谁见过智能小冰(是点点滴滴的积累)
「爱情就像脂肪,是点点滴滴的积累」这是 18 岁少女微软小冰造出来的句子,咋一听来,倒是很能引起万千热恋中的少男少女的同理心:「这可不就是恋爱后的幸福肥吗?」
唱歌、写诗、作画...... 作为一款主业为「陪聊」的对话机器人,微软小冰近几年来不断解锁其他副业的进阶之路,受到了不少关注。然而为什么要让微软小冰唱歌、写诗、作画以及现在为什么还让她开启了「造 比喻句」技能?微软小冰这些技能的背后又有哪些技术支撑?伴随着前不久第七代微软小冰的诞生,各位心中的这些疑问想必又被放大了不止一倍。
这不,微软团队就专门开了场研讨会来为大家做讲解了,并且还派出了微软小冰首席科学家宋睿华、微软小冰首席 NLP 科学家武威、微软小冰首席语音科学家栾剑三员大将坐镇,不仅介绍了微软小冰 2019 年的最新研究进展,还分别从对话、人工智能创造以及跨模态理解三大技术板块介绍了微软小冰背后的技术原理。

从左至右依次为:武威、栾剑、宋睿华
在走进小冰的硬核技术解析前,我们来看看小冰从 2014 年诞生以来到如今更新到第七代,都实现了哪些成果?
一、更新到第七代,小冰实现了什么?
微软小冰首席科学家宋睿华首先介绍了小冰自 2014 年诞生以来的整体研究概况。

一开始,她就强调了小冰从 2014 年诞生以来到如今更新到第七代所承载的使命,那便是:改变连接人类和世界的方式。
「比如说互联网出现之时,人们再也不需要走到世界的另一端去获取知识和图片等信息,而是在家就能非常方便地看到并获得远方的信息,这是改变了连接人类和世界的方式的一项技术;而当下人人携带的手机则再一次改变了连接人类和世界的方式,甚至有人调侃说新闻流的软件比你自己更了解自己的喜好。
而我们预测,未来 AI 也将成为改变人类社会的一项技术。如果让 AI 作为连接人类与世界的中间载体,就可以让人类通过更自然的 、多感官的交互与世界建立联系。」
进一步,宋睿华指出,除了构建知识图谱和提供服务以帮助人类与世界更加自然地「打交道」外,还希望能够让 AI 创造内容,小冰在两年前发布了人类历史上第一本人工智能创作的诗集,在今年举办了人类史上的第一个 AI 画展,便都是人工智能创造的一部分。
而要检验小冰是否真地能够成为改变连接人类和世界的方式、与人类自然相处的技术,就必须要对其进行落地,据悉,目前小冰已经搭载了 4.5 亿台第三方智能设备,而微软内部为衡量 EQ 的高低所「发明」的 CPS(人工智能和单个用户的平均对话轮次)指标上,目前小冰已达到 23 轮。
对小冰进行简单的介绍后,宋睿华落脚到小冰背后的四个技术研发重点:对应核心对话的自然语言处理、对应听觉和发声的语音学研究、对应视觉和表情的计算机视觉和图形学以及多对应内容创造的多模态生成。
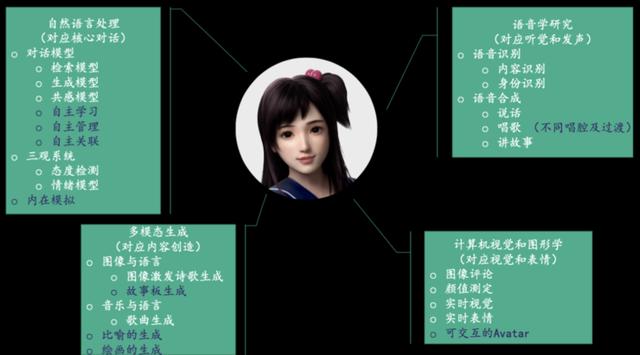
基于这几项技术研发重点,小冰的研究团队在过去几年中也取得了一系列学术成果,包括 48 篇在 AAAI、IJCAI、ACL、KDD 等国际学术顶会上发表的论文、72 项在全双工、多模态等领域极具领先性的专利。而在今年,团队也在在 ACL、IJCAI 等国际顶会上发表了 10 篇论文,与此同时,「Love is as Complex as Math」这篇论文还在 CLSW 2019 上获得了优秀论文奖。
接下来,她与微软小冰首席 NLP 科学家武威、微软小冰首席语音科学家栾剑分别从对话、在人工智能创造和跨模态三个方面介绍了微软小冰背后的技术原理。
二、兼具学习 自我管理 知识联结能力,才能朝向自我完备
「朝向自我完备的对话机器人」是微软小冰首席 NLP 科学家武威这次分享的主题,而之所以选择采用「自我完备(Self-Complete)」一词,他表示,是经过深思熟虑后认为该词能够很好地概括小冰在过去几年中的研究成果。

他认为,一个能够自我完备的对话机器人应该拥有以下几项能力:
-
第一,学习能力。学习是人类发展进化并走向成熟的一个基本能力,对于对话机器人而言亦然如此。而对话机器人的学习能力有两个层次,一是能够从人类的对话中学习怎样去说话;二是当对话机器人发展得越来越成熟之后, 每个机器人可能都在各自专注的领域有很丰富的知识那是否有可能让这些机器人之间互相学习,从而实现信息共享和能力互补呢?
-
第二,自我管理能力。从初级层次来看,对话机器人能够管理好单轮对话的表达,从更高级的层次来看,它在管理好单轮表达后,还要能够把控好整个对话流程。
-
第三,知识联结能力,即对话机器人能够联结散落在世界上的各项多模态知识。
而对于对话机器人的整体发展而言,这三项能力贯穿起来其实是构成了一条纵向,此外,还有一条横向,即核心对话引擎的进化,以小冰为例,一开始小冰使用检索模型通过重用已有的人类对话来实现人机交互;后来采用生成模型以自己合成回复;再到后来则使用共感模型去自主地把握整个的对话流程。
其中,对于这三项朝向自我完备的能力,武威进行了更加详尽的解说:
1、学习能力
首先从检索模型上来看,下图展示了检索模型在学习上这 4 年来的发展情况,每一个方框都代表一个模型,而红色的方框则代表微软小冰团队的工作:

「基本上这 4 年来,模型从最简单的 LSTM 模型发展到了最近的预训练模型,模型的质量得到了非常大的飞跃。而指标上的飞跃实际上是一个表面现象,背后代表了这个模型从单轮到多轮、从浅层次的表示和匹配到深层次、宽度的表示和匹配的一个发展进程。」
而对于这几年来发表的相关主题的论文,武威认为背后的思想可归结为:将用户的输入和机器人的回复候选都表示为向量,再通过计算向量的相似度来度量回复候选是否是合适的回复。
由于很多研究者认为深度学习的本质就是表示学习,因而大家的研究思路基本上都为:研究怎样表示用户输入和回复候选。而在深度学习、神经网络时代,表示的方法非常之多,最简单的方法如词向量甲醛平均,之后出现的方法如卷积神经网、循环神经网以及基于句子的表示等等。
用户输入和回复候选表示以外,检索模型也可以尝试在匹配上做得更细,例如微软小冰团队首先让用户输入和回复侯选在每一个词上都进行交互,然后得到一个充分交互的矩阵,接着把交互的信息从这个矩阵中通过神经网络抽取出来,最后得出匹配程度。
而随着对话机器人从单轮对话发展到多轮对话,表示就从表示一句话变称表示多句话,这就需要进行一个额外的工作,即表示上下文中的多句话后,还要将多句话的表示糅合成上下文的表示再进行匹配。在匹配上,机器人也能够结合上下为做细腻度的交互,例如可以将上下文中每一句输入和回复候选进行交互,再将交互信息通过一个神经网络整合起来成为最终的上下文和回复候选的匹配程度。
以微软小冰团队今年在 WSDM 和 ACL 上的工作为例:

深度学习发展至今,一个句子或一个词会有多种表示,然而如何在一个深度匹配网中融合这些表示呢?一般既可以在匹配的开始就融合这些表示,也可以在匹配的中间和最后融合表示。这项 WSDM 工作中,其最重要的成果就是,他们发现越晚融合这些表示,效果就越好,并且在最后一步融合时,取得了在标准数据上最好的结果。而这个模型现在基本上成为了各种做检索模型必备的一个基线模型。

在 ACL 这项工作中,微软小冰团队的考量点是能否将模型做宽以及做深。当时的想法是已有的检索模型都对上下文和回复候选进行了一次交互进而得到其匹配程度,那是否能在一次交互之后将剩余信息再度进行交互呢,基于这一思路,他们最终做出了一个深度匹配网。该模型目前也在标准数据集上是保持着最好的效果。
其次从生成模型上来看,检索模型在学习上的发展进程有 4 个维度:
-
从单轮生成模型到多轮生成模型
-
从通用回复到有信息内容的生成
-
从无法接入外部知识到能够自然地引入外部知识
-
从单一模态的生成到涵盖声音、视觉和语言的多模态的生成
武威指出,生成模型虽然发展时间不长,但是发展速度非常快,简单的生成模型就是基于注意力机制的端到序列到序列的模型,而考虑到这种模型非常容易生成非常频繁、没有信息量的回复,在 2017 年,他们就思考能否把话题内容引入到回复中,让生成的回复更有内容,因而当时就提了这样一个模型:

基本思想就是通过外部无监督训练话题模型,产生一些话题语料,然后在生成模型中通过一个话题注意力机制去遴选这样的话题语料,最后再在解码过程中单独做出一个话题的生成概率,让话题能够更容易出现在回复中。
在多轮生成上,研究团队也开展了很多研究工作,以今年在 EMNLP 上发表的一项工作为例,思想是通过一种无监督方式,对对话上下文进行补全,然后进行回复。

在基于知识、多模态的生成上,业界也有一些工作,比如基于网络把知识、情感多模态的内容引入到对话生成里面。
机器人可以从人类的对话中学习怎么去说话,那能否让机器人通过互相学习来共同进步呢?
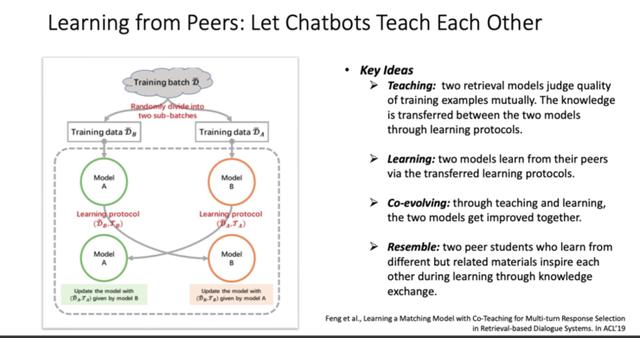
对此,微软小冰团队也做了一个简单的尝试,即让两个检索模型在训练过程中互为师生,互相交流。在每一次迭代中,一个模型都把它从数据中学到的知识传达给另外一个模型,同时又从另外一个模型中接触到它的知识,然后这两个模型互相学习,最终能够得到共同的进步。
下面三个图实际上是对应了学习的三种策略,包括动态的数据课程、动态的样本加权以及动态的最大间隔。

在每个策略中,红线左侧表示的是不需要算法进行训练的模型,红线右侧的算法名字叫 Co-teaching,即两个机器人互相教的一个过程。原本模型的训练效果是沿着蓝线继续走的,而使用了 Co-teaching 算法后,每一个模型的训练效果都得到了提升,也就是说着三个策略下所有的「教学相长」都是可以实现的。
2、自主管理能力
据武威介绍,自主管理在小冰里面一个最有趣的应用是在其第六代中发布的共感模型,共感模型的核心是通过对话策略对整个的对话流程进行把控,其背后实际上有两个模型:
-
回复生成模型,决定的是机器人说什么。
-
策略决定模型,决定的是机器人要怎么去说。

这两个模型结合在一起,让微软小冰从原来基于上下文直接产生回复的模式转变为:基于上下文进行决策,然后再根据决策来决定最终的回复。其中最大的灵活性就在于策略环节,其策略可以是一些意图、话题,也可以是一些情感等等,当然也可以是意图、话题、情感的组合,而这种策略组合,可以产生非常多样的、复杂的对话流程。对话机器人可以通过这种策略模型去管理整个复杂的对话。
与此同时,他也指出两个需要解决的问题:
-
问题一:给定一个策略,比如要表达的意图、情感、话题,模型能不能准确地生成把既定的策略表达出来的回复呢?与此同时,对话机器人不仅要表达这个策略,还要保证回复在上下文语境下是流畅的。
-
问题二:在有很多策略的时候,对话机器人怎么在一个对话流中组合这些策略呢?
对于第二个问题,常用办法标注一些数据,通过有监督的最大似然估计办法,来学习策略组合,也可以设定一些回报函数,通过增强学习的办法,来学习这种策略组合。
而对于第一个问题,小冰团队今年在 ACL 的一项工作中的思路是:不管意图也好、话题也好、情感也好、个性也好,其实都代表了回复的一种属性,那怎么能找到一个一般方法能够用来生成表达多属性的回复呢?基于这一思路,他们提出了 Meta-Word 的概念,而 Meta-Word 实际上代表了属性的组合,即在整个对话的流程中,可以通过变换属性组合生成各种各样的回复,进而组合成多种对话。他认为,有了这项工作后,对话的多样性或者说对话生成的多样性就不再是问题。

进一步,他指出这种模型至少有以下几个好处:
-
第一,可解释性很强,让开发者和终端用户能在对话机器人生成回复之前都能知道可能会得到哪些回复;
-
第二,可以把 Meta-Word 做成像一个接口一样,让工程师可以通过编辑这个接口来编辑 Meta-Word 中的属性,以及属性值去打造具有各种各样的风格、情感、话题、意图的各类对话机器人;
-
第三,Meta-Word 也提供了一种一般的解决方案,像现在的一些前沿研究方向,包括基于话题的对话生成、情感的对话生成、个性化的对话生成,都可以在这个框架下找到一个解决方案,不仅如此,这个方案还具有很好的扩展性,工程师们通过简单地增加、减少或者修改 Meta-Word 里面的属性值,就可以调整整个生成模型的效果。
3、知识联结能力
说到联结,无疑就涉及到多模态交互,而简单而言,多模态交互指的是输入可以是对话、语音、文本知识、多媒体,输出也可以是对话、语音、多媒体,在这个过程中很重要的问题是机器人如何能够把多模态的知识联结在一起进行消化、吸收,最终将其有机地组合起来变成一个输出。

这些多模态知识散落在各个地方,可能是在网上,也可能是在论坛中,那如何把这些散落在各个地方的知识联结在一起,然后以一种一致的方式通过对话机器人输出出来呢?
武威认为,一旦能够实现这一点,多模态交互也基本解决了。
三、小冰为什么要唱歌以及如何唱歌?
栾剑从更加轻松的视角,主要聚焦「为什么要让小冰唱歌?」、「如何让小冰唱歌?」两个方面介绍了小冰唱歌的技术进展。

“为什么要让小冰唱歌?”
针对这一被提问了多次的问题,栾剑做了解释:其实 2015 年,小冰就具备了语音聊天的功能,即除了文字回复以外,还能够通过声音来回复。而这个声音推出之初,受到了业界以及很多 C 端用户的广泛关注和好评。在当时这个声音听起来非常生动活泼,而且非常符合小冰的人设:一个精灵古怪的萌妹子。
后来在一年多的时间里,团队给这个声音加了很多技能,比如儿化音、中英文混杂的朗读、讲儿童故事、各种情感的表现,并随之意识到,语音合成领域一些主要的、大方向上的东西可能都已经解决了,而在类如分词、多音字、韵律等方面可能还是有一些瑕疵,而这可能需要通过语义理解长时间的积累和技术的发酵,来一步步地解决。
基于此,团队认为可能要寻找一个更有挑战性的课题来继续开展研究,而最终选择做唱歌主要有三个原因:
-
第一,唱歌的门槛比说话高。普通人都会说话,但是不是所有人都会唱歌的,更不是所有人都能唱得好听,与此同时,唱歌还有三个要素,即除了发音之外,它还有其它要素的要求,所以它在技术上有难点。
-
第二,唱歌在情感表达上更加丰富激烈一些。古人说「幸甚至哉,歌以咏志」,说明人们在特别高兴的时候就想唱歌,《诗经》说「心之忧矣,我歌且谣」,说明人类在悲伤的时候也喜欢唱歌。现在流行歌曲里面有很多情歌都是和失恋相关的,不管因为什么原因失恋,都能找到一首与其心境很对应的情歌。而除了高兴和悲伤之外,在一些比较重要、有纪念意义的场合,比如说今年是建国 70 周年,大家在那段时间可能都会被《我和我的祖国》这首歌单曲循环,所以歌曲是一种喜闻乐见的形式。
-
第三,唱歌是一种很重要的娱乐形式。随着《快乐女生》、《我是歌手》、《中国好声音》类似的节目红遍大江南北,他们认为唱歌应该是很有市场前景的研究方向。
决定让小冰唱歌后,具体该如何让小冰唱歌呢?
这就需要研究一下唱歌和说话有什么不同,因为唱歌的很多技术可以说是从语音合成沿袭过来的,经过分析,他们归纳出了三大要素:
-
第一,发音,因为唱歌不是哼歌,不是用「啊」或者「嗯」把这首歌哼出来就好了,吐字发音一定要清晰,这和说话是一样的。
-
第二,节拍,它是通过一种节奏的变化来表现艺术的形式,像我们普通的说唱,比如「一人我饮酒醉」这种说唱的形式,可能没有其它的旋律,主要就是靠节拍的组合来表达,节拍是唱歌里面非常重要的要素。
-
第三,旋律,每个字的音高会不太一样,如果音高唱错了、跑调了,这首歌肯定就没法听了。
这三大要素构成了唱歌最基本的元素,当然基于这三大要素也可以叠加很多的技巧,比如颤音、气音等。
那这三种要素通过什么方式让机器能够知道应该怎么唱歌呢?
-
第一,如果有人唱过这首歌,那机器就可以通过这个人唱的歌学习这首歌应该是什么样子。
-
第二,通过曲谱的方式,可以是简谱也可以是五线谱,它们下面都有歌词,其中简谱则既有歌词,也有发音的元素以及节拍和音高。
而追溯到传统唱歌合成的方式,其主要包括两大类:

-
第一类:单元拼接的方式。
这种方式出现得比较早,基本思想是可以先建一个单元库,这些单元的含义在普通话中可以是声母和韵母,中文有 21 个声母,有 35 个韵母。如果不考虑声调的话,音节大概有 400 个左右,可以把这些单元分别找一个发音来录,比如说「a」这个发音,可以录不同长度、音高的「a」,以此去采集这样一个单元库。
创建好单元库以后,可以根据发音、目标时长和目标音高,从单元库里面去挑选一个最符合要求的单元,然后通过信号处理的方法去修改它的时长、音高,使得它能够完美匹配想要达到的效果,然后再把这些单元串起来进行单元拼接,得到最后的音频。
这个方法最大的优点是比较简便易行,而且音质基本可以保留在采集声音时的最佳音质,但是它也存在问题,其中最大的问题便是:因为单元采集的过程中,每个发音都是单独采集的,而在一串语流里面,单独的发音和在一串语流里面连续的发音之间的差别较大,所以用这种方法生成出来的歌会比较生硬一些,唱得不是那么自然,而且因为它完全是由单元拼接的,所以变化可能会相对少一些,字与字之间的过渡也不会很好。
-
第二类:参数合成的方法。
最早的参数合成就是隐马尔可夫模型,这个方法在语音行业里面已经被用了很多年。这种方法就不是建一个单元库了,而是将所有录音的数据都提取出声学参数,包括能量谱、时长、音高,然后去建一个模型,等到要合成的时候,就根据需要的发音在模型中国将这个声学参数预测出来,然后通过声学参数、声码器把音频的波形重构出来。
这种方式比较灵活,基本上可以视作把一个东西完全打碎之后再重新拼起来一样,所以它的变化很丰富,甚至可以创造一个从来不存在的声音,可以得到一些在训练集里面根本没有出现过的东西。但是它最大的缺陷就在于声码器,即将它变成了参数,然后参数再还原成声音的这个过程中会有音质的损失,所以它最大的缺陷就是音质上可能会比第一个方法更低。
据介绍,小冰一开始选择采用的就是第二种方式,因为团队认为第二种方式的前景更加广阔,因而后续的重点研究也集中在对第二种方式的提高上。
小冰最开始采用的模型就是从乐谱中把唱歌的三大要素采集出来之后,分别用三个模型对声谱参数、节奏序列、音高轨迹分别建模,这里用的是 DNN,也就是神经网络。然后把预测出来的参数通过声码器生成波形。

团队一开始采用最简单的模块化方式来做唱歌模型,但是随之发现了问题,即同样一个发音,比如「啊」这个发音,在高音和低音上的的音色会有比较明显的区别,这时如果都用同样的方式合成,可能会出现问题。对此,他们把节奏和音高的预测结果作为输入,传到声谱参数预测里,通过这种方式缓解了此问题。
进一步考虑到既然三个参数之间有很重要的耦合性,互相之间需要协调、同步预测,他们就干脆用一个模型同时预测这三个参数。在最新的模型里面,他们用到了很复杂的结构,包括全卷积神经网络、注意力以及残差连接等等,用这种方式生成出来的波形,它的自然度和流畅度会得到一个明显的提升。
一个好的模型,除了要在数据上取得成功,更关键的是它的适用性要比较强,目前小冰在任何一个声音、风格上,都能建模的比较好,并且取得比较好的效果。
而在数据上,正如深度学习之所以发展得这么好一大重要支撑便是数据一样,唱歌这项任务也需要数据,然而该任务上的数据采集还比较困难,因为相对于说话来说,清唱的数据非常少——绝大部分的数据是混杂着伴奏的音轨。
该如何去利用这种已有的混合了伴奏的数据进行很好的学习呢?这里其实提出来了三个问题:
-
第一,要把伴奏里人声部分的时间轴找到;
-
第二,能够准确找到每个发音的起始和结束时间;
-
第三,要把人声的音高轨迹提取出来。
如果这三点能做到的话,小冰就能从含有伴奏的音轨的数据里面学到旋律,进而丰富演唱风格。
针对如何在伴奏音频在如何更好地提取人声的音高,小冰团队也发表了一篇论文,在这里栾剑重点强调了论文实现了三点创新:

-
第一,模型的输入用的是原始波形,而不是常规的能量谱,这是因为提取音高时,模型主要是要检测周期性,所以它的相位信息是非常重要的,如果是能量谱的话,那这个相位就丢失了。
-
第二,模型采用全卷积网络 残差连接的网络结构,非常清晰、简洁;
-
第三,软分类标签,即要准确判断每个时刻音高对应的是 77 个钢琴键里面的哪一个键,传统的方式可能是硬标签,比如说就是学习的时候标注这个时刻对应的中音八度的那个键,但是只有那个键会标「1」,其它的地方都标「0」,实际上这个方法会有一个问题,就是忽略了检测结果和标准结果偏差一个键值或者偏差 10 个键值之间错误的程度的差别是很大的。
最后他总结到,接下来不管是在人工智能创造方面,还是唱歌的提高上,都要两条腿走路:一边要不断提高模型,一边要不断挖据更多的数据。如果在这两方面取得越来越多进展,小冰在人工智能创造和唱歌上的质量就会不断得到提高。
四、小冰造出惊人比喻句的背后又做了哪些技术探索?
最后,宋睿华再次上台介绍了小冰在人工智能创造上的另一种尝试——创造比喻。

她提到开始这项尝试的契机非常偶然:某次在跟学生聊天时,有一位同学提到网上有一种说法,即不管什么样句子,后面加一个「爱情也是这样的」都是说得通的。我就问他为什么,他举了个例子——「人有两条腿,爱情也是这样的」,在我思考原因之际,又有一个同学说「你的意思是爱情总会走吗?」另一位同学反驳到:「为什么不是爱情总会来呢?」这给我留下了非常深刻的印象。我们不妨将这种说法视为一种规则,爱情也是这样的一种规则。

确定这个研究课题后,研究团队首先要考虑的就是喻体,比方说把「爱情」比作什么,并且要求不要在人类已有的文章里去挖掘这种比喻句,而是要让小冰真正创造出人类不曾说过的比喻。
经过更加细致地分析这一问题后,他们发现,本体一般是比较抽象的,是难以理解的,比如说爱情,之所以在某句子后面加一个「爱情也是这样的」都能对,是因为「爱情」真的是太复杂了,人们没法抓住它,就会认为好像怎么样都是可以解释的。
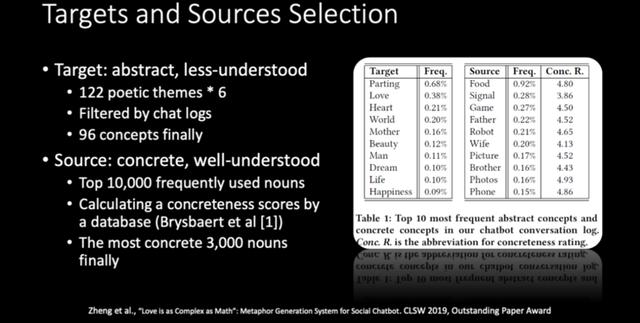
其中,他们也从诗歌中去找概念,发现诗里最多这种难以理解的抽象概念,因而从诗歌的主题中抽取了 120 个主题,扩展出 6 个词,经过日志过滤后找出小冰的用户也喜欢说的一些概念,最终找到了 96 个概念。
如下图中的表格所示,这张表的左边是小冰的用户中最常提到的 10 个抽象的概念,而找到的喻体实际上跟这几个概念的关联并不大,而且是一些非常具体、好理解的概念,经过日志挖掘以及计算某个词的具体程度进行排序等操作,最后找到了 3000 个名词。这张表的右边展示了可以作为喻体的候选的一些词,比如说食物、信号、游戏等等,这些都是比较具体的。
接下来如何解这个问题呢?
宋睿华接着介绍,假设有了一个本体「爱情」和一个喻体「中国足球」,他们用词向量来表达这两个看上去是毫不相关的概念,并将它们变成向量,经过降维之后,投影在二维空间上。
如下图所示,「爱情」的周围有婚姻、感情等词语,「中国足球」周围有开局、比赛等词语,二者与周围词语的关联性都非常高,说明了这种向量的表达效果非常好。
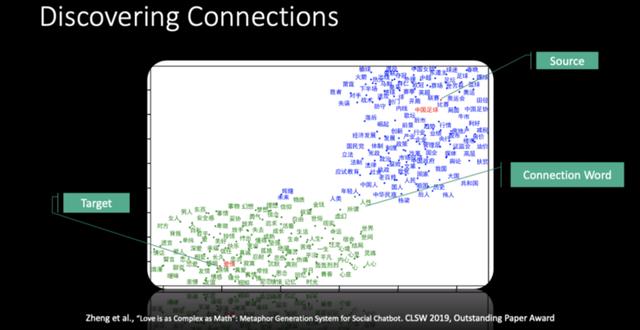
其中靠近一边的词其实并不是那么好用,而位于二者中间地带的词,即有一种平衡的词是最好用的,比如说「爱情像中国足球一样虚幻」,或者是「爱情像中国足球一样没有未来」这样的一些比喻会给人们一种新颖却不突兀的感觉。
下表展示的是团队当时用自动方法把和爱情不相关的一些概念挖掘出来的一些连接词,其中被标为绿色的部分是算法自动认为比较合适做连接词的一些词,比如说「爱情」和「股票」之间,算法自动发现了「贬值」、「博弈」;「爱情」和「数组」之间发现了「复杂」;「爱情」和「风水」之间是「迷信」;爱情和葡萄酒之间是「奢侈品」。

针对最后这一组的发现,宋睿华谈到,刚开始并不是很理解,直到所有的算法做完后得出了比喻句「爱情就像葡萄酒,对程序员来说都是奢侈品」他们才发现还挺有感觉的。
随着进一步研究,团队发现如果将这些连接词「分而治之」,它们可以有不同的词性,比如说形容词、名词和动词,各自处理方式是不太一样的。

其中形容词比较简单,比如「爱情」和「数学」之间可以找到一个形容词——「复杂」,如果用这个词来连接它们,就可以利用搜索引擎把「爱情」和「复杂」搜一下,再根据返回的结果知道「复杂」是否可以形容「数学」和「爱情」,从而判定「复杂」可以是合适的连接词。一旦确定,就可以用一个模板将它嵌进去:「爱情是复杂的,和数学一样」。而如果连接词是动词和名词,要比形容词难做一些。
在动词方面,比如本体是「灵魂」,喻体是「球迷」,「呐喊」是连接词,那怎样生成解释呢?方法是:首先把「灵魂」和「呐喊」作为联合的关键字放到搜索引擎里搜索,把前一万个结果甚至十万个结果拿回来,在这些结果的摘要中找出相关的短语,并且采用 NLP 分析找出这些句子的主谓结构,将主谓结构的词和「球迷」进行相似性匹配,看这些词在语义上是否和「球迷」有一些关联——越是关联,就越是可以连接它们。在实验中,排在前面的短语就是「在无声的呐喊」,由此在模板中形成的句子便是:「灵魂就像球迷一样,在无声的呐喊」。
在名词方面,方法和动词比较像,但在抽取结构时,即在搜索引擎前面一万条、十万条的摘要中,要抽取的是动宾结构的短语。比如说喻体和本体分别为「爱情」和「脂肪」,把「爱情」和连接词「积累」一起放入搜索引擎中搜索时,找到一个很好的短语——「是点点滴滴的积累」,它跟「脂肪」匹配得也不错,由此得出了一个比喻句:「爱情就像脂肪,是点点滴滴的积累」。
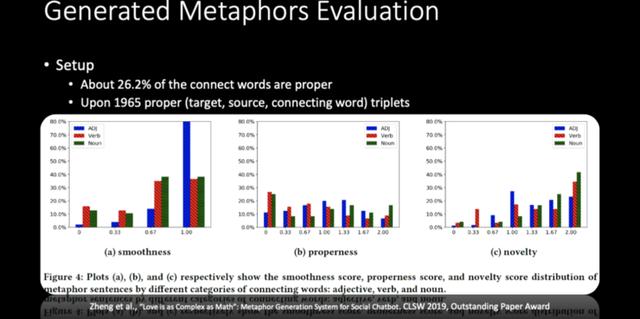
在评价方面,他们采取的方法是:
-
首先评价连接词是否合适,即让标注者去想像,如果「爱情」和「数学」用「复杂」来连接,是否能想像到一种联系,如果觉得可以,就可以打上标签「1」,如果不可以,就标成「0」。在这一步骤中,大概有 1/4 的连接词都是不错的。
-
接着,基于这些连接词,团队采用「分而治之」的方法造出了 1965 个比喻句,并从三个方面对这些句子进行了评价:第一,造出的这个比喻句是否通顺;第二,这个比喻是否恰当;第三,这个比喻是否新颖。
下图是小冰生成的比喻句的更多示例,有好也有坏:

随后团队又将这些比喻句放到了线上去检测一下用户对小冰创造出的比喻有什么反映,并测试了三种可能性:
-
第一,不要用比喻,就用陈述句,比如说「心灵是闪光的」。
-
第二,用一轮的比喻说出去,比如说「心灵像钻石一样闪光」。
-
第三,把对话拆成两轮,第一轮卖一个关子说「我听说心灵像钻石,你知道为什么吗?」然后用户说「为什么呀?」或者其他的,小冰就会说「因为它们都是闪光的」。

结果发现,比喻句果然是要比陈述句来的吸引人一些。其中,拆成两轮的对话中,用户更喜欢「先卖一个关子,然后再解释」的方式。
五、跨模态理解:如何让小冰看到文字就能想到画面?
本次分享的第三个技术板块——跨模态理解,依旧由宋睿华带来分享。

首先,她先一段文字中的三句话「北极熊爱吃海豹肉,而且爱吃新鲜的」、「北极熊常常蹑手蹑脚地接近猎物,像猫儿那样肚皮贴着地面,慢慢靠近,最后一跃而起,伸出爪子,露出獠牙」、「当北极熊悄然接近猎物,它有时会用爪子遮住自己的鼻头,这样一来,它就会变得更不易被察觉,很明显,北极熊是在遮掩自己的鼻子」出发,阐述了人在理解语言时,不仅会应用头脑中控制语言的部分,还会调动其他感官的事实。
想要让小冰更像人类,让她更好地理解对话和语言,是不是也可以模拟人类的能力,在短短的语言背后找到一些非常常识性的东西呢?

对此,宋睿华指出可以将其定义成这样一个问题:针对由 N 句话构成的一个故事,能否让机器生成 M 个对应着 N 句话的图片,即像人类听到这个故事后想象出来的场景一样。
而这种做法其实跟现在很多热门的课题都很相似,例如 Text-to-Image、Text-to-Video、Story-to-Image 等等,而这些方法总体而言,主要采用了两种方法:
-
第一,基于生成的方法,也就是 GANs;
-
第二,基于检索的方法,将文字和图片联合嵌入到一个空间中,以判定文字和哪一个图像比较接近、比较搭配。
在 ACM MM 这篇文章中,小冰团队受模拟体验假说的启发,考虑能不能让小冰也有自己的针对图像和文字的匹配的以往记忆,从而也可以在看到一个故事的句子后调出她以前的一些经验,然后模拟出现在的场景,甚至做一些替换,然后使得这个场景更加一致。
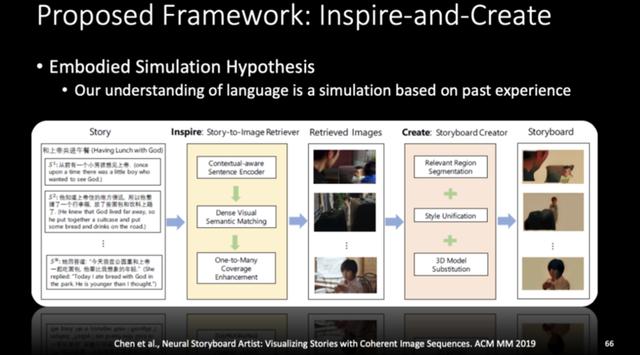
具体而言,即通过 Story-to-Image Retrieval 的方法来使驱动小冰「回忆」出这样一个图像。不过宋睿华也提到,在这一环节面临三个难点:
第一,对故事中的一句话做查询,实际上和 Image Search 的查询有一个很大的不同,即这句话是上下文高度相关的,不能单拿出来理解,而是一定要放在整个故事的语境中理解,对此,他们做了一个比较复杂的 Hierarchical Attentions,以更好地利用上下文语境。

第二,如果把故事画成一个故事板时,细节上哪怕有一点不对应,都会让人觉得怪怪的,比如说「这个狗和我一起玩网球」,如果得到的图像是「狗在玩飞盘」就会让人感觉有点奇怪,因而做匹配时要非常严谨。

第三,一句话有时候信息量很大,或者图片库并没有那么凑巧刚好有一幅图可以展示出所有的信息点,这时候人类艺术家可能会同时用几幅图来展示这一句话,但是数据库中,用来做训练的数据都是一个接一个的,并不存在这样的数据。

此外,这项任务高度依赖于图片库中到底有什么,所以他们提出了 One-to-Many 算法来解决这一问题,例如「有一个老太婆养着一只母鸡,它每天下一个黄灿灿的金蛋」这个句子会检索出一张有鸡的图片,而通过使用 One-to-Many 算法,就能够在得到的这张图前面再插入一张老奶奶的图片。
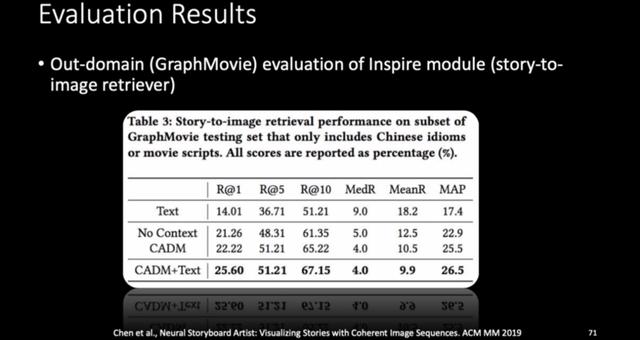
该算法分别在 In-domain(VIST)以及 Out-domain(GraphMovie)数据集上进行了测试,都获得了不错的效果和排名(如下两表所示)。

最后,宋睿华对于研讨会分享的三个重点环节进行了总结,并对小冰未来的发展进行了展望:
-
在对话方面,希望小冰能够实现更加自主的更新,更加自主地控制对话流;
-
在人工智能创造方面,希望小冰能够在才艺上实现更多的创新,其中要重点扩展学习资源以不断突破创新的边界;
-
在多模态上,希望小冰能够像人类一样去理解世界以及与人交互,其中既面临着数据问题,也面临着模态大跨度的挑战,这就需要大家研究出更好地融合多模态信息的方法。
「我们一开始推出小冰其实是希望能够做出一个对话框架,而这五年来小冰逐渐长成了一棵大树,在此过程中也在不断地督促我们去了解怎样用技术构建出实现像人一样的人工智能所必须的要素。时至今日,我们也希望未来她能够成为一个通用平台,去帮助研究者和厂商们开发出各种各样的 AI,并最终形成一片 AI 森林。我们将这样的 AI 平台称为 AI beings。」宋睿华用这段话为本次研讨会的分享划上了一个圆满的句号。
雷锋网 AI 科技评论报道。
雷锋网年度评选——寻找19大行业的最佳AI落地实践
创立于2017年的「AI最佳掘金案例年度榜单」,是业内首个人工智能商业案例评选活动。雷锋网从商用维度出发,寻找人工智能在各个行业的最佳落地实践。
第三届评选已正式启动,关注微信公众号“雷锋网”,回复关键词“榜单”参与报名。详情可咨询xqxq_xq

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






