多路复用主要有几种类型(IO多路复用)
这篇文章总结了常见的 IO 多路复用机制,主要包括 IO 模型、IO 多路复用接口概览、epoll 细节(触发模式、定时器、惊群问题等),Java 上的多路复用实现,Netty 怎么使用 epoll 等内容。
IO 模型
IO 模型相关内容主要参考自:The Sockets Networking API:Unix Network Programming Volume1 第三版第六章,以下 IO 模型说明图均拷贝自该书的 Oreilly Safari 版。
一般来说 IO 模型有如下这些:
- blocking I/O
- nonblocking I/O
- I/O multiplexing (select and poll)
- signal driven I/O (SIGIO)
- asynchronous I/O (the POSIX aio_functions)
拿读数据来说,主要包含的事情有:
- 等待数据到达;
- 将到达的数据拷贝到 Kernel 的 buffer,再从 kernel buffer 拷贝到应用在 User Space 的 buffer
Blocking IO

这里为了简单用 UDP 做例子,从而执行 read 操作时候有数据就返回,没数据就等着,因为每个数据是完整的一块一块发来。TCP 的话 read 是否能返回还会有类似于 SO_RCVLOWAT 影响。
这里主要看到 Blocking IO 是直到数据真的全拷贝至 User Space 后才返回。
Non-Blocking IO
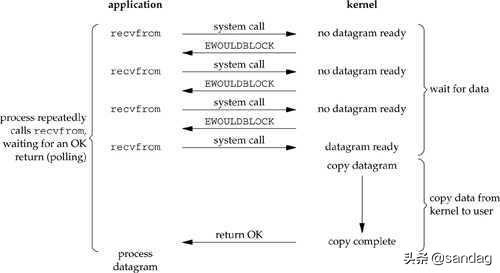
配置 Socket 为 Non-Blocking 模式,之后不断去 kernel 做 polling,询问比如读操作是否完成,没完成则 read() 操作会返回 EWOUDBLOCK ,需要过一会再来尝试执行一次 read() 。这种模式下会消耗大量 CPU。
IO Multiplexing

之前等待时间主要是消耗在等数据到达上。IO Multiplexing 则是将等待数据到来和读取实际数据两个事情分开,好处是通过 select() 等 IO Multiplexing 的接口一次可以等待在多个 Socket 上。 select() 返回后,处于 Ready 状态的 Socket 执行读操作时候也会阻塞,只是只阻塞将数据从 Kernel 拷贝到 User 的时间。
相对于之前的 IO 模型来说 IO Multiplexing 实际做的事情没变化甚至更低效,因为需要两次 System Call 才完成一个读操作。但它的好处就是在可能耗时最长最不可控的等待数据到达的时间上,可以一口气等待多个 Socket,不用轮询消耗 CPU,在多线程模式下还可以让一个线程持续执行 select() 操作,用另一个线程池只执行不会阻塞的,拷贝数据到 User Space 的工作。
实际上 IO Multiplexing 和 Blocking IO 是很像的。
Signal-Driven I/O

首先注册处理函数到 SIGIO 信号上,在等待数据到来过程结束后,系统触发 SIGIO 信号,之后可以在信号处理函数中执行读数据操作,再唤醒 Main Thread 或直接唤醒 Main Thread 让它去完成数据读取。整个过程没有一处是阻塞的。
看上去很好,但实际几乎没什么人使用,为什么呢? 这篇文章给出了一些原因 ,大致上是说在 TCP 下,连接断开,连接可读,连接可写等等都会产生 Signal,并且在 Signal 上没有提供很好的方法去区分这些 Signal 到底为什么被触发。所以现在还在使用 Signal Driven IO 的基本是 UDP 的。
Asynchronous I/O

AIO 看上去和 Signal Driven IO 很相似,但区别在于 Signal Driver IO 是在数据可读后就通过 SIGIO 信号通知应用程序数据可读了,之后由应用程序来实际读取数据,拷贝数据到 User Space。而 AIO 是注册一个读任务后,直到读任务真的完全完成后才会通知应用层。
这个 IO 模型看着很高级但也最复杂,实现时候坑也最多。比如如何去 Cancel 一个读任务。布置读任务时候一开始就需要传递应用层的 buffer,以及确定 buffer 大小。之后 Kernel 会拷贝读取到的数据到这个 buffer。那读取过程中这个应用层 buffer 如果变化了怎么样?比如变小了,被释放了。如果设置读任务时候说读取 512 字节,但实际在拷贝数据过程中,有更多新数据到来了怎么办?正常来说这种情况下 AIO 是不能读更多数据的。不过 IO Multiplexing 可以。比如 select() 返回后,只表示 Socket 有数据可读,比如有 512 字节数据可读,但真执行读取时候如果有更多数据到来也是能读出来的。但 AIO 下可能用户态 buffer 是不可变的,那拷贝数据时候如果有更多数据到来就只能下次再读了。
IO 模型比较

POSIX 对同步 IO 和异步 IO 的定义如下:
- A synchronous IO operation causes the requesting process to be blocked until that IO operation completes.
- An asynchronous IO operation does not cause the requesting process to be blocked.
所以按这个定义,上面除了 AIO 是异步 IO 外,其它全是同步 IO。Non-Blocking 称为 Non-Blocking 但它依然是同步的。同步非阻塞。所以需要区分同步、异步、阻塞、非阻塞的概念。同步不一定非要跟阻塞绑定,异步也不一定非要跟非阻塞绑定。
后续主要介绍 IO Multiplexing 相关内容。
IO 多路复用接口
上面 IO 模型里已经介绍过 IO Multiplexing 含义,这里记录一下实现 IO Multiplexing 的 API。
select
select 使用文档在: select(2) - Linux manual page
select 接口如下:
int select(int nfds, fd_set *readFDs, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
其中 nfds 是 readfds、writefds、exceptfds 中编号最大的那个文件描述符加一。readfds 是监听读操作的文件描述符列表,当被监听的文件描述符有可以不阻塞就读取的数据时 ( 读不出来数据也算,比如 end-of-file),select 会返回并将读就绪的描述符放在 readfds 指向的数组内。writefds 是监听写操作的文件描述符列表,当被监听的文件描述符中可以不阻塞就写数据时(如果一口气写的数据太大实际也会阻塞),select 会返回并将就绪的描述符放在 writefds 指向的数组内。exceptfds 是监听出现异常的文件描述符列表,什么是异常需要看一下文档,与我们通常理解的异常并不太相同。timeout 是 select 最大阻塞时间长度,配置的最小时间精度是毫秒。
select 返回条件:
- 有文件描述符就绪,可读、可写或异常;
- 线程被 interrupt;
- timeout 到了
select 的问题:
- 监听的文件描述符有上限 FD_SETSIZE ,一般是 1024。因为 fd_set 是个 bitmap,它为最多 nfds 个描述符都用一个 bit 去表示是否监听,即使相应位置的描述符不需要监听在 fd_set 里也有它的 bit 存在。 nfds 用于创建这个 bitmap 所以 fd_set 是有限大小的。
- 在用户侧,select 返回后它并不是只返回处于 ready 状态的描述符,而是会返回传入的所有的描述符列表集合,包括 ready 的和非 ready 的描述符,用户侧需要去遍历所有 readfds、writefds、exceptfds 去看哪个描述符是 ready 状态,再做接下来的处理。还要清理这个 ready 状态,做完 IO 操作后再塞给 select 准备执行下一轮 IO 操作。
- 在 Kernel 侧,select 执行后每次都要陷入内核遍历三个描述符集合数组为文件描述符注册监听,即在描述符指向的 Socket 或文件等上面设置处理函数,从而在文件 ready 时能调用处理函数。等有文件描述符 ready 后,在 select 返回退出之前,kernel 还需要再次遍历描述符集合,将设置的这些处理函数拆除再返回。
- 有惊群问题。假设一个文件描述符 123 被多个进程或线程注册在自己的 select 描述符集合内,当这个文件描述符 ready 后会将所有监听它的进程或线程全部唤醒。
- 无法动态添加描述符,比如一个线程已经在执行 select 了,突然想写数据到某个新描述符上,就只能等前一个 select 返回后重新设置 FD Set 重新执行 select。
select 也有个优点,就是跨平台更容易。实现这个接口的 OS 更多。
参考: Select is fundamentally broken
poll
使用文档在: poll(2) - Linux manual page
接口如下:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
nfds 是 fds 数组的长度, struct pollfd 定义如下:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
poll 的返回条件与 select 一样。
看到 fds 还是关注的描述符列表,只是在 poll 里更先进一些,将 events 和 reevents 分开了,所以如果关注的 events 没有发生变化就可以重用 fds,poll 只修改 revents 不会动 events。再有 fds 是个数组,不是 fds_set,没有了上限。
相对于 select 来说,poll 解决了 fds 长度上限问题,解决了监听描述符无法复用问题,但仍然需要在 poll 返回后遍历 fds 去找 ready 的描述符,也需要清理 ready 描述符对应的 revents,Kernel 也同样是每次 poll 调用需要去遍历 fds 注册监听,poll 返回时候拆除监听,也仍然有与 select 一样的惊群问题,也有无法动态修改描述符的问题。
epoll
使用文档在:
- epoll(7) - Linux manual page
- epoll_create(2) - Linux manual page
- epoll_ctl(2) - Linux manual page
- epoll_wait(2) - Linux manual page
接口如下:
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
其中 struct epoll_event 如下:
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
复杂了许多。使用步骤:
- 用 epoll_create 创建 epoll 的描述符;
- 用 epoll_ctl 将一个个需要监听的描述符以及监听的事件类型注册在 epoll 描述符上;
- 执行 epoll_wait 等着被监听的描述符 Ready, epoll_wait 返回后遍历 Ready 的描述符,根据 Ready 的事件类型处理事件;
- 如果某个被监听的描述符不再需要了,需要用 epoll_ctl 将它与 epoll 的描述符解绑;
- 当 epoll 描述符不再需要时需要主动 close,像关闭一个文件一样释放资源。
epoll(7) - Linux manual page 有使用示例。
epoll 优点:
- 监听的描述符没有上限;
- epoll_wait 每次只会返回 Ready 的描述符,不用完整遍历所有被监听的描述符;
- 监听的描述符被注册到 epoll 后会与 epoll 的描述符绑定,维护在内核,不主动通过 epoll_ctl 执行删除不会自动被清理,所以每次执行 epoll_wait 后用户侧不用重新配置监听,Kernel 侧在 epoll_wait 调用前后也不会反复注册和拆除描述符的监听;
- 可以通过 epoll_ctl 动态增减监听的描述符,即使有另一个线程已经在执行 epoll_wait ;
- epoll_ctl 在注册监听的时候还能传递自定义的 event_data ,一般是传描述符,但应用可以根据自己情况传别的;
- 即使没线程等在 epoll_wait 上,Kernel 因为知道所有被监听的描述符,所以在这些描述符 Ready 时候就能做处理,等下次有线程调用 epoll_wait 时候直接返回。这也帮助 epoll 去实现 IO Edge Trigger,即 IO Ready 时候 Kernel 就标记描述符为 Ready 之后在描述符被读空或写空前不再去监听它,后面详述;
- 多个不同的线程能同时调用 epoll_wait 等在同一个 epoll 描述符上,有描述符 Ready 后它们就去执行。
epoll 缺点:
- epoll_ctl 是个系统调用,每次修改监听事件,增加监听描述符时候都是一次系统调用,并且没有批量操作的方法。比如一口气要监听一万个描述符,要把一万个描述符从监听读改到监听写等就会很耗时,很低效;
- 对于服务器上大量连上又断开的连接处理效率低,即 accept() 执行后生成一个新的描述符需要执行 epoll_ctl 去注册新 Socket 的监听,之后 epoll_wait 又是一次系统调用,如果 Socket 立即断开了 epoll_wait 会立即返回,又需要再用 epoll_ctl 把它删掉;
- 依然有惊群问题,需要配合使用方式避免,后面详述。
kqueue
使用文档在: kqueue(2)
接口如下:
int kqueue(void);
int kevent(int kq, const struct kevent *changelist, int nchanges, struct kevent *eventlist, int nevents,
const struct timespec *timeout);
其中 struct kevent 结构如下:
struct kevent {
uintptr_t ident; /* identifier for this event */
short filter; /* filter for event */
u_short flags; /* action flags for kqueue */
u_int fflags; /* filter flag value */
int64_t data; /* filter data value */
void *udata; /* opaque user data identifier */
uint64_t ext[4]; /* extensions */
};
kqueue 跟 epoll 有些类似,使用方法上很相近,不再叙述,在 kqueue(2) 有示例。但 kqueue 总体上要高级很多。首先是看到 kevent 有 changelist 参数用于传递关心的 event,nchanges 用于传递 changelist 的大小。eventlist 用于存放当有事件产生后,将产生的事件放在这里。nevents 用于传递 eventlist 大小。timeout 就是超时时间。
这里 kqueue 高级的地方在于,它监听的不一定非要是 Socket,不一定非要是文件,可以是一系列事件,所以 struct kevent 内参数叫 filter,用于过滤出关心的事件。它可以去监听非文件,比如 Signal,Timer,甚至进程。可以实现比如监听某个进程退出。对于磁盘上的普通文件 kqueue 也支持的更好,比如可以在某个文件数据加载到内存后触发 event,从而可以真正 non-blocking 的读文件。而 epoll 去监听普通磁盘文件时就认为文件一定是 Ready 的,但是实际读取的时候如果文件数据不在内存缓存中的话 read() 还是会阻塞住等待数据从磁盘读出来。
可以说 kqueue 有 epoll 的所有优点,甚至还能通过 changelist 一口气注册多个关心的 event,不需要像 epoll 那样每次调用 epoll_ctl 去配置。当然还有上面提到的,因为接口更抽象,能监听的事情更多。但是它也有 epoll 的惊群问题,也需要在使用时候通过配置参数等方式避免。
对比 epoll 和 kqueue 的性能的话,一般认为 kqueue 性能要好一些,但主要原因只是因为 kqueue 支持一口气注册一组 event,能减少系统调用次数。另外 kqueue 没有 Edge Trigger,但能通过 EV_CLEAR 参数实现 Edge Trigger 语义。
这篇文章介绍了 epoll 和 kqueue 的对比,感觉还可以,可惜原始链接被破坏了: Scalable Event Multiplexing: epoll vs. kqueue ,我找到一份拷贝在这里: Scalable Event Multiplexing: epoll vs. kqueue - 后端 - 掘金
Windows IO Completion Ports (IOCP)
IOCP 是 Windows 下异步 IO 的接口,按说放这里是不合适的,但我之所以把它放这里是因为在不了解 IOCP 的时候容易把它和 Linux 下 select, poll, epoll 混在一起,认为 IOCP 是 Windows 上做 IO Multiplexing 的接口,把 IOCP 和 epoll 之类的放在一起称为是 Windows 上的 epoll,而 IOCP 和 epoll 实际是不同的 IO 模型。在 Java 上,为了跨平台特性, Java 的 NIO 抽象出来叫 Selector 的概念去实现 IO Multiplexing,Java 的使用者可以不管 Java 跑在什么平台上,都用 Selector 去实现 IO 多路复用,而 JVM 会帮你在用平台相关的接口去实现 Selector 功能。我们会知道在 Linux 上它背后实际就是 epoll,但很多人会认为在 windows 上 Selector 背后就是 IOCP,实际不是这样的。在 Windows 上 Selector 背后对应的是 select function (winsock2.h) - Win32 apps | Microsoft Docs ,接口和使用都和 Unix 上的 select 很相似。Java 下用到 IOCP 的是 NIO.2 的 AIO, AsynchronousChannelGroup (Java Platform SE 8 ) ,也就是说 AIO 在 Windows 上才对应着 IOCP。
IOCP 的一个说明在这里: I/O Completion Ports - Win32 apps | Microsoft Docs
还有一篇很好的文章介绍 epoll 和 IOCP 的区别: Practical difference between epoll and Windows IO Completion Ports (IOCP) | UlduzSoft 。
我打算后面专门写一个关于异步 IO 的文章,那个时候再记录更多关于 IOCP 的东西。
io_submit
io_submit 是 Linux 提供的 AIO 接口。主要服务于 AIO 需求,但是一直以来 Linux 的 AIO 问题多多,最主要的是容易出现本来以为是异步的操作实际在执行时候是同步执行的,即经常不满足 AIO 要求。再有是 Linux AIO 开始主要为磁盘类操作而设计,直到 Linux 4.18 之后, io_submit 才支持了 Polling 操作: A new kernel polling interface LWN.net 。对于 AIO 的说明和 Windows IOCP 一样,我打算专门写一个关于 AIO 的文章,这里只介绍一下用 io_submit 替换 epoll 的方法。
AIO 简单讲就是有接口去让我们能提供要干什么事情,干完之后结果该放在哪里。还会有个接口用于等待异步任务完成,异步任务完成后会告诉我们有哪些异步任务完成了,结果分别是什么。告诉 AIO 该做什么事情通过 Op Code 完成, io_submit 新提供了 IOCB_CMD_POLL 这么个 Code 去实现 Socket Polling,使用起来大致如下:
// sd 是被操作的 Socket 的 FD
// aio_buf 传递的是 poll 事件类型,比如 POLLIN POLLOUT 等参见 http://man7.org/linux/man-pages/man2/poll.2.html
struct iocb cb = {.aio_fildes = sd,
.aio_lio_opcode = IOCB_CMD_POLL,
.aio_buf = POLLIN};
struct iocb *list_of_iocb[1] = {&cb};
// 注册事件,ctx 是 io_setup() 时返回的一个 context
r = io_submit(ctx, 1, list_of_iocb);
// io_getevents() 返回后, events 内是处于 Ready 状态的 FD
r = io_getevents(ctx, 1, 1, events, NULL);
IOCB_CMD_POLL 是 one-shot 且是 Level Trigger 的。它相对 Epoll 的优势主要是在于一口气能传递多个监听的 FD,而不需要通过 epoll_ctl 挨个添加。可以在部分场景下替换 Epoll。
CloudFlare 有个文章介绍的这种使用方法,在: io_submit: The epoll alternative you've never heard about
更多 epoll
前面大致介绍了 epoll 的使用方法以及它和 select、poll 对比的优缺点,本节再多介绍一些 epoll 相关的细节。
什么是 Eage-Trigger,什么是 Level-Trigger?
epoll 有两种触发模式,一种叫 Eage Trigger 简称 ET,一种叫 Level Trigger 简称 LT。每一个使用 epoll_ctl 注册在 epoll 描述符上的被监听的描述符都能单独配置自己的触发模式。
对于这两种触发模式的区别从使用的角度上来说,ET 模式下当一个 FD (文件描述符) Ready 后,需要以 Non-Blocking 方式一直操作这个 FD 直到操作返回 EAGAIN 错误为止,期间 Ready 这个事件只会触发 epoll_wait 一次返回。而如果是 LT 模式,如果 FD 上的事件一直处在 Ready 状态没处理完,则每次调用 epoll_wait 都会立即返回。
这两种触发模式在 epoll(7) - Linux manual page 文档中举了一个挺好的例子,在这里大致记录一下。假设场景如下:
epoll_wait
epoll_wait
如果这个 Socket 注册在 epoll FD 上时带着 EPOLLET flag,即 ET 模式下,即使 Socket 还有 1 KB 数据没读,第五步 epoll_wait 执行时也不会立即返回,会一直阻塞下去直到再有新数据到达这个 Socket。因为这个 Socket 上的数据一直没有读完,其 Ready 状态在上一次触发 epoll_wait 返回后一直没被清理。需要等这个 Socket 上所有可读的数据全部被读干净, read() 操作返回 EAGAIN 后,再次执行 epoll_wait 如果再有新数据到达 Socket, epoll_wait 才会立即因为 Socket 读 Ready 而返回。
而如果使用的是 LT 模式,Socket 还剩 1 KB 数据没读,第五步执行 epoll_wait 后它也会带着这个 Socket 的 FD 立即返回,event 列表内会记录这个 Socket 读 Ready。
这里是以读数据为例,但实际上比如写数据,执行 accept() 等都适用。此外,两者还在唤醒线程上有区别。比如一个进程通过 fork() 方式继承了父进程的 epoll FD,上面注册了一些监听的 FD。当某个 FD Ready 时,如果是 ET 模式下则只会唤醒父子进程中的一个,如果是 LT 模式,则会将父子进程都唤醒。
需要补充说明的是,ET 模式下如果数据是分好几个部分到来的,则即使是处于读 Ready 状态且 Socket 还未读空情况下,每个新到达的数据部分都会触发一次 epoll_wait 返回,除非 Socket 的 FD 在注册到 epoll FD 的时候设置 EPOLLONESHOT flag,这样 Socket 只要触发过一次 epoll_wait 返回后不管再有多少数据到来,Socket 有没有读空,都不会再触发 epoll_wait 返回,必须主动带着 EPOLL_CTL_MOD 再执行一次 epoll_ctl 把 Socket 的 FD 重新设置到 epoll 的 FD 上,这个 Socket 才会触发下一次读 Ready 让 epoll_wait 返回。
Edge Trigger 有什么好处呢?我理解一个是多线程执行 epoll_wait 时能不需要把所有线程都唤醒,再有单线程情况下也能减少 epoll_wait 被唤醒次数,可以实现尽量均匀的为所有 Socket 执行 IO 操作。比如有 1000 个 Socket 被监听,其中有一个 Socket 发来数据量特别大,其它 Socket 发来的数据都很少,如果是 Level Trigger,处理线程必须把数据量特别大的这个 Socket 上数据全处理干净, epoll_wait 才能阻塞住,不然每次执行都会立即返回。但 Edge Trigger 下,我可以只从数据量大的 Socket 读一点数据并记录下这个 Socket 还有数据没读完,之后带着 timeout 去执行 epoll_wait ,返回后可以先处理别的 Socket 上的数据,再回头处理数据量大的那个 Socket 的数据,从而公平的执行所有 Socket 上的 IO 操作。
epoll 怎么实现定时器
这个倒不是 epoll 专属,select,poll 等也能用。这些 IO Multiplexing 接口都提供了 timeout 参数,用以限制等待 FD Ready 的最大时长。但是这个 timeout 的精度都是 1ms,如果设置更小的 timeout 就需要 timerfd 的帮助。它也是一个 FD 只是可以在上面绑定一个高精度的超时时间,时间到了以后 Kernel 会通过向这个 timer fd 写数据的方式让它自动进入读 Ready 状态。将这个 timer FD 放入 IO Multiplexing 接口监听,从而在时间到了以后就能唤醒阻塞在 select, poll, epoll 上的线程,实现精度更高的 timeout。
另外需要注意的是,timer FD 到时后,Kernel 会写数据到这个 FD 上,所以对于 LT 触发方式的 epoll 不光是要监控这个 FD,监控完了还需要实际去读里面的数据。不然下一次 epoll_wait 会立即返回,timer FD 失去定时功能。如果是 ET 模式,不去读 Socket 的话,下一次 epoll_wait 不会因为 timer FD 返回,因为之前的数据没读干净。下一次 timer FD 到期后新写入 timer FD 的数据才会让 epoll_wait 返回,所以在 ET 模式下是不用读 timer FD 的。另外 timer FD 配合 epoll 比配合 select poll 它们使用起来更方便一些,因为 epoll 能配置为 ET 模式,不用每次 timeout 后还得去读 timer fd。
timer FD 变成读 Ready 后,读取这个 FD 的数据会得到从上一次读这个 FD 到现在一共 timeout 了多少次。能计算周期数目。
事实上这种唤醒阻塞在 epoll_wait 线程的方式比较常见,也是一种最佳实践。比如可以自己创建一个 FD,以 ET 方式注册在 epoll FD 上,等要唤醒阻塞在 epoll_wait 线程时,写一些数据到这个自建的 FD 上就可以了。为啥不能用 Interrupt 呢?因为 Interrupt 不保险,不优雅。中断时不确认线程到底是不是正阻塞在 epoll_wait 上,万一阻塞在别的地方这么去中断线程可能导致问题。比如万一在写文件,这么中断一下文件就写错了。
Epoll 与 File Descriptor
操作系统内 File Descriptor 和 File Description 以及和 inode 的关系如下图所示,下图截取自:Oreilly Safari 版 The Linux Programming Interface 图 5-2。

看到每个进程有自己的 File Descriptor,也即前面一直说的文件描述符,或简称 FD。每个 File Descriptor 指向系统级的 File Description。每个 File Description 又指向系统维护的 I-node。进程 A 内 FD 1 和 FD 20 指向同一个 File Description,一般通过 dup() , dup2() 等实现。进程 B 的 FD 2 和进程 A 的 FD 2 指向同一个 File Description,一般通过 fork() 实现。进程 A 的 FD 0 和进程 B 的 FD 3 指向不同的 File Description 但指向相同的 I-node,一般通过 open() 同一个文件实现。
当 epoll_create() 执行后,Kernel 负责创建一个 In-memory 的 I-node 用于维护 epoll 的 Interest List,还会用一个 File Description 指向这个 In-Memory Inode。再为执行 epoll_create() 的进程创建 File Descriptor 指向 epoll 的 File Description。
在执行 epoll_ctl 后,被监听的 FD 及其指向的 File Description 一起被放入 epoll 的 Interest List。可以将 (FD, File Description) 看做是主键,后续相同 FD 再次执行 epoll_ctl 会报错返回 EEXIST 说已经监听过了。但如果执行一次 dup() 如下图,在 FD 1 执行 dup() 后得到 FD 2,它俩都会指向之前 FD 1 的 File Description 1,则 dup 出来的 FD 2 还能再次执行 epoll_ctl 被监听。这么做的原因可能是为了让两个不同的 FD 都注册在 epoll_ctl 里去监听不同的 events。

但这么一来问题就来了。如果一个注册在 Epoll 监听列表的 File Description 只有一个 File Descriptor 指向,那当这个唯一的 File Descriptor 关闭的时候,会自动从 epoll 里注销出去。但如果是上图的样子,对 FD 1 执行 close() 后,因为 File Description 1 还有个 FD 2 在指向,所以注册进入 epoll 的 (FD 1, File Description 1) tuple 不会被清理,会一直留在 epoll 内,会出现:
- 再有 event 来了以后还会触发 epoll_wait() 返回;
- 带着 EPOLL_CTL_DEL 执行 epoll_ctl 去清理 FD 1 会失败,因为 epoll_ctl 要求被操作的 FD 必须是个有效的 FD,而 FD 1 已经被关闭了
- 关闭 FD 2 也没用,因为注册在 epoll 的是 FD 1;
- 带着 EPOLL_CTL_DEL 对 FD 2 去执行 epoll_ctl 也不行,因为 FD 2 并没有被 epoll 监听过
- 将 FD 2 加入 epoll 再从 epoll 删除也没用,因为 epoll 内还保留有 (FD 1, File Description 1) 的记录;
也就是说:
Thus it is possible to close an fd, and afterwards forever receive events for it, and you can't do anything about that.
出现上述问题的代码大致这样:
rfd, wfd = pipe()
write(wfd, "a") # Make the "rfd" readable
epfd = epoll_create()
epoll_ctl(epfd, EPOLL_CTL_ADD, rfd, (EPOLLIN, rfd))
rfd2 = dup(rfd)
close(rfd)
r = epoll_wait(epfd, -1ms) # What will happen?
上面的 epoll_wait 每次调用都会立即返回。因为是 Level Trigger 的,且有数据,且读不出来。这种时候解决办法只能是重建 epoll 实例。所以使用 Epoll 的时候一定要先调用 epoll_ctl(EPOLL_CTL_DEL) 再调用 FD 的 close() 。
上述内容参考自: Epoll is fundamentally broken 2/2 — Idea of the day 以及 The Linux Programming Interface,63.4.4 节。
还有一个有意思的是 epoll_create1() 它创建 epoll 实例的时候可以传 EPOLL_CLOEXEC 参数,从而在 fork() 时,子进程并不会继承 epoll 实例的 FD,而 epoll 的 FD 只在父进程可用。 epoll_create1(2): open epoll file descriptor - Linux man page
怎么解决惊群问题?
惊群问题词条: Thundering herd problem - Wikipedia
上面提到的 IO Multiplexing API 都有惊群问题,后续只以 epoll 为例来叙述。惊群问题起源在哪里呢,在使用 epoll 时候如果只有一个线程去做 epoll_wait 是没惊群问题的,但如果想 scale,想引入多线程去做 epoll_wait 去处理 IO 事件,就可能遇到惊群问题了,这就是惊群问题的起源。epoll 实现中一点一点引入新参数去解决惊群问题也能看出来 epoll 开始设计时是只为一个线程处理 IO 事件设计的,后来为了 scale 引入多线程才开始发现有各种问题,于是为了解决问题又引入一些新参数。
多线程去处理 IO 事件可能有两种方式:
- 一个打开的文件 (Socket) 产生一个 FD 注册在 epoll FD 后,父进程通过 fork() 和子进程共享所有打开的 FD,父子进程一起处理打开文件的 IO 事件。当文件有事件时可能会将父子进程都唤醒,于是出现惊群;
- 指向同一个文件 (Socket) 的 FD 被注册到多个不同的 epoll 实例上,且每个 epoll 实例由不同线程负责调用 epoll_wait ,这些线程一起处理文件的 IO 事件。此时文件有数据后可能会在两个 epoll 实例上将等在 epoll_wait 的两个线程都唤醒,于是出现惊群。
为了解决上面的惊群问题,一个处理办法就是使用 Edge Trigger。Edge Trigger 保证在第一种场景下只会唤醒一个进程或线程去处理事件,不过对第二个问题场景无能为力。另一个处理办法就是带着 EPOLLEXCLUSIVE 该参数在 Linux 4.15 引入,在上述两个场景下都能保证同一个文件产生 IO 事件后只唤醒一个线程来处理。
看上去是只要使用 Edge Trigger 并且带着 EPOLLEXCLUSIVE 惊群问题就解决了,但实际问题依然特别多。
多线程通过 Epoll 处理 accept()
先以 accept() 操作为例,使用 Edge Trigger 且带着 EPOLLEXCLUSIVE 参数,可能有如下运行流程导致有处于 epoll_wait() 的线程被无效唤醒:
Kernel: 收到第一个连接,有两个 Thread 在等待处理 accept,因为是 ET 模式,假设 Thread A 被唤醒
Thread A: 从 epoll_wait() 返回
Thread A: 执行 accept() 操作,正常结束
Kernel: accept 队列空了,将 Socket 从 "readable" 切换到 "non-readable",于是下一次再有连接到来,Kernel 会再次触发 Event
Kernel: 又收到一个新连接,这是第二个连接
Kernel: 目前只有一个线程等在 `epoll_wait()` 上,于是 Kernel 唤醒 Thread B
Thread A: 继续执行 accept() 因为它并不知道 Kernel 收到多少连接,需要连续执行 accept() 直到返回 EAGAIN 为止。所以它 accept 了第二个连接
Thread B: 执行 accept() 但是收到 EAGAIN,也即 Thread B 被无效唤醒
Thread A: 再次执行 accept() 得到 EAGAIN,Thread A 回去等在 `epoll_wait` 上
除了无效唤醒外还会遇到饥饿:
Kernel: 收到两个连接,当前有两个线程在处理 accept,因为是 ET 模式,假设 Thread A 被唤醒
Thread A: 从 epoll_wait() 返回
Thread A: 执行 accept() 操作,正常结束
Kernel: 收到第三个连接请求,Socket 是 "readable" 状态,继续保持该状态,不触发 Event
Thread A: 继续执行 accept() 直到遇到 EGAIN,于是又正常执行 accept,拿到一个新 Socket
Kernel: 又收到一个新连接,第四个连接,继续不触发 Event
Thread A: 继续执行 accept() 直到遇到 EGAIN,于是又正常执行 accept,拿到一个新 Socket
循环过程可以这么永无止境的继续下去,Thread B 即使存在也不能被唤醒。不过这个问题也可以看做是 Accept 操作压力不够大,一个线程就扛住请求量了,如果 connect 的连接再多,Thread B 还是会参与 Accept 操作。另外我对这个饥饿产生的场景也比较疑惑,按说 Edge Trigger 下新来数据(这里是连接)也会触发 epoll_wait 返回来着,但这里却说因为 Accept 队列非空,新连接来了不触发 Event。不过这个也不算很重要。
解决办法是使用 Level Trigger,且带着 EPOLLEXCLUSIVE 参数。可以推演一下上面两个场景会发现是能解决问题的。如果是老的 Linux 没有 EPOLLEXCLUSIVE 则只能用 Edge Trigger 配合 EPOLLONESHOT 来解决了。就是说一个 Socket 只会产生一个 accept 事件,之后即使再有连接过来也不会再触发 Event。但每次处理完 Accept 事件后需要重新用 epll_ctl 去重置 Socket 对应的 FD。
如果能不用 epoll 的话还可以引入 SO_REUSEPORT 让多个进程监听同一个端口,通过 OS 来完成 Accept 事件的负载均衡。缺点是当一个进程关闭 Socket 时候,在 Socket 上 Accept 队列排队的请求会全部被丢弃。一般来说 Nginx 是用 SO_REUSEPORT 来做 Accept 的负载均衡的。
多线程通过 epoll 处理 read()
多线程通过 epoll 处理 read() 操作比处理 accept() 更复杂。比如在 Level Trigger 下即使配合 EPOLLEXCLUSIVE 也有问题:
Kernel: 收到 2047 个字节的数据
Kernel: 假设有两个线程等在 epoll 上,因为有 EPOLLEXCLUSIVE 所以只唤醒 Thread A
Thread A: 从 epoll_wait() 返回
Kernel: 又收到 2 字节数据
Kernel: 只有一个线程等在 epoll 上,将其唤醒,即 Thread B 被唤醒
Thread A: 执行 read(2048) 读出来 2048 字节数据
Thread B: 执行 read(2048) 读出来最后 1 字节数据
同一个 Socket 的数据分布在两个不同线程,即有了 Race Condition,得让两个线程同步去处理数据,保证数据不乱序。
Edge Trigger 也有问题:
Kernel: 收到 2048 字节数据
Kernel: 因为是 Edge Trigger 只唤醒 Thread A
Thread A: 从 epoll_wait() 返回
Thread A: 执行 read(2048) 读出全部的 2048 字节数据
Kernel: Socket buffer 空了,所以 Kernel 重新配置 Socket 的 File Descriptor,下次再有数据时再次产生事件
Kernel: 收到 1 字节数据
Kernel: 只有一个线程等在 epoll 上,将其唤醒,即 Thread B 被唤醒
Thread B: 从 epoll_wait() 返回
Thread B: 执行 read(2048) 并读出 1 字节数据
Thread A: 因为是 Edge Trigger 需要再次执行 read(2048), 返回 EAGAIN 后不再重试
此时也是同一个 Socket 的数据被放在了两个不同的线程上,也有 Race Condition。
这里 read() 操作不管用 LT 还是 ET 模式都有问题主要原因是同一个 Socket 的数据可能会被两个不同的线程同时处理,所以怎么搞都有问题。而且上面提到的 Race Condition 几乎无法被处理,不是加个锁就完了。因为两个线程拿了同一个 Socket 上的两段数据,两个线程根本无法去判断这两段数据谁先谁后,该怎么拼接。目前唯一解决办法就是带上 EPOLLONESHOT ,Socket 有数据后只唤醒一个线程,之后这个 Socket 再有数据也不会唤醒别的线程,直到数据被全部处理完,重新通过 epoll_ctl 加入 epoll 实例后这个 Socket 才可能在再次有数据时被分配给别的 Thread。
总之 epoll 想使用正确不容易,特别是想给 epoll 操作引入多线程的时候更加复杂。得清晰的了解 ET,LT 模式,了解 EPOLLONESHOT 和 EPOLLEXCLUSIVE 参数。
本节主要内容都来自: Epoll is fundamentally broken 1/2 — Idea of the day
Java 的 Selector
Java 的 NIO 提供了一个叫 Selector 的类,用于跨平台的实现 Socket Polling,也即 IO 多路复用。比如在 BSD 系统上它背后对应的就是 Kqueue,在 Windows 上对应的是 Select,在 Linux 上对应的是 Level Trigger 的 epoll。Linux 上为什么非要是 Level Trigger 呢?主要是为了跨平台统一,在 Windows 上背后是 Select,它是 Level Trigger 的,那为了同一套代码多处运行,在 Linux 上也只能是 Level Trigger 的,不然使用方式就不同了。
这也是为什么 Netty 自己又为 Linux 单独实现了一套 EpollEventLoop 而不只是提供 NioEventLoop 就完了。因为 Netty 想支持 Edge Trigger,并且还有很多 epoll 专有参数想支持。参看这里 Netty 的维护者的回答: nio - Why native epoll support is introduced in Netty? - Stack Overflow
简单举例一下 Selector 的使用:
- 先通过 Selector.open() 创建出来 Selector;
- 创建出来 SelectableChannel (可以理解为 Socket),配置 Channel 为 Non-Blocking
- 通过 Channel 下的 register() 接口注册 Channel 到 Selector,注册时可以带上关心的事件比如 OP READ,OP ACCEPT, OP_WRITE 等;
- 调用 Selector 上的 select() 等待有 Channel 上有 Event 产生
- select() 返回后说明有 Channel 有 Event 产生,通过 Selector 获取 SelectionKey 即哪些 Channel 有什么事件产生了;
- 遍历所有获取的 SelectionKey 检查产生了什么事件,是 OP READ 还是 OP WRITE 等,之后处理 Channel 上的事件;
- 从 select() 返回的 Iterator 中移除处理完的 SelectionKey
可以看到整个使用过程和使用 select, poll, epoll 的过程是能对应起来的。再补充一下,Selector 是通过 SPI (Java Service Provider Interface)来实现不同平台使用不同 Selector 实现的。
实际看看 Netty 如何使用 epoll
Netty 对 Linux 的 epoll 接口做了一层封装,封装为 JNI 接口供上层 JVM 来调用。以下内容以 Netty 4.1.48,且使用默认的 Edge Trigger 模式为例。
如何写数据
按照之前说的使用方式,写数据前需要先通过 epoll_ctl 修改 Interest List 为目标 Socket 的 FD 增加 EPOLLOUT 事件监听。等 epoll_wait 返回后表示 Socket 可写,我们开始使劲写数据,直到 write() 返回 EAGAIN 为止。之后我们要再次使用 epoll_ctl 去掉 Socket 的 EPOLLOUT 事件监听,不然下次我们可能并没有数据要写,可 epoll_wait 还会被错误唤醒一次。可以数一下这种使用方式至少有四次系统调用开销,假如每次写一条数据都这么多系统调用的话性能是上不去的。
那 Netty 是怎么做的呢,最核心的地方在这个 doWrite() 。可以看到最关键的是每次有数据要写 Socket 时并不是立即去注册监听 EPOLLOUT 写数据,而是用 Busy Loop 的方式直接尝试调用 write() 去写 Socket,写失败了就重试,能写多少写多少。如果 Busy Loop 时数据写完了,就直接返回。这种情况下是最优的,完全省去了 epoll_ctl 和 epoll_wait 的调用。
如果 Busy Loop 多次后没写完,则分两种情况。一种是下游 Socket 依然可写,一种是下游 Socket 已经不能写了 write() 返回了 Error。对于第一种情况,用于控制 Loop 次数的 writeSpinCount 能到 0,因为下游依然可写我们退出 Busy Loop 只是为了不为这一个 Socket 卡住 EventLoop 线程太久,所以此时依然不用设置 EPOLLOUT 监听,直接返回即可,这种情况也是最优的。补充说明一下,Netty 里一个 EventLoop 对应一个线程,每个线程会处理一批 Socket 的 IO 操作,还会处理 submit() 进来的 Task,所以线程不能为某个 Socket 处理 IO 操作处理太久,不然会影响到其它 Socket 的运行。比如我管理了 10000 个连接,其中有一个连接数据量超级大,如果线程都忙着处理这个数据超级大的连接上的数据,其它连接的 IO 操作就有延迟了。这也是为什么即使 Socket 依然可写,Netty 依然在写出一定次数消息后就退出 Busy Loop 的原因。
只有 Busy Loop 写数据时候发现 Socket 写不下去了,这种时候才会配置 EPOLLOUT 监听,才会使用 epoll_ctl ,下一次等 epoll_wait 返回后会清理 EPOLLOUT 也有一次 epoll_ctl 的开销。
通过以上方法可以看到 Netty 已经尽可能减少 epoll_ctl 系统调用的执行了,从而提高写消息性能。上面的 doWrite() 下还有很多可以看的东西,比如写数据时候会区分是写一条消息,还是能进行批量写,批量写的时候为了调用 JNI 更优,还要把消息拷贝到一个单独的数组等。
如何读数据
本来读操作相对写操作来说可能更容易一些,每次 Accept 一个 Socket 后就可以把 Socket 对应的 FD 注册到 epoll 上监听 EPOLLIN 事件,每当有事件产生就使劲读 Socket 直到遇到 EAGAIN 。也就是说整个 Socket 生命周期里都可以不用 epoll_ctl 去修改监听的事件类型。但是对 Netty 来说它支持一个叫做 Auto Read 的配置,默认是 Auto Read 的,但可以关闭。关闭后必须上层业务主动调用 Channel 上的 read() 才能真的读数据进来。这就违反了 Edge Trigger 的约定。所以对于 Netty 在读操作上有这么几个看点:
- 每次 Accept 一个 Socket 后 Netty 是如何为每个 Socket 设置 EPOLLIN 监听的;
- 每次有读事件后,Edge Trigger 模式下 Netty 是如何读取数据的,能满足一直读取 Socket 直到 read() 返回 EAGAIN
- Edge Trigger 下 Netty 怎么保证不同 Socket 之间是公平的,即不能出现比如一个 Socket 上一直有数据要读而 EventLoop 就一直在读这一个 Socket 让其它 Socket 饥饿;
- Netty 的 Auto Read 在 Edge Trigger 模式下是如何工作的
Accept Socket 后如何配置 EPOLLIN
- Epoll 的 Server Channel 遇到 EPOLLIN 事件时就是去执行 Accept 操作,创建新 Socket 也即 Channel 并 触发 Pipeline 的 Read
- ServerBootstrap 在 bind 一个地址时会给 Server Channel 绑定一个 ServerBootstrapAcceptor handler ,每次 Server Channel 有 Read 事件时会用这个 Handler 做处理;
- 在 ServerBootstrapAcceptor 内会 将新来的 Channel 和一个 EventLoop 绑定
- 新 Channel 和 EventLoop 绑定后会 触发新 Channel 的 Active 事件
- 新 Channel Active 后如果开启了 Auto Read,会 立即执行一次 channel.read() 操作 。默认是 Auto Read 的,如果主动关掉 Auto Read 则每次 Channel Active 后需要业务主动去调用一次 read()
- Channel 在执行 read() 时会走到 doBeginRead()
- 对 epoll 来说在 doBeginRead() 内就会 为 Channel 注册 EPOLLIN 事件监听
Channel 在有 EPOLLIN 事件后如何处理
- Channel 在有 EPOLLIN 事件后,会走到 一个 Loop 内从 Channel 读取数据 ;
- 看到 Loop 内的 allocHandle 它就是 Netty 控制读数据操作的关键。每次执行 read() 后会将返回结果更新在 allocHandle 内,比如读了多少字节数据?成功执行了几次读取?当前 Channel 是不是 Edge Trigger 等。
- Epoll Stream Channel 的 allocHandle 是 DefaultMaxMessagesRecvByteBufAllocator 这个类,每次以 Loop 方式从 Channel 读取数据后都会执行 continueReading 看是否还要继续读。从 continueReading 实现能看到 循环结束条件 是否关闭了 Auto Read,是否读了太多消息,是否是 Edge Trigger 等。默认 最大读取消息数量是 16 ,也就是说每个 Channel 如果能连续读取出来数据的话,最多读 16 次就不读了,会切换到别的 Channel 上去读;
- 每次循环读取完数据,会走到 epollInFinally() ,在这里判断是否 Channel 还有数据没读完,是的话需要 Schedule 一个 Task 过一会继续来读这个 Channel 上的数据。因为 Netty 上会分配 IO 操作和 Task 操作比例,一般是一半一半,等 IO 执行完后才会去执行 Task,且 Task 执行时间是有限的,所以不会出现比如一个 Channel 数据特别多导致 EventLoop 即使分配了 Task 实际还是一直在读取同一个 Channel 的数据没有时间处理别的 Channel 的 IO 操作;
- 如果数据读完了,且 Auto Read 为关闭状态,则会在 epollInFinally() 内去掉 EPOLLIN 监听,在下一次用户调用 read() 时在 doBeginRead() 内再次 为 Channel 注册 EPOLLIN 事件监听 。
这么一来读消息过程就理清了,前面提到的问题也有答案了。简单说就是 Netty 每次读数据会限制每个 Channel 上读取的消息数量,Edge Trigger 模式下会连续执行 read() 直到读取操作次数达到上限,如果还有数据剩余则通过 Schedule 一个 Task 过一会再回来读 Socket;Level Trigger 则一般只读一次。如果 Auto Read 关闭了则会在每次处理完 EPOLLIN 事件后会取消 Channel 的 EPOLLIN 事件监听,等下一次用户主动调用 Channel 的 read() 时再重新注册 EPOLLIN 。
参考资料
- 本文是我在准备 LeanCloud 内部的一个分享时写的,感兴趣的读者可以查看视频( 上 、 下 )。
- 介绍 select,poll,epoll 区别,挺全的: select / poll / epoll: practical difference for system architects | UlduzSoft
- 这个介绍 epoll 介绍的挺全: The method to epoll’s madness - Cindy Sridharan - Medium
- 可以随意看看: Async IO on Linux: select, poll, and epoll - Julia Evans
- 这个超级棒,帮你从上到下理清 Linux 网络层,不过跟本文好像没什么关系,但是是我写本文的时候搜到的,也列在这里吧: GitHub - leandromoreira/linux-network-performance-parameters: Learn where some of the network sysctl variables fit into the Linux/Kernel network flow
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






