32位浮点数规格化范围(32位浮点数)
在AI中常提32位浮点数、16位浮点数,混合精度。。这里重点说一下32位浮点数的表示先来一张图
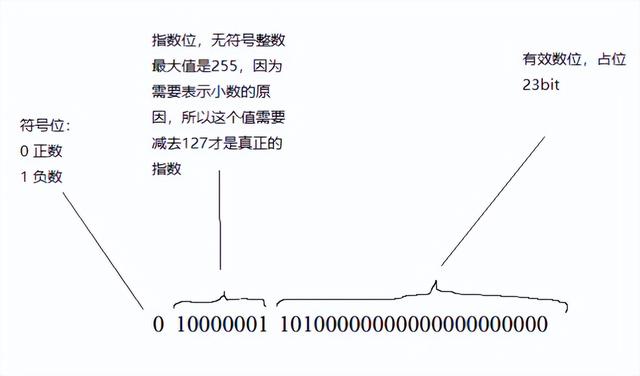
浮点数的计算方式

其中s是符号位,e是指数位,m是有效数位组成的数。m的计算方式是
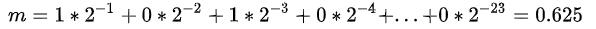
所以上图表示的数字就是

采用这种表示方式的结果是,两个浮点数之间的“间隔”是均匀的。什么意思?
比如说,我想表示浮点数1的话,那么我的二进制位就是:
0 01111111 00000000000000000000000
我想表示2的话,二进制位就是
0 10000000 0000000000000000000000
1和2之间,我能表示的数是有限的,比1大的浮点数,最小的值我只能取到
0 01111111 00000000000000000000001
也就是上述的m是2的-23次方,这就是浮点数的“精度”,于是,你可以看到c 标准库中有一个这个函数:
std::numeric_limits<float>::epsilon()
这个值就是2的-23次方!
还有一点,很明显,用上面的式子,我们没法把值精确地表示0,这显然是无法接受的。于是浮点标准就对e=0的情况做了额外的规定,也就是说当e等于0的时候浮点值就不是乘以1.m,而是乘以0.m。也就是说,如果有效值m是0的话,那么浮点值表示的数字就是0,没有歧义!
接着,如果1.m的1没有的话,我们能表示的最小的值就是0.000…1(2进制)*2(-126),也就是2(-126) * 2^(-23),大约是1.4012985 * 10 ^ (-45)。
我用下面的代码尝试做了输出:
|
|
|
结果是:

与预想的一致。
最后,IEEE 754标准保证-0.0严格等于0.0!
如果e等于255,这种情况同样会被特殊处理。e=255,m=0的话,这就表示无限大,用cout输出就是inf。但如果e=255,m!=0的话,那么这就是一个无效值,输出的结果是nan,尝试代码和结果如下:
|
|
|

于是,我们能表示的最大有效值是1.1111111(二进制)* 2 ^ 127,也就是3.402823… * 10^38。测试代码和结果如下:
uint8_t array6[4] = {0};
array6[3] = 0x7F; array6[2] = 0x7F; array6[1] = 0xFF; array6[0] = 0xFF;
float* f6 = reinterpret_cast<float*>(array6);
std::cout << "f6 = " << *f6 << std::endl;

如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL
AI算力加速之道
,免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






