比较一下现有的内存管理分配方案(自主管理内存分配)
你的留言,是我坚持分享的动力。如果你有任何疑问,可以点击关注,点赞、留言提问。
Go语言运行时runtime,自主管理内存。
内存分配模型基于gcmalloc,Tcmalloc是Google gperftools里的组件之一。全名是 thread cache malloc(线程缓存分配器),其内存管理分为线程内存和中央堆两部分。在并行程序下分配小对象(<=32k)的效率很高。
Tcmalloc核心思想是把内存分成多级来降低锁的粒度。每个线程都有一个cache,用于无锁分配小对象,当内存不足分配小对象,就去central申请,再不足就去heap申请,heap最终是向操作系统申请。
这样的分配模型,维护一个用户态的内存池,不仅提高了在频繁分配、释放的效率,而且有效地减少了内存碎片。
Go在程序启动时,会向操作系统申请一段连续的内存,切成小块后自己进行管理。
申请到的内存块被分成三个区域,在64位上分别是512MB,16GB,512GB大小。

这里只是内存虚拟地址空间限制,并不是golang内存最大就是512GB.
只是有个比例关系:
spans区域,一个指针大小(8byte)对应arena的一个page(8KB),倍数时1024 bitmap区域,一个字节(8Byte)对应arena的32Bytes,倍数时32
1、内存管理单元
- arena区域就是所谓的堆区,Go动态分配的内存都在这个区域,它把内存分割成8KB大小的页,这些页组合起来称为mspan
- bitmap区域标识arena区域哪些地址保存了对象,并用4bit标志位标识对象是否包含指针、GC标记信息。bitmap中一个byte大小的内存对应arena区域中4个指针大小(指针大小为8B),bitmap区域的大小是heapArenaBytes/(sys.PtrSize*8/2)=heapArenaBytes/(4*8B)
- spans区域存放mspan的指针,每个指针对应一页,所以spans区域的大小是heapArenaBytes / pageSize=heapArenaBytes / 8KB
mspan:GO中内存管理的基本单元,是由一片连续的8KB的页组成的大块内存。
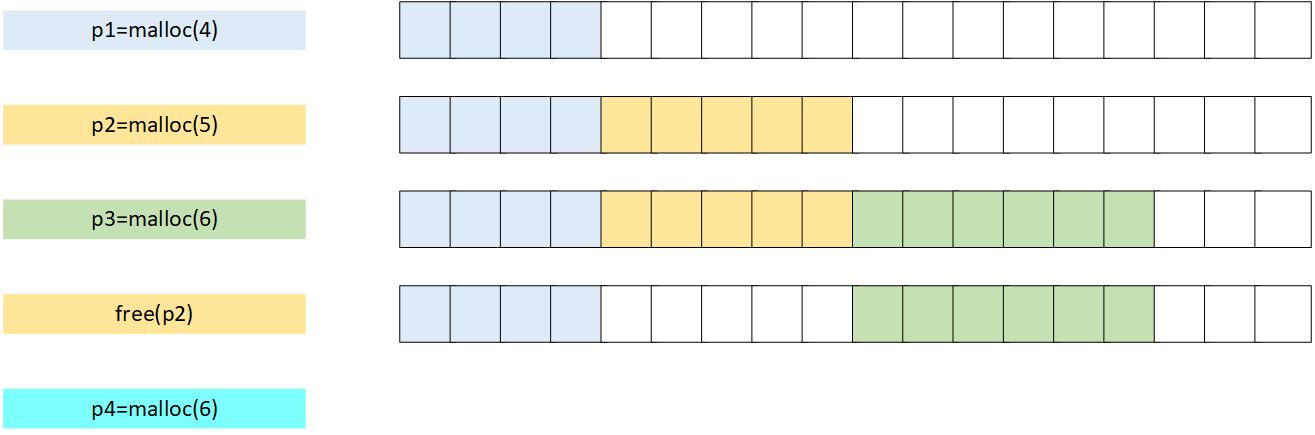
我们先看看一般情况下的对象和内存是如何分配的
此时,如果再分配"p4"时,是不是内存不足没法分配了,有很多碎片。
在Go中,是按需分配来处理这种问题。Go将内存块分为大小不同的67种,然后再把这67种大小的内存块,逐个分成小块,称为span(连续的span),这就是mspan
对象分配时,根据对象的大小选择大小相近的span,这样,碎片的问题就解决了。
// class bytes/obj bytes/span objects tail waste max waste // 1 8 8192 1024 0 87.50% // 2 16 8192 512 0 43.75% ...
- class:classID,每个span结构中都有一个classID,表示该span可处理的对象类型
- bytes/obj:该class代表对象的字节数
- bytes/span:每个span占用堆的字节数,也就是页数*页大小(8KB)
- objects:每个span可分配的对象个数,即 (bytes/span) / (bytes/obj)
- tail waste:浪费的外部碎片,比如1个page8KB,1个元素8byte,刚好对齐,如果一个元素是48byte,会余32byte
- max waste:最大的内部碎片率,每一个放进该span的对象大小都是最小值的情况,例如第一类class,最小对象是1byte,浪费7byte,最大碎片率为1-1/8=87.5%
以class为1的span为例,span中的元素大小是8byte,span本身一页是8KB,一共可以保存1024个对象。
如果有超过32KB的对象出现时,会从heap分配一个特殊的span,这个特殊的span对象类型是0,只包含一个大对象,span的大小由对象的大小决定。
const _NumSizeClasses = 67 var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}对于mspan来说,它的size class会决定它能分配到的页数
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}比如当我们要申请一个object大小为32B的mspan时,在class_to_size对应的索引是3,而3在class_to_allocnpages对应的页数就是1
type mspan struct { next *mspan prev *mspan list *mSpanList // For debugging. TODO: Remove. startAddr uintptr npages uintptr manualFreeList gclinkptr freeindex uintptr nelems uintptr allocCache uint64 allocBits *gcBits gcmarkBits *gcBits sweepgen uint32 divMul uint16 baseMask uint16 allocCount uint16 spanclass spanClass state mSpanStateBox needzero uint8 divShift uint8 divShift2 uint8 elemsize uintptr limit uintptr speciallock mutex specials *special }有几个比较重要的字段:
- next:链表后驱指针,用于将span链接
- prev:链表前驱指针,用于将span链接
- startAddr:起始地址,也就是所管理页的地址
- npages:管理的页数
- nelems:块个数,表示有多少个块可供分配
- allocBits:分配位图,每一位代表一个块是否已分配
- allocCount:已分配块的个数
- spanClass:class表中的classID,和size class关联
span class = size class * 2,这是因为每个size class有两个mspan,也就是有两个span class。其中一个分配给含有指针的对象,另一个分配给不含有指针的对象,不包含指针的对象不需要被GC扫描。
2、内存管理组件2.1、mcache
- elemsize:class表中的对象大小,也即块的大小
每个工作线程P都会绑定一个mcache,本地缓存可用的mspan资源,这样就可以直接给G分配,就不存在多个G竞争的情况。
2.2、mcentral
type mcache struct { tiny uintptr tinyoffset uintptr local_tinyallocs uintptr alloc [numSpanClasses]*mspan } numSpanClasses = _NumSizeClasses << 1为所有的mcache提供切分好的mspan资源。每个central保存一种特定大小的全局mspan列表,包括已分配出去的和未分配出去的。每个mcentral对应一种mspan,而mspan的重量导致它分割的object大小不同。当工作线程的mcache中没有合适的mspan时就会从mcentral获取。
type mcentral struct { lock mutex spanclass spanClass nonempty mSpanList empty mSpanList nmalloc uint64 }
- noempty:有空闲的spans
- empty:没有空闲的spans
- nmalloc:已累计分配的对象个数,原子写,在STW下读
分配一个span在mcache使用的流程
- 加锁
- 从nonempty链表中找到一个可用的mspan
- 将其从nonempty链表中删除
- 将取出的mspan插入到empty链表中
- 将mspan返回给工作线程
- 解锁
从mcache返还span流程
- 加锁
- 将mspan从empty链表中删除,将mspan插入到nonempty链表
c.empty.remove(s) c.nonempty.insert(s)2.3、mheap
- 解锁
代表Go程序持有的所有堆空间,使用全局对象mheap_来管理堆内存。
当mcentral没有空闲的mspan时,会向mspan申请。而mheap没有资源时,会向操作系统申请新内存。mheap主要用于大对象的内存分配,以及管理未切割的mspan,用于给mcentral切割成小对象。
type mheap struct { lock mutex allspans []*mspan central [67*2]struct { mcentral mcentral pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte } }可以看到mheap中含有所有规格的mcentral,当一个mcache从mcentral申请mspan时,只需要在它的mcentral里使用锁,并不会影响到其他mspan
2.4、fixalloc注意到mspan,mcache都是fixalloc来分配,这是一个free-list的块分配器,用来分配指定大小的块。
type fixalloc struct { size uintptr first func(arg, p unsafe.Pointer) // called first time p is returned arg unsafe.Pointer list *mlink chunk uintptr // use uintptr instead of unsafe.Pointer to avoid write barriers nchunk uint32 inuse uintptr // in-use bytes now stat *uint64 zero bool // zero allocations }分配时,如果list为空,就申请一整块内存chunk,每次按需分配,释放时再放回到list中。
因为size是固定的,所以没有内存碎片产生。
func (f *fixalloc) alloc() unsafe.Pointer { if f.size == 0 { print("runtime: use of FixAlloc_Alloc before FixAlloc_Init\n") throw("runtime: internal error") } if f.list != nil { v := unsafe.Pointer(f.list) f.list = f.list.next f.inuse = f.size if f.zero { memclrNoHeapPointers(v, f.size) } return v } if uintptr(f.nchunk) < f.size { f.chunk = uintptr(persistentalloc(_FixAllocChunk, 0, f.stat)) f.nchunk = _FixAllocChunk } v := unsafe.Pointer(f.chunk) if f.first != nil { f.first(f.arg, v) } f.chunk = f.chunk f.size f.nchunk -= uint32(f.size) f.inuse = f.size return v }3、内存分配流程
func (f *fixalloc) free(p unsafe.Pointer) { f.inuse -= f.size v := (*mlink)(p) v.next = f.list f.list = v }
- size>32KB,是大对象,直接从mheap中分配
- size<16B,使用mcache的tiny allocator分配,将小对象合并存储
- >=8B的对象,其内存地址按照8B对齐
- <8B且>=4B的对象,其内存地址按照4B对齐
- <4B且>1B的对象,其内存地址按照2B对齐
- <=1B的对象,无对齐要求
这样对齐会有部分内存浪费,但却能提升内存访问的效率。
4、总结
- size 在16B ~ 32k 间,计算需要使用的sizeClass,然后使用mcache中对应的sizeClass的块分配;如果mcache对应的sizeClass已无可用块,则向mcentral申请;如果mcentral也没有可用的块,则向mheap申请,使用BestFit找到最合适的mspan。如果超过申请大小则按需切分,返回用户需要的页面数,剩余的页面构成一个新的mspan,放回mheap的空闲链表;如果mheap也无可用span,则向操作系统申请一组新的页(至少1MB)
Go内存管理内存池的总体思路是,针对不同大小的对象,使用不同的内存结构分配内存。对操作系统申请的一整块连续地址,进行切分,多级缓存。对内存分配都按规定大小分配,减少内存碎片,也利于内存释放后,回收管理。
针对小对象(< 16byte),使用当前调度器(p)的mcache中的tiny allocator来分配,这样多个小对象可以放一起管理,避免内存浪费。
针对稍大对象(16byte ~ 32K),是用指定sizeClass取对应的块来分配。针对大对象(>32K),直接从heap中分配
其中mcache不足向mcentral中申请、mcentral不足向mheap申请,这些请求都是一次申请平摊了加锁(mcentral或mheap)的开销
mheap不足向操作系统申请一组页,则是平摊了操作系统分配的开销
,

免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






