3d偏差公式和范围(最新3D目标检测文章汇总)
作者:蒋天园
来源:公众号@3D视觉工坊
前言3D目标检测在ECCV20的文章中呈现依旧火热的研究趋势,本文对目前笔者看到过的ECCV20和ACM MM20的3D目标检测文章做一个汇总,分类方法按照该方法是否在对应数据集上实验作为分类方法。
ECCV20在ECCV20接收的文章中,仍然在KITTI上做实验的文章有两篇,如下列举,两篇文章都是采用多模态融合的研究工作,即点云信息和Image信息在特征层融合的方法。
3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial Feature Fusion for 3D Object Detection论文链接:https://arxiv.org/pdf/2004.12636笔者已经在前面的博文中细致的讲解了这一篇将image信息首先转化到点云BEV视角上,然后将特征插值到voxel中心的文章。核心创新点就是提供了一种image信息和点云融合的新思路,以往的Image和点云的融合都是通过pix2point的索引矩阵得到图像像素到点云的索引,然后将图像分割特征附加在对应的点云中。
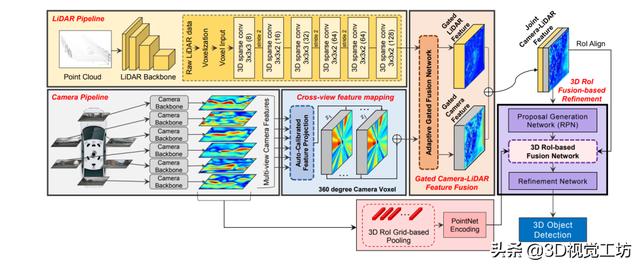
论文链接:https://arxiv.org/pdf/2007.08856
如下图所示的网络结构图,首先可以看出这也是一篇Image信息和点云信息融合的研究,其次可以简单看出融合的方法是采用multi-scale的feature-fusion融合,主体backbone是pointnet 网络结构;图像stream的结构主要是一个FPN层的语义分割特征,通过作者设计的多个L1-Fusion模块,作者采用对应scale的融合特征来解决图像信息和点云信息的互补补全。第二个创新点在于作者提出的CE-loss,该损失函数联合了置信度分数和与gt的IOU大小,认为置信度大的proposals对应的IOU重合度也应该相应比较大。就作者文中的实验来看,在添加了CE-loss后,其在val上的精度可以提升3%。

作者单位是谷歌和MIT,主要创新点包括:(1)作者设计了一个pillar-based的3D目标检测框架,该架构在多个数据集上达到state-of-the-art的结果,不过实验是在waymo数据集上进行的。(2)作者还设计了一个pillar-based的Box回归结构,比以往的anchor-based和point-based的提proposals的方法表现更好(3)作者分析了multi-view feature learning,并证实了cylindrical-view 是BEV的最好的互补的视图。

上图表示本文的主体网络结构,点云首先会分别在BEV和CYV视角上进行各自的特征提取,然后将这两个视角的特征进行融合,然后将fusion后的点域特征投影到BEV视角上,再接目前常用的二维RPN做回归和分类。
Active Perception using Light Curtains for Autonomous Driving论文链接:https://arxiv.org/pdf/2008.02191.pdf开源链接:http://siddancha.github.io/projects/active-perception-light-curtains作者单位是CMU,该文提出使用light-curtains(一种传感器)来提高自动驾驶中3D目标检测的识别性能,而且本文的另外一个创新点在于利用3D目标检测预测不确定性来知道运动感知。主要创新点包括有:(1)利用预测不确定性作为指导来提升3D目标检测的运动感知能力。(2)作者利用最大化信息增益,在考虑到网络不确定性的前提下,设计了一个最优化算法来确定哪里适合设置light-curtains(3)作者也提出了一种方法来训练生成online light curtain data。

主体网络结构如上图所示,上面的分支表示作者采用一个单线雷达做目标检测任务,detector的不确定度被用来最优化的放置一个包含了最大不确定区域的light curtain。然后那些通过light curtain检测出来的点(表示为绿色)返回到detection最初始的划分voxel阶段,然后进一步更新目标检测结果。作者在Virtual KITTI上做的实验,式样效果如下,可以看出多条light-curtains是能带来更好的精度提升。

论文链接:https://arxiv.org/pdf/2007.16100.pdf作者团队是韩松实验室。本文不是一篇常规的目标检测文章,而是在卷积上做文章,该模块可以在点云的任何任务中使用,当然也就包括了点云目标检测任务。本文的主要创新点包括了(1)作者设计了一个轻量级的3D卷积模块,在硬件有限的情况下取得了不错的结果。(2)引入了第一个3D搜索网络, 3D-NAS,自主搜索最好的3D网络结构
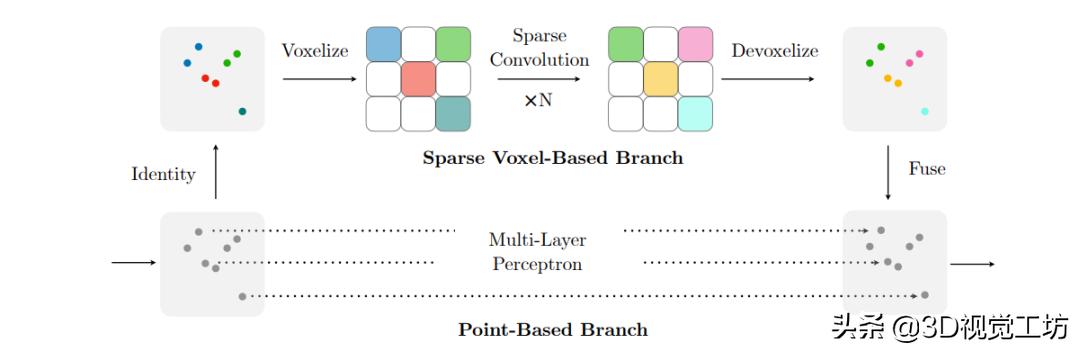
上图表示结合voxel和point特征提取的卷积结构,该图即是(NIPS19)的文章PVCNN的结构,一方面是高效的采用voxel做了特征提取,另一方面是通过point分支而不采用FPS的耗时结构,可以得到MLP提取的特征,最后采用插值的方式得到融合后的特征。
An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds论文链接:https://arxiv.org/pdf/2007.12392.pdf作者单位是谷歌。本文的主要创新点包括:(1)第一个采用LSTM处理点云序列的网络。并且多帧融合的效果远好于单帧。(2)提出3D 稀疏LSTM,该结构可以保有一定的记忆能力,同时高效的做fusion。

overall的网络结构如上图所示,每一帧的点云信息都是首先通过一个稀疏卷积搭建的U-Net做处理,然后3D稀疏LSTM将backbone特征和memory中的上一帧的特征做融合,然后再通过FPS和NMS对最后的结果做后处理。
Kinematic 3D Object Detection in Monocular Video论文链接:https://arxiv.org/pdf/2007.09548.pdf作者单位是密西根州立大学这是一篇单目video做目标检测的文章,该文章利用运动学运动提取场景动态,提高定位精度。主要的贡献点包括:(1)提出了一个单目vodeo-based的3D目标检测网络,利用集成的运动和3D卡尔曼滤波现实运动约束(2)作者重新构建了3D目标框,即建议将方向重新制定为轴、航向和偏移以及自平衡的三维定位损失,以促进稳定性所需的卡尔曼滤波,以更有效地执行。(3)总的来说,作者仅使用一个单一的模型,就能够实现一个全面的三维场景理解,包括3D bbox,速度,相对运动,不确定性,和自我运动等(4)在单目的3D目标检测中,在KITTI达到了新的SOTA

网络主要的结构如上图所示,首先易容RPN网络预测最先的3D BBOX,然后进一步使用卡尔曼预测速度更新上一次的tracking为这一次的tracking。最后将这一次的跟踪内容和检测做进一步的融合。
ACM MM20Weakly Supervised 3D Object Detection from Point Clouds论文链接 :https://arxiv.org/pdf/2007.13970.pdf作者团队是微软,就题目而言,本文是一篇采用弱监督学习做3D目标检测任务的文章,这在近期的研究中是很少见的。本文的主要贡献点包括:(1)提出了一个无监督的3D目标检测网络,该网络使用所提出的归一化点云密度和几何先验来选择和对齐anchor。作者表示这是第一个弱监督学习的基于点云的3D目标检测网络(2)一个高效的方法将2D图像信息和3D点云融合,该方法可以推广到没有三维标注的情形下使用。

网络结构图如上图所示,网络中第一个重要的部分是无监督proposals提出网络,通过归一化点云密度信息提出proposals。第二个重要的部分是cross-modal transfer模块,该模块的作用是从图像数据集到点云数据集的信息融合。
笔者总结就最近的几篇文章来看,现在文章的研究热点依旧在image信息融合和点云时序信息的融合,而最新的利用弱监督信息来做3D点云目标检测也是将弱监督这一个大热门研究点和3D点云融合,这些都还有很多可以值得研究的内容。
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉优质源码,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






