java 哪些类重写了hash code(分析java.util.Hashtable源码)
基于J11,该类已经淘汰,如果使用线程安全的则用 ConcurrentHashMap ,用线程不安全的则使用 HashMap 。仅与HashMap进行比较
结构以及依赖关系HashTable 的结构如下图

当遇到有同样 Hash 值的情况,会通过链表来解决冲突问题(链接法,通过链表解决冲突问题)。
链接法会随着冲突的增多导致查询时间越来越慢。会出现一种恶劣的情况,当散列算法特别差时;元素总数 n 和某个槽位数 m 中的 k 相等,如下图所示

在这种情况下,查找的时间为 $O(1 a)$ 其中 $O(1)$ 为hash
通过下图可以得知 Hashtable 与其他类似的关系
classDiagram direction BT class Cloneable { <<Interface>> } class Dictionary~K, V~ class Hashtable~K, V~ class Map~K, V~ { <<Interface>> } class Serializable { <<Interface>> } Hashtable~K, V~ ..> Cloneable Hashtable~K, V~ --> Dictionary~K, V~ Hashtable~K, V~ ..> Map~K, V~ Hashtable~K, V~ ..> Serializable
实际上,Hashtable中的每个元素都是一个 Map.Entry<k,v> , Entry 是 Map 的集合形式 用来遍历 Map 。Hashtable实现了该接口,Hashtable就是一个集合,不过存储的是一个一个链表。
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
public K getKey(){...}
public V getValue(){...}
public V setValue(V value){...}
}
Hashtable有几个关键的字段需要注意:
private int threshold; // 可容纳的极限长度,容量*负载因子
private float loadFactor; // 负载因子 该值默认为0.75
如果把Hashtbale比做桶,负载因子就表明一桶水能装半桶还是装满桶还是装四分之一桶。
负载因子越大,能装的水就越多。负载因子总和临界值配合,临界值用来表示什么时候扩容,也就是水装不下了得换一个大一点的桶装水。Hashtable每一次扩容都会扩大到原来的两倍大。
负载因子是对时间和空间的平衡,当负载因子增大空间会比较充足就不需要总是扩容,空间用得较多;如果负载因子小需要不断扩容,但是空间用得少。
通过一个put方法来了解下图简述了put的流程
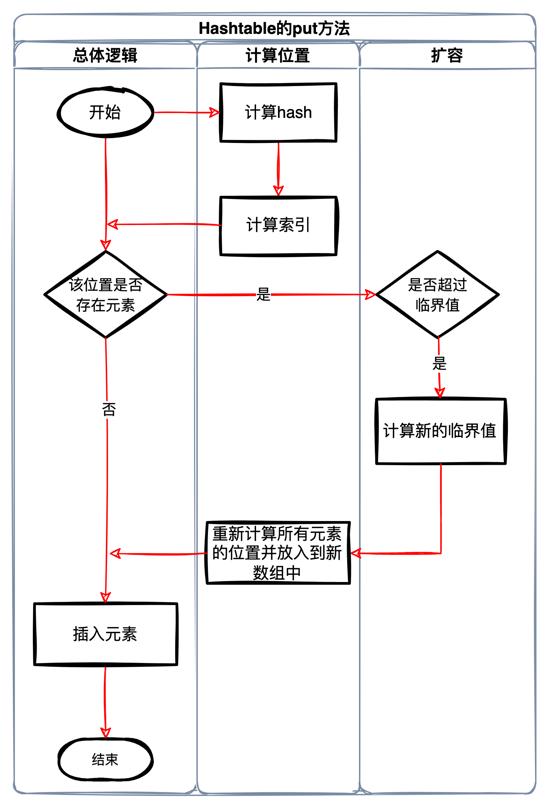
Hashtable中计算位置特别简单,就是简单的除法
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
首先,Hashtable需要知道当前put操作是更新旧值还是插入新值。如果更新旧值就返回旧值并更新它
下面就是一个不断查找链表的过程
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
如果是插入新值则创建一个 Entry 并插入,这是在容量没有超过临界值的情况:
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count ;
modCount ;
当然,如果容量超过临界值则需要扩容
扩容
if (count >= threshold) {
// 扩容,并重新计算每个元素的hash值
rehash();
// 扩容之后插入新值
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
扩容的关键是 rehash() 这个方法。该方法也很简单,只有以下几个步骤:
- 计算新的临界值
- 新临界值超过最大能接受的容量则不再扩充
- 创建一个新table(新的大桶)
- 逐个计算hash值并重新装填table
Hashtable是线程安全的,主要是通过为每个方法加入一个同步锁来解决,如put方法
public synchronized V put(K key, V value) {...}
但是这样的性能还是比较低的,同时不能保证组合方法的线程安全性。
例如 get 和 remove
public V getAndRemove(Object o){
V v = get(o);
remove(o);
return v;
}
这样是不能保证线程安全的
原文链接:https://www.cnblogs.com/Xrtero/p/16482038.html
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






