蚂蚁最新经营数据(蚂蚁超大规模商家知识图谱构建及其融合应用)
导读:蚂蚁集团在线下支付、线上服务领域沉淀了海量的数据,涵盖了商家、门店、小程序、品牌等商户数据,以及交易、营销等行为数据,如何合理地组织并自动关联各维度的信息,为蚂蚁建设丰富、高效、精准、一体化的商家知识基础设施,是一项既有挑战又有意义的工作。本文将围绕蚂蚁线下线上联动的商家特色,首先介绍商家知识图谱的构建方法,接着重点介绍在工业界大规模图谱跨业务融合以及图谱认知应用的落地实践,最后介绍今年将重点投入的图谱开源开放工作,希望能够为知识社区做一些贡献。
全文将围绕以下四点展开:
- 商家图谱概览
- 图谱构建&融合
- 图谱开放
- 总结
01
商家图谱概览
首先介绍一下蚂蚁商家图谱的背景和体系。
1. 背景介绍
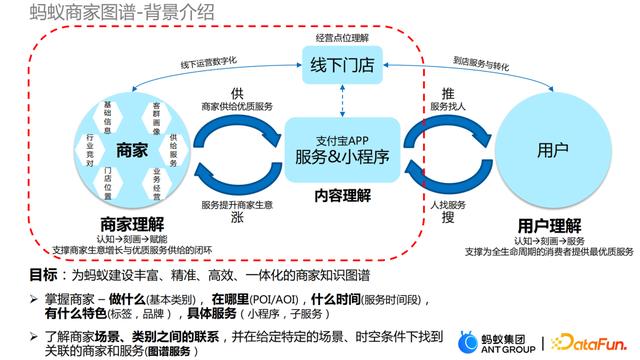
在蚂蚁集团生态体系里有两个核心的要素,即商家和用户。而商家在蚂蚁的体系里是比较复杂的,首先它既连接了线下实体门店,用户可以通过扫支付宝二维码实现便捷支付。
其次,商家可以在线上通过支付宝提供小程序的方式同用户进行关联,即用户可以在支付宝上搜索小程序满足自己的需求。蚂蚁商家这种线上和线下为用户提供服务的方式,对我们理解商家提出了很大挑战:
第一点是线下门店在收录到蚂蚁商家库时,能收集到的信息主要是地理位置、商家类目等(问题一:商家基础信息匮乏)。
第二点是商家在支付宝上提供的小程序存在多渠道来源,比如商家可以通过口碑、饿了么、大麦以及其它第三方等渠道进入到支付宝小程序生态中,这样同一家门店在线上会有多种载体存在,同时各个载体间的商家数据是割裂异构的(问题二:商家信息多源异构)。
基于上面的背景和挑战,我们有必要为蚂蚁集团建设丰富、精准、高效、一体化的商家知识图谱。建设商家知识图谱,我们主要有两个目的,一个是掌握商家的信息,比如这个商家是做什么的(基本类型),在哪里(POI/AOI),什么时间(服务时间段)为用户提供哪些特色的服务(经营内容);第二个就是要了解商家场景与类别之间的联系,这样就可以在给定的场景和时空找到商家和服务的关联,从而可以给用户做出精准推荐。
2. 体系建设
接下来介绍商家知识图谱的体系建设。

我们会从两个视角来看商家图谱的建设。一个是算法视角,这是我们的核心能力。从下往上看,首先是知识的抓取,即数据来源,可以来自于业务本身存在的数据,也可以来自于外网抓取的数据。在获取到数据之后就需要知识定义,即知识建模,我们需要对数据进行知识的约束。再向上一层就是对知识进行抽取、结构化和对齐,随后是如何对结构化的知识进行存储,以及子图查询。再进一步是知识的应用,例如跨图谱的知识融合、知识的Embedding表征、基于知识图谱的知识推理满足智能客服和智能问答的一些需求,还可以做知识匹配等。
另一方面是从落地视角看如何将算法的能力更好地应用。从下往上看,最底层是基础依赖,一个是图计算引擎,包括图存储形式以及数据库选择,第二个需要做一些认知计算,比如需要标注平台、众包进行知识质检。再向上是图谱底座,主要分两个部分:NLP平台和图谱平台。NLP平台是通用的,会提供多种NLP的模型服务。图谱平台是支撑图谱底层的能力建设,比如schema建模、图谱存储和更新,以及规则引擎如何支持图推理。再向上一层是图谱的常见算法:一类是图谱构建算法,比如实体识别、关系抽取、概念挖掘等;一类是图谱推理算法,比如知识表征、规则挖掘、结合领域知识和神经网络进行神经符号的推理,以及因果推断等。顶层是业务赋能,既会支持支付宝的搜索推荐营销的业务,还会对接大安全、企业风控以及商家增长的业务。
整体上商家知识图谱就是按照这个体系建设的。
--
02
商家图谱构建&融合应用
接下来我会详细介绍商家知识图谱的构建以及融合应用。主要会分为三部分,第一部分是图谱构建,重点介绍知识加工的pipeline,第二部分是我们当下的一个重点工作,即跨图谱的融合,最后简单介绍图谱认知的一个应用案例。
1. 图谱构建
① 整体框架
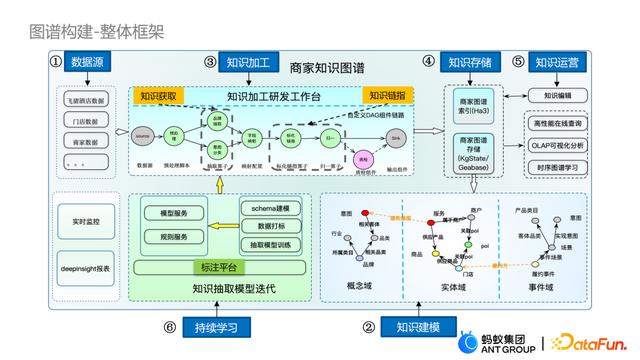
首先系统地介绍一下图谱构建的整体框架。这里共有六个组成部分。
- 数据源
- 知识建模
- 知识加工
- 知识存储
- 知识运营
- 持续学习
首先是数据源的获取,在商家图谱的构建过程中,我们的数据是多源异构的。第一种是结构化数据,来源于业务团队积累,在阿里蚂蚁基本上是以ODPS和MySQL的形式存在。第二种数据源是半结构化数据,这里的key是不规范的,跟schema里定义的key无法直接匹配上,需要做属性归一。半结构化数据一般来源于百科的InfoBox,还有一些垂直网站。第三种是非结构化数据,包括自由文本和图片,而知识加工需要对这部分非结构化数据做信息抽取以及链指等处理。
在获取到数据源后,需要进行知识建模。知识建模本质上就是schema的定义,这里我们按照概念域-实体域-事件域,来对知识进行定义。概念域是具体实体的抽象,目的是建设认知概念的网络,基于这些概念之间的上下位、相关、相反关系以及因果和顺承关系来实现语义推理的工作。实体域就是跟业务强相关的实例,如商家图谱中的商户、门店、商品、服务、用户等,实体域构建为了与专家知识解耦,以便运营侧统一管理。事件域是我们重点建设的事理图谱的一部分,这里特指用户的浏览行为和支付行为,以这些行为背后的事件作为结构化知识的沉淀,来增强实体域里的一些静态知识。
第三部分是知识加工。知识加工是提供了一个自定义DAG的图谱构建链路。这里用户可以根据自己的需要来进行算子的封装,比如数据源的接入和清洗(有数据去噪需求),若数据质量很高则可以跳过预处理。对于非结构化的或者半结构化的数据,我们在进行数据获取时,可能会涉及到对知识的分类或者抽取,如实体抽取、关系抽取等。在知识获取后,要做字段的映射,即将知识的结构化数据和知识建模里的schema做映射。随后需要实体链指归一的工作,包含两个部分,一是实体链接,另一部分是实体归一或属性归一。做完实体链指之后可以按需加入质检模块,质检是指当我们对链指结果不够满意时,使用众包的方式进行质量评估。评估发现准确率较高时,就可以写入图谱中,否则拒绝链指结果(考虑更新算法组件)。
在进行完知识加工后,需要对知识进行存储。知识存储也是非常重要的一环。为了支持不同的业务需求,我们设计了对知识进行分层的存储架构,从而能够支撑毫秒级的实时在线查询、秒级别的平台知识运营,以及大规模的图计算数据处理,我们也可以提供分钟级的更新。
第五部分就是基于知识存储上进行的知识运营,我们可以在图谱平台上做知识查询、知识编辑,也可以进行可视化分析,还可以基于图谱的大规模知识表示和推理。
最后,有了高质量的知识存储,可以反过来帮助我们进行持续学习。通过图谱里的这些高质量数据,可以不断优化知识获取、知识链指中涉及的各类算子。
介绍完整体框架之后,我会重点介绍几个环节,比如知识获取、知识链指中用到的一些算法模块。
② 知识获取-文本分类
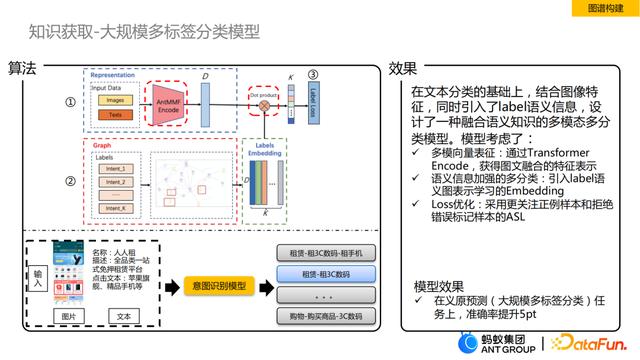
这里介绍知识获取部分的一个分类模型。相对于一般的文本分类,我们结合了图片信息,并且引入了label的语义信息,提出了一种融合语义知识的多模态多分类模型。
在我们的一些场景中,比如商户门店分类、小程序页面的意图分类,这里面会有丰富的图片信息,而这些图片中会有结构化的layout信息。这些场景中还有很多object,这些object的语义含义很明确,将图片信息进行融合后得到的多模语义表征,比纯粹的文本表征语义更加丰富。其次,我们面临的label可能上千甚至上万的规模,这些label的背后不仅仅是一个id,它的名称(比如“租赁-租3C数码-租手机”)有非常强的语义信息,同时这些label之间本身也会存在上下位、同义、相关等关系,自然而然可以将label从平铺形式转化为图的形式,生成label graph,接着基于图表征方法对label进行embedding表示。如果label没有名称或者结构信息,只需做一个随机的初始化。如果label有名称,可以使用Bert类模型去提取一个文本的初始化表征。在得到label的表征后,和输入的表征进行浅层的交互,得到label的分布,比如单分类任务只需要简单加一个softmax,如果是多分类,可以把softmax变成sigmoid。上面这些是我们模型的特点,同时在效果上,模型针对hownet的每个词进行义原预测,这里label有2000类 ,在这个任务上,我们的模型相比于baseline有5pt的提升。
值得一提的是,我们的模型有两个点可以优化,第一个是怎么更好地进行多模的表征。多模态的预训练有两种方式,一种是单流,另一种是双流,至于哪种方式适合解决当前业务问题,需要具体问题具体分析。在Encode这里做预训练优化会对整体模型效果有一定提升。第二点是对于输入表征和label表征,我们当前只是做了浅层的交互,如果后续在这里做一个深层的交互,类似于cross attention,可能会对效果提升有帮助。
③ 知识获取-文本抽取
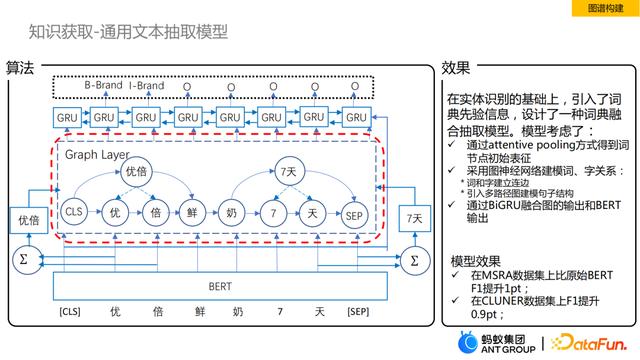
接下来介绍我们在文本抽取上的模型。众所周知,文本抽取涵盖范围是比较广的,包括实体抽取,关系、属性的抽取,还有SPO的抽取。这里主要介绍通用的实体抽取的模型。按图上这个框架从下往上看,最下面是用Bert获得token表征,上面一层加入了graph layer,再上面是双向的GRU,最后是label预测。相比直接用Bert做实体抽取,差别在于我们模型加入了graph layer这一层。当前业界和学术界都在知识增强的NER这个方向进行了大量探索,研究关键在于如何把领域词信息放入知识抽取的模型中,一些做法是将这部分信息直接加在Bert的输入层,即做了简单的拼接。我们模型是在graph layer中通过构建图神经网络来学习词与字之间交互的特征。获得这个特征之后,再通过BiGRU对Bert的输出和graph layer输出进行融合,从而进一步预测每一个token的label信息。我们的模型在MSRA数据集上比仅使用Bert在F1上有1pt的提升,在CLUNER数据集上同样也有0.9pt的提升。
但是这种词增强的NER,也存在在引入领域词的过程中引入噪声的问题,比如会存在一些边界冲突或语义冲突。如何避免噪声的引入也是接下来主要研究的一个问题点。
④ 知识链指
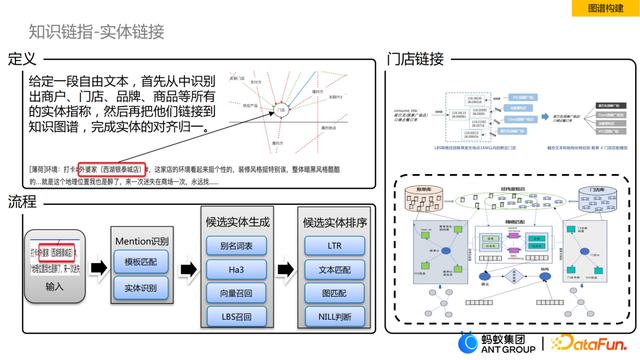
重点介绍一下我们在实体链接上的工作。
实体链接,即给定一段文本,首先识别出潜在实体的指称(mention),然后再把他们链接到知识图谱中,完成实体对齐和归一。比如我们有一条评论,将评论中的实体与图谱链接起来,会对这个实体有语义的增强,例如“外婆家”这个商户实体,我们通过跟图谱关联可以进一步获取到该商家关联的商品信息。
实体链接一般流程如图所示,首先对输入的文本进行mention的识别,识别方法可以是简单的模板匹配或者词典匹配,通过模型可以做实体识别。经过mention识别后,进行候选实体生成,这是一个召回的过程,根据识别出来的mention在图谱里召回候选实体。候选实体生成的方法也有很多,比如别名词表召回、Ha3索引召回、基于语义表征的向量召回,还有比较特殊的场景,比如门店召回时,每家门店都会有LBS经纬度信息,可以通过LBS去召回。生成了候选实体之后,需要对候选实体进行排序,常用的排序方式有LTR(Learning To Rank)模型,除了排序模型外,还可以用文本匹配或者图匹配的一些算法来获取Top1结果。但是这样还是存在一些问题,比如识别到的实体在图谱里不存在,这时就需要做NILL判断,判断Top1实体在图谱内是否存在。
我们以消费记录里门店链接作为简单的案例。文本就是一条消费记录,我们主要通过网格的LBS进行召回,召回一公里内的门店信息,然后进行匹配和排序。具体来讲,在匹配任务上,我们尝试了最简单的精准匹配,我们对消费记录中的门店做了结构化提取,同时对门店库中的门店也做了结构化,将这两部分信息做精准匹配。除了精准匹配外,我们也做了基于Bert模型的文本匹配。进一步我们对消费记录里的门店结构化信息同图谱关联,尝试图匹配。最后集成各种匹配方法,训练了LTR排序模型。
2. 图谱融合

在介绍完图谱构建之后,我会重点介绍我们在图谱融合上的工作进展,这里提到的图谱融合更多的是两个领域图谱的跨图谱融合。
在蚂蚁的业务背景中,商家和用户是两大最核心的要素,各个业务团队会基于商家和用户去构建各自的领域图谱,对于一个新的业务需要构建图谱时,重新获取结构化信息构建图谱的成本是很高的,那我们提出了一个比较好的解决方案,以蚂蚁商家图谱为例,我们通过跨图谱融合的方式能够快速帮助业务做一些知识复用和快速验证的过程。我们主要做了不同实体类型但相同实例的融合,以及不同实体类型不同实例的关系连通。最终可以达到三个目的:
- 跨图谱的知识复用
- 减少无效数据拷贝
- 业务快速价值落地
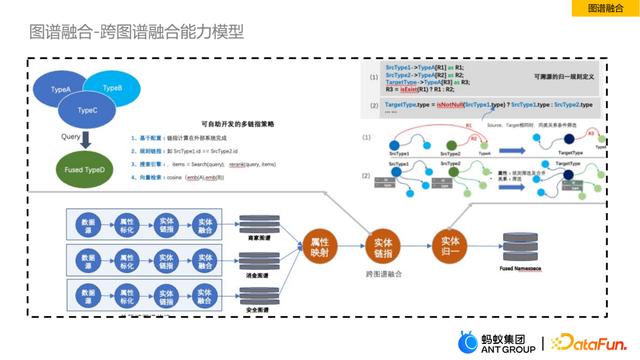
介绍完背景之后,我将简单介绍一下我们跨图谱融合能力的模型。左侧是不同业务领域图谱各自构建的pipeline,比如商家图谱、消金图谱和安全图谱,右侧在属性映射之后就是跨图谱融合的流程,这样设计的好处是各自领域图谱可以各自生产维护,互不影响,在跨图谱融合之后,可以用不同图谱的信息做实体链指和实体归一,最终形成融合后的图谱,以便于开展推理等相关工作。
这里实体链指和上文提到的不太一样,这里是两个图谱的实体链指,针对这里我们提出了可自助开发的多链指策略。如果不同图谱之间实体id保持一致,可以直接进行id的规则映射,另外我们还可以通过搜索引擎,指定不同类型为相同实体,利用搜索方式进行获取,还有向量检索。这些链指方法灵活可配置,可以根据自己的业务选择规则或者模型的方式达到链指的目的。在实体归一这一步中,由于不同实体各自的属性也不一样,需要对属性做溯源,我们提供了可溯源的归一规则的定义,这样可以帮助查找属性来自于哪个图谱。当前基于我们这个能力模型,在阿里内部已经有很多团队进行大量的应用,在业务上也取得了不错的效果。
3. 图谱认知

图谱认知这部分我主要介绍知识表示的一个案例。在支付宝中有一个会场消费券的频道场景(超级567),我们做的是消费券内容理解和深度召回。深入这个场景可以看到,用户需求是很明确的,但是也会有几个痛点,一个是流量结构的头部效应非常严重,通过行为召回的一般都会有马太效应;另一个是用户核销领取行为稀疏,一周或者一个月只进行几次浏览点击;还有不仅是冷启动的用户很多,每天新增的券也很多,新增券背后隐藏着用户的行为很少。
然而这个场景所涉及到的结构化信息就是商家图谱的子图,这里有例如用户、消费券以及消费券背后的品牌和意图等关键节点。用图谱的方式进行召回有一些优势,一个是长尾的item学习更加充分,即对消费券进行结构化之后,相对于之前券与券之间只能通过用户行为关联,使用KG可以通过结构化节点进行关联,实现静态节点的扩张。另一个是结合用户行为和券之间的结构化信息,相当于静态和动态信息进行融合,形成一张动态时序图。这里简单介绍我们的学习过程,这是一个双塔的向量召回模型,唯一的不同就是把图谱的embedding作为特征加到模型输入中。这里采用动态图学习的Embedding,是因为在这个特殊场景下,用户领券行为存在一定的周期性规律,这里的时间信息相当重要,因此需要将静态图学习变成动态图学习。图学习这一部分,我们采用团队自研的encoder-decoder的图表示学习的框架,其中encoder侧做图的节点表征,业界常用的是GNN类图神经网络方法,我们这里使用的是团队自研delta动态图知识表征算法,相对于GNN类的模型引入了时间的信息,将时间信息加入到边的学习过程中。Decoder侧做节点分类或链接预测的任务,这里用户领取和核销的行为做HRT的链接预测任务学习,学到这个表征之后再放到向量召回模型输入中。
效果层面,向量召回模型引入用户和item节点图表征之后,相比baseline有明显的提升,同时对向量召回的结果做统计分析,发现召回的item分布更广,覆盖更多,很大程度上解决了热点效应的问题。关于这个动态知识表征的模型可以关注我们团队后续的相关文章。
--
03
商家图谱开放
第三部分是我们今年会重点做的图谱开放工作,大概介绍一下开源计划。
1. 开放知识
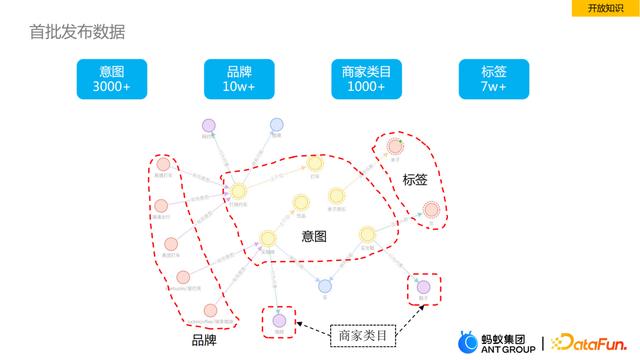
我们首批准备发布的数据是偏概念层的,简单介绍一下概念域里的知识,例如意图、品牌、商家类目以及标签,它们在图里是通过边进行关联。意图是一类复合概念,用户在支付宝中搜索时会带有较强的用户需求,例如“打车”、“查公积金”等,这些需求背后就是用户的意图。品牌不仅来源于支付宝认证的一些数据,也会从外网抓取一些品牌,并进行归一质检,最终沉淀了10万 的品牌。这些品牌与意图也是有关联关系的,比如通过“星巴克”品牌,人们很容易想到在星巴克买咖啡,这就与意图产生了关联关系。同时,每个意图也会和标签有关,比如“买女鞋”的意图下适用人群就是女生。

除了知识的开放,我们也做了一些任务的开放。结合业务我们开放了三个任务,一个是小程序的多意图分类,基于支付宝小程序提供的页面图文信息进行意图的分类,首次开放的数据集大概1万左右。第二个任务是通用概念上下位预测,根据图谱内的已有信息对新增实体或概念识别上下位关系,形成更完善的知识体系,数据集规模有20万左右。第三个是实体识别与分类,这个是比较常规的任务,我们重点放在品牌识别上,品牌识别可以帮助做品牌保护和商家重点运营,相应数据集开放有2万条。官方网站正在准备发布中,敬请期待。
2. 开放SDK能力

最后介绍知识图谱开放SDK能力。SDK开放背后有三层集成的能力,第一个是数据集成,我们可以支持跨业务的图谱融合,以及获取到业务数据后直接挂载到图谱中,进一步可以做可视化分析。第二环节是系统集成,基于Java sdk做知识加工、知识建模、知识查询以及知识推理,快速完成图谱构建。第三部分是算法开放,我们会基于python sdk支持算法一键import,可以进行子图提取,也可以基于tensorflow或pytorch开发图谱算法。
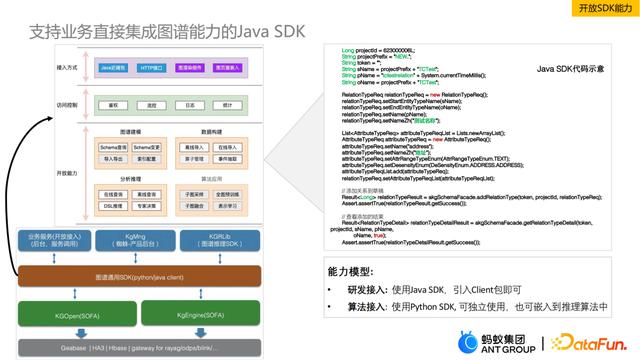
这里详细介绍一下支持业务直接集成图谱能力的Java SDK。从下往上看,最底层是图存储平台Geabase,向上是知识引擎的交互,再上面是图谱查询SDK,最上面是业务层面的支持。图谱通用SDK这块可以分为三部分,一部分是接入,我们提供了一些通用的接口;第二部分是访问控制,会做用户权限的控制,日志等一些数据上的统计;最重要的是开放能力,有图谱建模,即schema的管理能力;还有数据构建,可以做分析推理,最后进行算法应用。基于这套代码SDK,我们可以支持研发的接入,引用Client包即可,还可以支持算法接入,可以独立使用,也可以扩展开发。
--
04
总结与展望
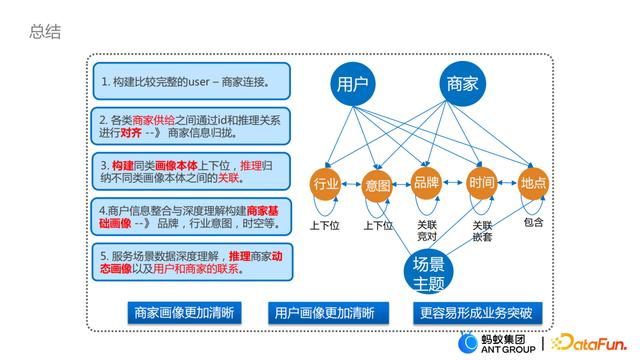
过去一年我们一直在做商家图谱的建设以及数据沉淀,沉淀下来的数据也希望可以开源开放,为社区做一些贡献。我们主要完成商家和用户的连接,并进一步做了概念层面的建设,目的是期望商家和用户的画像更加清晰,能基于商家图谱可以在业务上有更多的突破。目前沉淀下来的实体规模有30亿 ,关系链有400亿 。同时我们也计划将沉淀下来的数据和能力逐步开放出来,并提供一些开源的算子。
今天的分享就到这里,谢谢大家。
阅读更多技术干货文章、下载讲师PPT,请关注微信公众号“DataFunTalk”。
分享嘉宾:贾强槐 蚂蚁集团 算法专家
编辑整理:蔚蔚 华为
出品平台:DataFunTalk
分享嘉宾:

活动推荐:

关于我们:
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100 线下和100 线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章700 ,百万 阅读,14万 精准粉丝。
欢迎转载分享评论,转载请私信。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






