mysql两表联查优化语句(SQL优化一)
一、概述
- from和join均是用于指定需要从哪些表查询数据,from可以是一个表或多个表,如果是多个表则是生成一个笛卡尔集,会涉及到大量数据。所以通常在涉及到多个表的查询时,通常通过join来拼接多个表。
- join主要是通过多个表之间的外键关联来进行拼接,注意用于拼接的列需要加上索引,如果没有则MySQL也会默认加上,不过前提是外键列和引用的主键列需要是相同的数据类型,如数字类型需要是相同的长度和均是有符号或无符号数,字符串类型长度可以不一样。以下分析涉及的表结构如下:用户表t_user和用户订单表t_order,在t_order表的user_id列是引用t_user的id列的外键。

二、用法分析
FROM
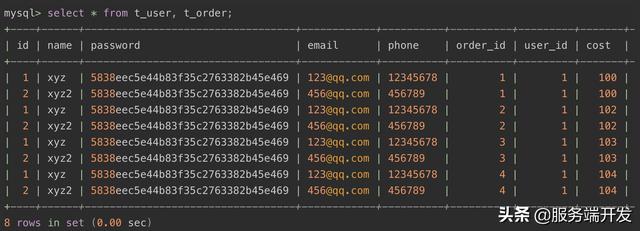
- 将多个表的所有数据行拼成笛卡尔集,故如果表的数据行多时,则数据量很多,造成巨大的磁盘、内存开销,当然查询速度也会很慢。
- 如下:xyz2这个用户其实是没有订单的,故from后面跟着这两个表只是简单的进行了:2 * 4=8行,其中用户表有2行数据,订单表有4行数据。
LEFT JOIN
- 包含左边表的所有行和右边的匹配行,如果左边表在右边表不存在关联数据,则只包含该行数据,而右边表相关的数据则是NULL,如下,相对于from,数据行变成了5行,即1*4 1=5

JOIN / INNER JOIN
- join是inner join的简写,只返回匹配表中匹配的数据行,如下:只返回4行数据。

RIGHT JOIN
- righ join与left join刚好相反,包含右边表的所有行,如果在左边表没有匹配,则相关字段为NULL,由于只包含4行数据且均与用户1关联,故返回4行。

JOIN多次
- 如果包含多个left join(或者多个right join,join等,顺序没有关系),则是前面的left join的结果作为左边,继续与后面的left join的表进行拼接,如下创建一个订单清单条目表t_order_item,并为订单1创建一个条目:

- 多个left join:返回5行数据,其中第一个left join返回5行数据,然后这5行数据在第二个left join与t_order_item拼表,由于只插入了一行t_order_item数据,故其他行对应的字段均为null。

- 先left join再right join:第一个left join返回5行数据,由于第二个right join的t_order_item表只包含一行数据,故最终只返回一行数据:

三、性能优化
优化方面主要是针对join的优化,因为join本身就是对from的一种优化了。而join的优化主要是从join的列的优化和join的表的左右顺序两个方面来分析。除此之外就是表的反范式设计。
join的列:外键索引
- 外键约束能够保证主表和关联表的数据完整性,但是更新时需要同步更新,所以操作会变慢,即会存在级联操作。
- 在关联表创建外键约束的语法如下:

- 在主表和关联表之间,关联表包含一个映射主表的主键(或者其他列,但是必须是包含索引的列,主表用于进行外键约束的列必须显式加上索引)的外键,主表的主键和关联表的外键需要是相同的数据类型,如数字类型,如果是字符串类型,字符串长度可以不同。该外键需要加上索引,对于关联表的外键列,如果没有显式加上索引,则MySQL会自动隐式加上索引。如果主表的列与关联表的外键列数据类型不一样,则无法添加外键约束,如下:t_order_item表的order_id为bigint(20),t_order表的order_id为int(11),则无法添加外键约束,改成int之后则可以正常添加,并且MySQL添加了一个索引:KEY order_reference (order_id)

inner join的表的左右顺序:小表驱动大表
- 在关联操作中,主表和关联表的顺序对性能影响很重要,特别对于JOIN/INNER JOIN这种匹配关联来说,因为LEFT/RIGHT JOIN一般是固定的不能调整顺序,而INNER JOIN由于是完全匹配,故主表和关联表的顺序可以调换。
- 一般的优化规则是:小表驱动大表,即数据行较少的表在左边,数据行较多的表在右边。
- 小表驱动大表的原理:在join当中,是使用左边表的每一个数据行去扫描右边的整个表的所有数据行,所以虽然总的匹配次数是相同的,但是如果左边表数据行很多,则需要加载右边的整个表很多次,使用小表驱动大表主要是要减少这个次数,即内循环次数,来提高性能。
- 针对以上案例,如果订单表t_order包含10000行,用户表t_user包含100行,则用户表t_user需要在左边,订单表t_order需要在右边,即:
select * from t_user join t_order on t_user.id = t_order.user_id;
- 小表驱动大表的设计只是我们编写SQL需要注意的,但是MySQL优化器不一定就完全按照这个顺序,MySQL是使用“小结果集”驱动“大结果集”的,即如果SQL语句还包含其他WHERE查询条件,排序ORDER BY等,则以上顺序可能还是反过来的,如果要强制该顺序,则可以使用STRAIGHT JOIN来替代INNER JOIN。具体可以参考这位博主的文章:MySQL优化的奇技淫巧之STRAIGHT_JOIN
反范式设计:单表冗余,不使用JOIN
- MySQL的三范式主要是从减少数据冗余的角度来规范表的设计,但是这个的历史背景是以前磁盘资源昂贵的角度出发的,在现代磁盘空间廉价的情况下,进行适当的数据冗余存储来避免拼表存在是一种以空间换时间的优化方法,所以进行适当的反范式设计也是一种优化思路。
- 不过反范式设计也要考虑数据的更新问题,因为同一个数据在两个或多个表中存储了,故在更新时也要同步更新。
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com






