awk命令所有选项的详解(Linux三剑客awk命令补充篇)
Linux三剑客awk命令补充篇:简单案例分析
关于awk的原理等基本知识请参考上五篇:
Linux三剑客awk命令篇一之原理及基本命令
Linux三剑客awk命令篇二之命令操作符
Linux三剑客awk命令篇三之内部变量
Linux三剑客awk命令篇四之流程控制语句
Linux三剑客awk命令篇五之引用shell变量
Linux三剑客awk命令篇五之引用shell变量的几种方式
案例1:
操作文件,按文件内单词出现频率降序排序并输出每个单词的数量。
输入,文件内单词以空格分隔。
输出,单词数量 单词
方法不限。
既然是awk补充篇,我们先用awk来实现。
(1)思路:
让所有单词排成一列,使每个单词成为单独的一行。
再利用sort排序和uniq计数简单处理。
(2) 解答:
步骤1:
模拟数据

步骤2:
利用awk处理数据
即让所有单词排成一列,使每个单词成为单独的一行。
awk 'BEGIN{RS="[ ] "}{print $0}' word.txt
补充:
RS(record separator):输入输出数据记录分隔符
表示每个记录输入的时候的分隔符,既行与行之间分隔符。
RS="[ ] ":即表示以一个或者多个空格

步骤3:
将输出结果交给sort排序
awk 'BEGIN{RS="[ ] "}{print $0}' word.txt | sort
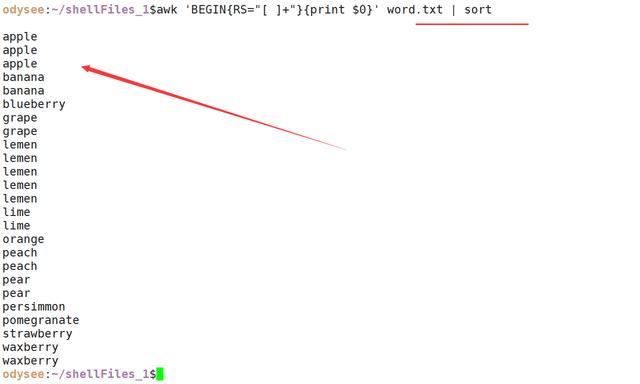
步骤4:
使用uniq进行计数
awk 'BEGIN{RS="[ ] "}{print $0}' word.txt | sort | uniq -c

步骤5:
再对uniq后的结果进行排序,以单词出现频率降序
awk 'BEGIN{RS="[ ] "}{print $0}' word.txt | sort | uniq -c| sort

这里解决这个问题的方法不止一种,可能还会有更加简单直接的方法。
欢迎大家给予宝贵的意见或者建议。
欢迎大家补充或者共享一些其他的方法。
感谢支持。
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






