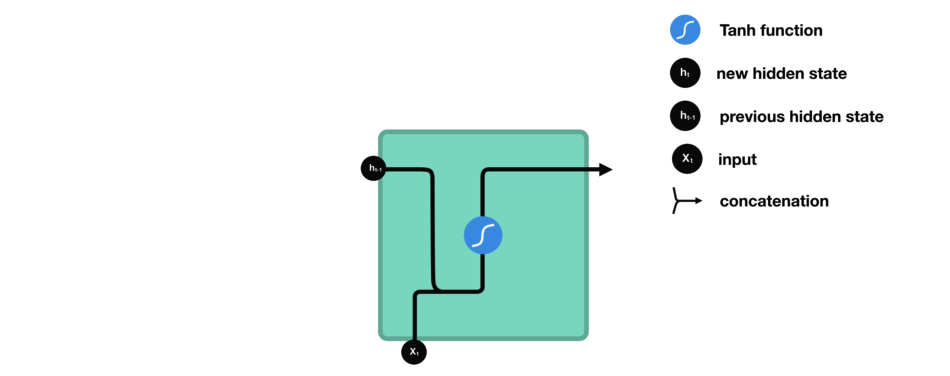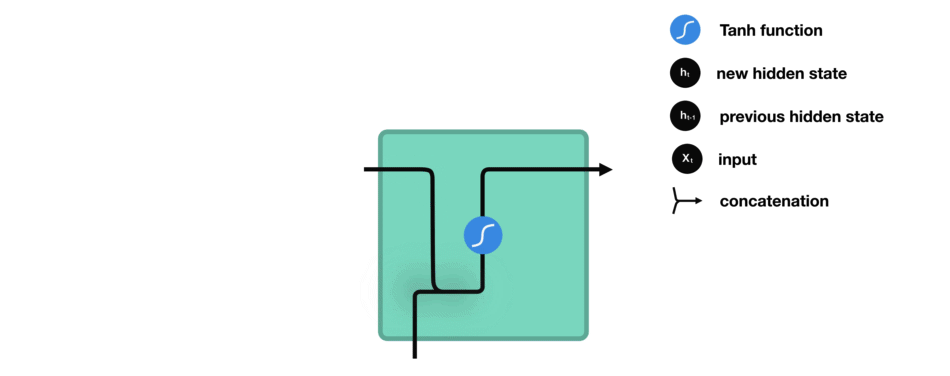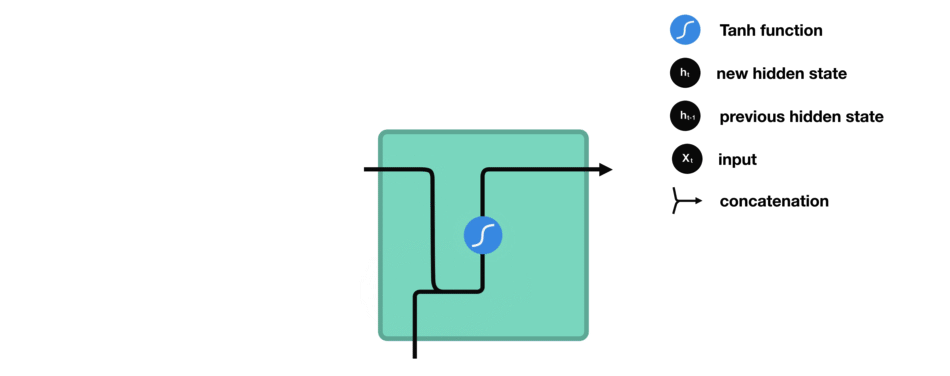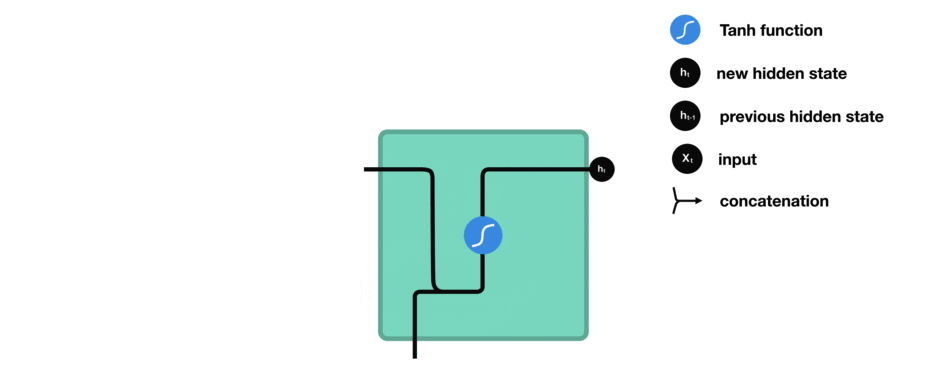
我们看下RNN的一个cell,看看如何来计算隐藏状态。首先,将输入和之前的隐藏状态组合成一个向量。这个向量和当前输入和以前输入的信息有关。该向量经过tanh激活,输出是新的隐藏状态,即网络的记忆。
RNN Cell
Tanh激活
tanh激活函数用于调节流经网络的值,tanh函数压缩后值在-1和1之间。
Tanh squishes values to be between -1 and 1
当向量流经神经网络时,由于各种数学运算,它会进行许多转换。假设一个值连续的乘以3,你可以看到一些值是如何爆炸并变成天文数字的,从而导致其他值看起来就微不足道了。
vector transformations without tanh
tanh函数确保值在-1和1之间,从而调节神经网络的输出。你可以看到在从前面来的值是如何通过tanh函数,将值保持在tanh函数允许的边界范围内的。
vector transformations with tanh
这就是RNN,它内部的操作很少,但是在适当的环境下(比如短序列)可以很好地工作。RNN使用的计算资源比它的进化变种LSTM和GRU少得多。
LSTM
LSTM具有类似于循环神经网络的控制流。它在向前传播时处理传递信息的数据。不同之处在于LSTM cell内的操作。
LSTM Cell and It’s Operations
这些操作允许LSTM保存或忘记信息,现在看这些运算可能会有点难,所以我们会一步一步地过一遍。
核心概念
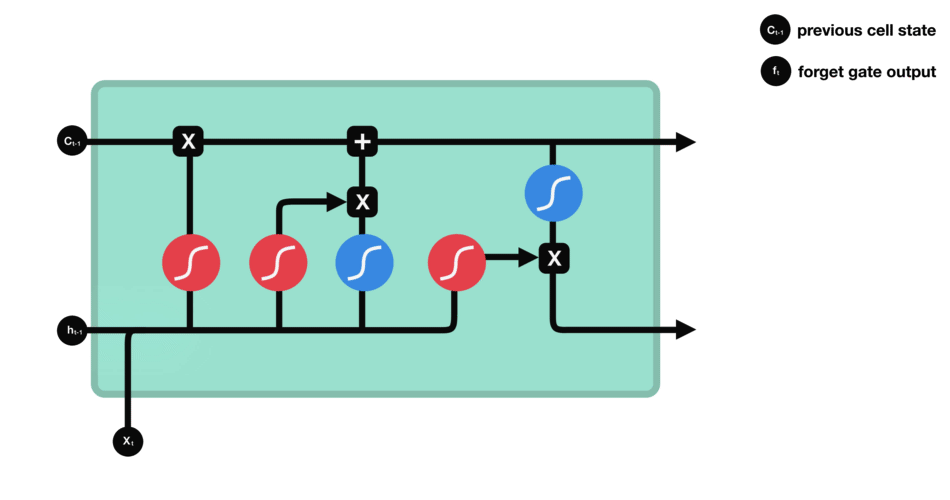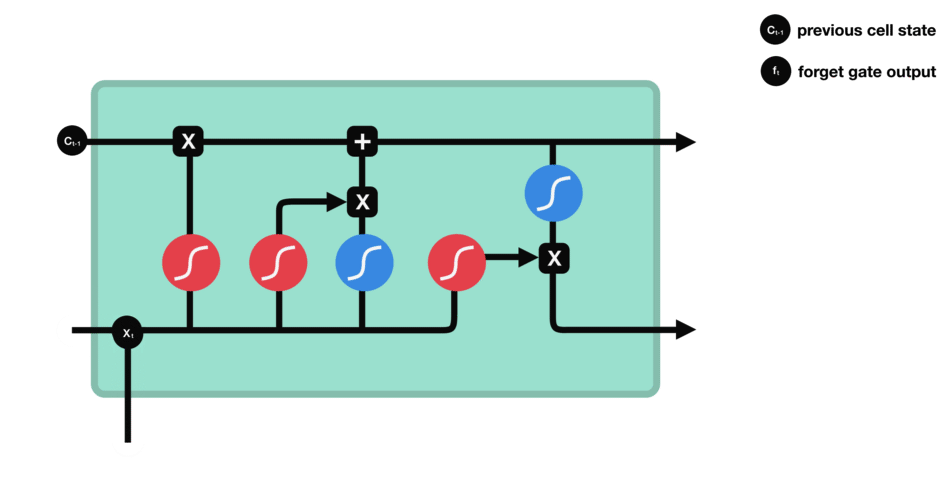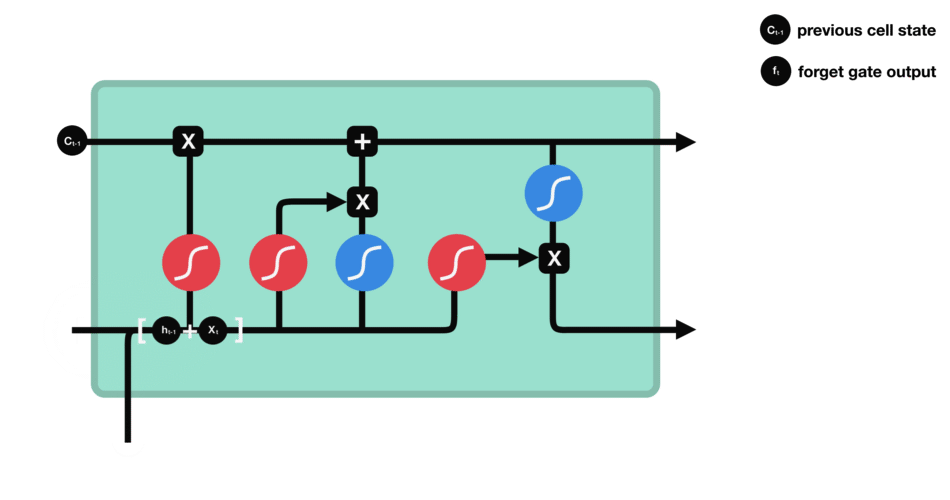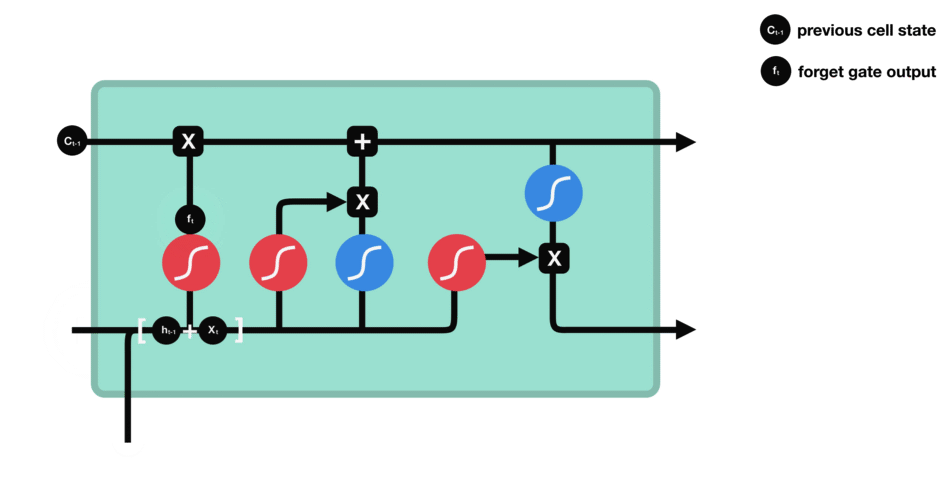
LSTM的核心概念是cell状态,还有各种各样的门。cell状态充当传输高速公路,沿着序列链传输相关信息。你可以把它看作网络的“存储器”。理论上,cell状态可以在整个序列处理过程中携带相关信息。因此,即使是早期时间步骤的信息也可以传递到后期时间步骤,从而减少短期记忆的影响。当cell状态运行时,信息通过门被添加到cell状态或从cell状态中删除。这些门是不同的神经网络,决定哪些信息是允许的cell状态。这些门可以在训练中学习哪些信息是相关的从而进行保持或忘记。
Sigmoid
门中包含sigmoid激活函数。sigmoid激活函数和tanh激活函数很类似,只是它压缩之后不是-1和1之间的值,而是0和1之间的值。这有助于更新或忘记数据,因为任何被乘以0的数字都是0,从而导致值消失或“被遗忘”。任何数乘以1都是相同的值,所以这个值保持不变。“网络可以知道哪些数据重不重要,因此可以忘记或保留那些数据。”
Sigmoid squishes values to be between 0 and 1
我们再更深入地研究一下这些门在做什么,我们有三个不同的门来调节LSTM cell中的信息流,遗忘门,输入门,和输出门。
遗忘门
这个门决定了哪些信息应该丢弃或保留。来自以前隐藏状态的信息和来自当前输入的信息通过sigmoid函数进行传递。结果在0到1之间。越接近0表示忘记,越接近1表示保留。
Forget gate operations
输入门
我们使用输入门来更新cell状态。首先,我们将之前的隐藏状态和当前输入传递给一个sigmoid函数。它将值转换为0到1之间来决定更新哪些值。0表示不重要,1表示重要。你还需要将隐藏状态和当前的输入送到tanh函数中,以得到-1到1之间的值,帮助调节网络。然后将tanh输出与sigmoid输出相乘。sigmoid输出将决定从tanh的输出中保留哪些重要信息。
Input gate operations
Cell状态
现在我们有了足够的信息来计算cell的状态。首先,cell状态逐点乘以遗忘向量。如果将其乘以接近0的值,则有可能降低cell状态下的值。然后我们从输入门获取输出,并进行逐点加法,将cell状态更新为神经网络认为相关的新值。这就得到了新的cell状态。
Calculating cell state
输出门
最后是输出门。输出门决定下一个隐藏状态应该是什么。请记住,隐藏状态中包含之前输入的信息,隐藏状态也用于预测。首先,我们将之前的隐藏状态和当前输入传递给一个sigmoid函数。然后我们将新修改的cell状态传递给tanh函数。我们将tanh输出与sigmoid输出相乘,以决定隐藏状态应该包含哪些信息,输出是隐藏状态。新的cell状态和新的隐藏状态然后被转移到下一个时间步骤。
output gate operations
回顾一下,遗忘门决定了前面的步骤什么是相关的需要保留的。输入门决定从当前步骤中添加哪些相关信息。输出门决定下一个隐藏状态应该是什么。
编程Demo
这里有一个使用python伪代码的示例。
- 首先,将以前的隐藏状态和当前输入连接起来。我们叫它组合向量。
- 把组合向量送到遗忘层,该层去掉了不相关的信息。
- 使用组合向量创建候选层,候选向量中包含了可能会添加到cell状态中的值。
- 组合向量也被输入到输入层,该层决定应该将来自候选向量的哪些数据添加到新cell状态。
- 在计算遗忘层、候选层和输入层之后,使用这些向量和之前的cell状态计算新的cell状态。
- 然后计算输出。
- 将输出与新的cell状态逐点相乘会得到新的隐藏状态。
就是这样!LSTM网络的控制流程是几个张量操作和一个for循环,你可以使用隐藏状态进行预测。结合所有这些机制,LSTM可以选择在序列处理过程中哪些信息是需要记住的,哪些信息是需要忘记的。
GRU
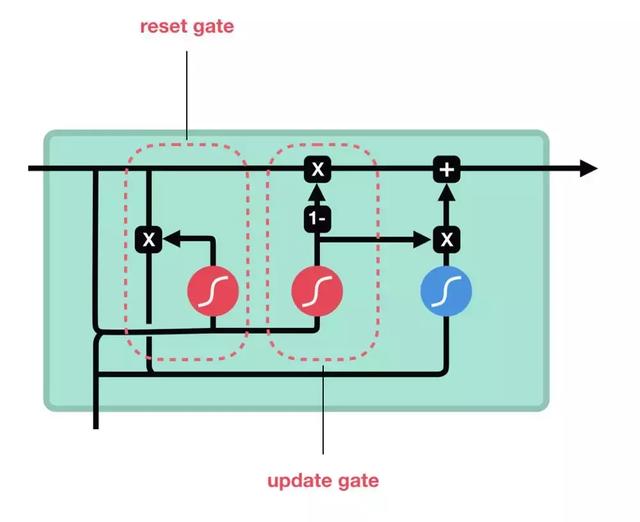
现在我们知道了LSTM是如何工作的,让我们简单地看一下GRU。GRU是新一代的递归神经网络,与LSTM非常相似。GRU摆脱了cell状态,并使用隐藏状态来传输信息。它也只有两个门,一个复位门和一个更新门
GRU cell and it’s gates
更新门
更新门的作用类似于LSTM的遗忘门和输入门,它决定丢弃什么信息和添加什么新信息。
复位门
复位门用来决定有多少过去的信息要忘记。
这就是GRU,GRU的张量运算更少,因此,比LSTM的训练要快一些。目前还没有一个明确的优胜者。研究人员和工程师通常同时尝试以确定哪种方法更适合他们的场景。
就是这么多
综上所述,RNN具有较好的序列数据处理能力和预测能力,但存在短时记忆问题。LSTM和GRU使用称为门的机制来缓解短期记忆问题。门就是控制信息在序列链中流动的神经网络。LSTM和GRU可以应用于语音识别、语音合成、自然语言理解等领域。
原文链接:
https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
更多文章,请关注AI公园
,















免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






