开发正则表达式引擎(学用正则表达解析网页源码)
今天2022年8月15日是纪念日本投降的日子,也是我写学习笔记的第一天,可谓是喜上加囍。我想和大家分享一下我今天学习python网络爬虫的囧事以及从中得到的一些感悟,也算是对自己学习历程的一个记录吧。
今天,我试着用正则表达式解析网页源码,获取、清洗和打印数据,这个过程看似简单却不那么顺利。今天我主要爬取的是中国证券报网上的一些网站、标题和时间。跟着书依葫芦画瓢,在写好程序后,我就“shift enter”了一下,显示结果报错。一看错误提示是“IndexError: list index out of range”,索引超出了范围,如下图所示。

于是,跟着提示的指引,我回到程序去分析和查找原因,但奈何经验与能力有限,花了我半个多小时也没解决得了错误,其间还上网查了一下,也无济于事。心态逐渐开始炸裂了。但是,我也不是遇到点问题就轻言放弃的人,心里那股不解决问题、绝不罢休的劲儿,促使着我又去找方法解决。
只要思想不滑坡,方法总比困难多。我又回到了那本学习参考书,仔仔细细地与其比对看看哪里不一样,功夫不负有心人,我还真找到了一个差异点。这个差异点就是在用正则表达式来表示时间时少写了一个“.*?”,如下图所示。果然,该错误成功解除啦。但很不幸,又出现了一个新错误。

为什么这里需要写上“.*?”?我认为主要是“ ” 与“ ”之间存在空行(如下图所示),不加上“.*?”将空行忽略掉的话,re.findall()匹配的时候就会提取不到时间,从而导致时间列表为空,出现程序错误。这一问题实际上是暴露了我对正则表达的学习理解还不太好,需要多做练习来进一步加强认知、积累经验。

再来说一下这个新错误,错误如下图所示。该错误主要是split()函数的一个误用。误用在分割符里多加了一个空字符串,不符合split函数的语法使用要求而引起的报错。不过我很好奇,我参考的这本书也是这样写的,居然没有报错。看来知识掌握的不透,很容易就会被书误导呀。
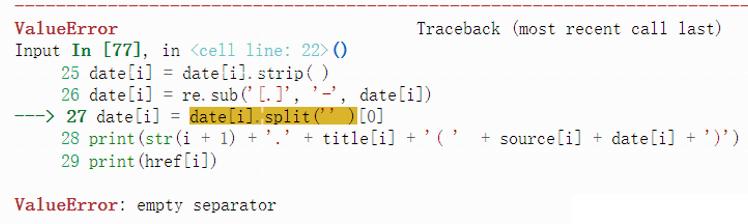
split()函数的误用,暴露了我对该知识点的欠缺。非常感谢这次报错,让我发现了知识盲点,有机会重新去加深学习、理解和应用。我重新把split()函数这个知识点总结在下面,加深理解和方便查看。
总结:split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
语法:str.split(str="",num=string.count(str))[n]
参数说明:
str:表示为分隔符,默认为空格,但是不能为空(’’)。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
num:表示分割次数。如果存在参数num,则仅分隔成 num 1 个子字符串,并且每一个子字符串可以赋给新的变量
[n]:表示选取第n个分片
,1、遇到问题不要退缩,方法总比困难多,坚持去寻找和思考,问题总会被解决,也终会有所收获。
2、知识是否学会,应用一下便见分晓。
3、实践才能出真知。唯有多动手操作和勤练习,才能发现自己的不足、加深对知识的理解与应用,进而提高解决问题的能力。
4、尽信书不如无书。不能无脑接受,盲目相信,需要有批判精神,多自我思考总结,才会有所进步。
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。文章投诉邮箱:anhduc.ph@yahoo.com